这篇文章上次修改于 300 天前,可能其部分内容已经发生变化,如有疑问可询问作者。
Chapter 25 Caching for Performance and Scale 第25章###缓存性能和规模
What the ancients called a clever fighter is one who not only wins, but excels in winning with ease.—Sun Tzu
古人所说的善战者,不仅能取胜,而且善于取胜。——《孙子》
What is the best way to handle large volumes of traffic? This is, of course, a trickquestion and at this point in the book hopefully you answered something like “estab-lish the right organization, implement the right processes, and follow the right archi-tectural principles to ensure the system can scale.” That’s a great answer, but wethink the absolute best way to handle large traffic volumes and user requests is to nothave to handle it at all. That probably sounds too good to be true but there is a wayto achieve this. Although not an actual architectural principle, the guideline of “don’thandle the traffic if you don’t have to” should be a mantra of your architects. Thekey to achieving this is through the pervasive use of something called a cache.
处理大量流量的最佳方法是什么?当然,这是一个棘手的问题,在本书的这一点上,希望您能回答诸如“建立正确的组织,实施正确的流程,并遵循正确的架构原则以确保系统可以扩展”之类的问题。这是一个很好的答案,但我们认为处理大流量和用户请求的绝对最佳方法是根本不需要处理它。这听起来好得令人难以置信,但有一种方法可以实现这一目标。虽然不是实际的建筑原则,但“如果不需要就不要处理交通”的指导方针应该是建筑师的口头禅。实现这一目标的关键是通过普遍使用称为缓存的东西。
In this chapter, we are going to cover caching and how it can be one of the besttools in your tool box for scalability. There are numerous forms of caching alreadypresent in our environments, ranging from CPU cache to DNS cache to Web browsercache. Covering all forms of caching is beyond the scope of this book, but this shouldnot dissuade you from pursuing a further study of all types of caching. Understand-ing these various caches will allow you to take better advantage of them in yourapplications and services. We are going to stick to three levels of caching that aremost under your control from an architectural perspective. These are caching at theobject, application, and content delivery network (CDN) levels. We will start with asimple primer on caching and then discuss each of these levels of caching in orderthat you understand their fundamental purposes and you begin considering how toleverage them for your system.
在本章中,我们将介绍缓存以及它如何成为可扩展性工具箱中最好的工具之一。我们的环境中已经存在多种形式的缓存,从 CPU 缓存到 DNS 缓存再到 Web 浏览器缓存。涵盖所有形式的缓存超出了本书的范围,但这不应该阻止您对所有类型的缓存进行进一步的研究。了解这些不同的缓存将使您能够在应用程序和服务中更好地利用它们。我们将坚持三个级别的缓存,从架构的角度来看,这三个级别最受您的控制。这些是对象、应用程序和内容交付网络 (CDN) 级别的缓存。我们将从有关缓存的简单入门开始,然后讨论每个级别的缓存,以便您了解它们的基本用途,并开始考虑如何在您的系统中利用它们。
Caching Defined 缓存定义
Cache is an allocation of memory by a device or application for the temporary stor-age of data that is likely to be used again. The term was first used in 1967 in the pub-lication IBM Systems Journal to label a memory improvement described as a high-speedbuffer.
缓存是设备或应用程序分配的内存,用于临时存储可能再次使用的数据。该术语于 1967 年在 IBM Systems Journal 出版物中首次使用,用于标记被描述为高速缓冲区的内存改进。
1 Don’t be confused by this point; caches and buffers have similar functionalitybut are different in purpose. Both buffers and caches are allocations of memory andhave similar structures. A buffer is memory that is used temporarily for accessrequirements, such as when data from disk must be moved into memory in order forprocessor instructions to utilize it. Buffers can also be used for performance, such aswhen reordering of data is required before writing to disk. A cache, on the otherhand, is used for the temporary storage of data that is likely to be accessed again,such as when the same data is read over and over without the data changing.
1 不要对这一点感到困惑;高速缓存和缓冲区具有类似的功能,但用途不同。缓冲区和高速缓存都是内存分配,并且具有相似的结构。缓冲区是临时用于满足访问要求的内存,例如当必须将磁盘中的数据移至内存以便处理器指令使用它时。缓冲区还可以用于提高性能,例如在写入磁盘之前需要对数据进行重新排序时。另一方面,缓存用于临时存储可能被再次访问的数据,例如当相同的数据被一遍又一遍地读取而数据没有改变时。
The structure of a cache is very similar to data structures, such as arrays with key-value pairs. In a cache, these tuples or entries are called tags and datum. The tag speci-fies the identity of the datum, and the datum is the actual data being stored. The datastored in the datum is an exact copy of the data stored in either a persistent storagedevice, such as a database or as calculated by an executable application. The tag is theidentifier that allows the requesting application or user to find the datum or determinethat it is not present in the cache. In Table 25.1, the cache has three items cached fromthe database, items with tags 3, 4, and 0. The cache can have its own index that couldbe based on recent usage or other indexing mechanism to speed up the reading of data.
缓存的结构与数据结构非常相似,例如具有键值对的数组。在缓存中,这些元组或条目称为标签和数据。标签指定数据的身份,数据是实际存储的数据。数据中存储的数据是存储在持久存储设备(例如数据库)中的数据的精确副本,或者是由可执行应用程序计算的数据的精确副本。标签是允许请求应用程序或用户查找数据或确定它不存在于缓存中的标识符。在表25.1中,缓存具有从数据库缓存的三个项目,标签为3、4和0的项目。缓存可以有自己的索引,该索引可以基于最近的使用情况或其他索引机制来加速数据的读取。
When the requesting application or user finds the data that it is asking for in thecache, this is called a cache-hit. When the data is not present in the cache, the appli-cation must go to the primary source to retrieve the data. Not finding the data in thecache is called a cache-miss. The number of hits to requests is called a cache ratio orhit ratio. This ratio is important to understand how effective the cache is being in off-setting load from the primary storage or executable. If the ratio is low, meaning thereare very few hits, there may be a serious degradation in performance due to the over-head of first checking a cache that does not have the data being requested.
当发出请求的应用程序或用户在缓存中找到其请求的数据时,这称为缓存命中。当缓存中不存在数据时,应用程序必须转到主要源来检索数据。在缓存中找不到数据称为缓存未命中。请求的命中数称为缓存比率或命中率。该比率对于了解缓存在抵消主存储或可执行文件负载方面的有效性非常重要。如果比率较低,意味着命中很少,则由于首先检查没有所请求数据的缓存的开销,性能可能会严重下降。
There are a couple methods of updating or refreshing data in a cache. The first isan offline process that periodically reads data from the primary source and com-pletely updates the datum in the cache. There are a variety of uses for such a refreshmethod. One of the most common situations when this method would be utilized areupon startup when the cache is empty and when the data is recalculated or restoredon a fixed schedule, such as through batch jobs.
有多种方法可以更新或刷新缓存中的数据。第一个是离线进程,定期从主源读取数据并完全更新缓存中的数据。这种刷新方法有多种用途。使用此方法的最常见情况之一是启动时缓存为空以及按固定计划(例如通过批处理作业)重新计算或恢复数据时。
Batch Cache Refresh 批量缓存刷新
As an example, let’s assume there is a batch job in the AllScale system called price_recalc.Part of AllScale’s human resources management (HRM) service is acting as a reseller of onlinetutorials provided by third parties. These tutorials are used by customers for training their staffor employees on tasks such as interviewing and performance counseling. This batch job calcu-lates the new price of a tutorial based on input from the vendors who sometimes change theirprices daily or monthly as they run specials on their products. Instead of running a pricing cal-culation on demand, it has been determined that based on the business rules, it is sufficient tocalculate this every 20 minutes.
举个例子,我们假设 AllScale 系统中有一个名为 Price_recalc 的批处理作业。AllScale 人力资源管理 (HRM) 服务的一部分是充当第三方提供的在线教程的经销商。客户使用这些教程来培训其员工或员工执行面试和绩效咨询等任务。此批处理作业根据供应商的输入计算教程的新价格,供应商有时会在对其产品进行特价时每天或每月更改价格。不再按需运行定价计算,而是根据业务规则确定每 20 分钟计算一次就足够了。
Although we have saved a lot of resources by not dynamically calculating the price, we stilldo not want the other services to request it continuously from the primary data source, thedatabase. Instead, we need a cache that stores the most frequently used items and prices. Inthis case, it does not make sense to dynamically refresh the cache because price_recalc runsevery 20 minutes. It makes much more sense to refresh the cache on the same schedule thatthe batch job runs.
尽管我们通过不动态计算价格节省了大量资源,但我们仍然不希望其他服务不断地从主数据源数据库请求它。相反,我们需要一个缓存来存储最常用的商品和价格。在这种情况下,动态刷新缓存没有意义,因为 Price_recalc 每 20 分钟运行一次。按照批处理作业运行的同一时间表刷新缓存更有意义。
Another method of updating or refreshing data in a cache is when a cache-missoccurs, the application or service requesting the data retrieves it from the primarydata source and then stores it in the cache. Assuming the cache is filled, meaning thatall memory allocated for the cache is full of datum, storing the newly retrieved datarequires some other piece of data to be ejected from the cache. The decision on whichpiece of data to eject is an entire field of study. The algorithms that are used to make thisdetermination are known as caching algorithms. One of the most common algorithmsused in caching is the least recently used (LRU) heuristic which removes the data thathas been accessed furthest in the past.
更新或刷新缓存中数据的另一种方法是,当发生缓存未命中时,请求数据的应用程序或服务从主数据源检索数据,然后将其存储在缓存中。假设缓存已满,意味着分配给缓存的所有内存都充满了数据,存储新检索的数据需要从缓存中弹出一些其他数据。决定剔除哪条数据是整个研究领域的事情。用于做出此确定的算法称为缓存算法。缓存中最常用的算法之一是最近最少使用 (LRU) 启发式算法,它会删除过去最远访问过的数据。
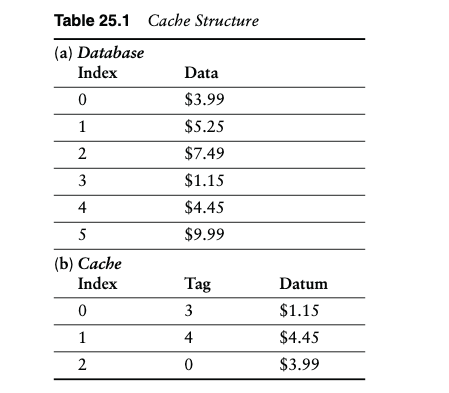
In Figure 25.1, the service has requested Item #2 (step 1), which is not present inthe cache and results in a cache-miss. The request is reiterated to the primary source,the database (step 2), where it is retrieved (step 3). The application then must updatethe cache (step 4), which it does, creating the new cache by ejecting the least recentlyused item (index 2 tag 0 datum $3.99). This is a sample of a cache-miss with updatebased on the least recently used algorithm.
在图 25.1 中,服务请求了项目 #2(步骤 1),该项目不存在于缓存中并导致缓存未命中。该请求被重复发送到主要来源数据库(步骤 2),并在其中检索该请求(步骤 3)。然后,应用程序必须更新缓存(步骤 4),通过弹出最近最少使用的项目(索引 2 标记 0 数据 $3.99)来创建新缓存。这是基于最近最少使用算法更新的缓存未命中示例。
Another algorithm is the exact opposite of LRU and is the most recently used(MRU). LRU is pretty commonsensical in that it generally makes sense that some-thing not being used should be expunged to make room for something needed rightnow. The MRU at first take seems nonsensical, but in fact it has a use. If the likeli-hood that a piece of data will be accessed again is most remote when it first has beenread, MRU works best. Let’s take our AllScale price_recalc batch job example again.This time, we don’t have room in our cache to store all the item prices, and the appli-cation accessing the price cache is a search engine bot. After the search engine bot hasaccessed the page to retrieve the price, it marks it off the list and is not likely to revisitthis page or price again until all others have been accessed. Here, the MRU algorithmis the most appropriate. As we mentioned earlier, there is an entire field of study ded-ssicated to caching algorithms. Some very sophisticated algorithms take factors, suchas differences in retrieval time, size of data, and user intent, into account when deter-mining what data stays and what data goes.
另一种算法与LRU完全相反,是最近使用的(MRU)。 LRU 是非常常识性的,因为通常应该删除未使用的东西来为现在需要的东西腾出空间。 MRU 乍一看似乎很无意义,但实际上它有用途。如果一条数据在第一次被读取时再次被访问的可能性最小,则 MRU 效果最佳。让我们再次以 AllScale Price_recalc 批处理作业为例。这一次,我们的缓存中没有空间来存储所有商品价格,并且访问价格缓存的应用程序是一个搜索引擎机器人。搜索引擎机器人访问该页面以检索价格后,会将其从列表中标记出来,并且在访问所有其他页面或价格之前不太可能再次访问此页面或价格。这里,MRU算法是最合适的。正如我们之前提到的,有一整个研究领域专门致力于缓存算法。一些非常复杂的算法在确定哪些数据保留和哪些数据离开时会考虑各种因素,例如检索时间的差异、数据大小和用户意图。
Thus far, we’ve focused on reading the data from the cache and we’ve assumedthat only reads were being performed on the data. What happens when that data ismanipulated and must be updated to ensure that if it is accessed again it is correct? Inthis case, we need to write data into the cache and ultimately get the data in the orig-inal data store updated as well. There are a variety of ways to achieve this. One of themost popular methods is a write-through policy. This is when the application manip-ulating the data writes it into the cache and into the data store. The application hasresponsibility for ensuring integrity between the stores. Another method is known aswrite-back, where the cache stores the updated data until a certain point in thefuture. In this case, the data is marked as dirty in order that it be identified andunderstood that it has changed from the primary data source. Often, the future eventthat causes the write-back is the data being ejected from the cache. The way thiswould work is the data is retrieved by a service and is changed. This changed data isplaced back into the cache and marked as dirty. When there is no longer room in thecache for this piece of data, it is expelled from the cache and written to the primarydata store. Obviously, this write-back method relieves the burden of writing to twolocations from the service, but as you can imagine, this increases the complexity ofmany situations, such as when shutting down or restoring the cache.
到目前为止,我们的重点是从缓存中读取数据,并且我们假设只对数据执行读取。当该数据被操纵并且必须更新以确保再次访问时它是正确的时,会发生什么?在这种情况下,我们需要将数据写入缓存并最终更新原始数据存储中的数据。有多种方法可以实现这一目标。最流行的方法之一是直写策略。这是操作数据的应用程序将其写入缓存和数据存储的时间。应用程序有责任确保商店之间的完整性。另一种方法称为回写,其中缓存将更新的数据存储到未来的某个时刻。在这种情况下,数据被标记为脏数据,以便识别并了解它已从主数据源更改。通常,导致写回的未来事件是数据从缓存中弹出。其工作方式是由服务检索数据并进行更改。这些更改的数据被放回到缓存中并标记为脏数据。当缓存中不再有空间容纳该数据时,会将其从缓存中删除并写入主数据存储。显然,这种回写方法减轻了从服务写入两个位置的负担,但正如您可以想象的那样,这增加了许多情况的复杂性,例如在关闭或恢复缓存时。
In this brief overview of caching, we have covered the tag-datum structure ofcaches; the concepts of cache-hit, cache-miss, and hit-ratio; the cache refreshingmethodologies of batch and upon cache-miss; caching algorithms such as LRU andMRU; and write-through versus write-back methods of manipulating the data storedin cache. Armed with this brief tutorial, we are going to begin our discussion of threetypes of caches: object, application, and CDN.
在缓存的简要概述中,我们介绍了缓存的标签数据结构;缓存命中、缓存未命中和命中率的概念;批量和缓存未命中时的缓存刷新方法; LRU和MRU等缓存算法;以及操作缓存中存储的数据的直写式与回写式方法。有了这个简短的教程,我们将开始讨论三种类型的缓存:对象、应用程序和 CDN。
Object Caches 对象缓存
Object caches are used to store objects for the application to be reused. These objectsusually come from either a database or have been generated by calculations ormanipulations of the application. The objects are almost always serialized objects,which are marshaled or deflated into a serialized format that minimizes the memoryfootprint. When retrieved, they must be inflated or unmarshalled to be converted intoits original data type. Marshalling is the process of transforming the memory repre-sentation of an object into a byte-stream or sequence of bytes in order that it bestored or transmitted. Unmarshalling is the process of decoding from the byte repre-sentation into the original object form. For object caches to be used, the applicationmust be aware of them and have implemented methods to manipulate the cache.
对象缓存用于存储供应用程序重用的对象。这些对象通常来自数据库或通过应用程序的计算或操作生成。这些对象几乎总是序列化对象,它们被编组或压缩为序列化格式,以最大限度地减少内存占用。检索时,它们必须被扩充或解组才能转换为其原始数据类型。编组是将对象的内存表示转换为字节流或字节序列以便存储或传输的过程。解组是将字节表示解码为原始对象形式的过程。对于要使用的对象缓存,应用程序必须了解它们并实现操作缓存的方法。
The basic methods of manipulation of a cache include a way to add data into thecache, a way to retrieve it, and a way to update the data. These are typically called setfor adding data, get for retrieving data, and replace for updating data. Depending onthe particular cache that is chosen, many programming languages already have built-in support for the most popular caches. Memcached is one of the most popularcaches in use today. It is a “high-performance, distributed memory object cachingsystem, generic in nature, but intended for use in speeding up dynamic web applica-tions by alleviating database load.”
操作高速缓存的基本方法包括将数据添加到高速缓存中的方法、检索数据的方法以及更新数据的方法。这些通常称为“set”(用于添加数据)、“get”(用于检索数据)和“replace”(用于更新数据)。根据所选的特定缓存,许多编程语言已经内置了对最流行缓存的支持。 Memcached 是当今最流行的缓存之一。它是一个“高性能、分布式内存对象缓存系统,本质上是通用的,但旨在通过减轻数据库负载来加速动态 Web 应用程序。
2 This particular cache is very fast-using non-blocking network input/output (I/O) and its own slab allocator to prevent memoryfragmentation guaranteeing allocations to be O(1) or able to be computed in con-stant time and thus not bound by the size of the data.
2 这个特定的缓存速度非常快 - 使用非阻塞网络输入/输出 (I/O) 及其自己的平板分配器来防止内存碎片,保证分配为 O(1) 或能够在恒定时间内计算,因此不会受数据大小的限制。
As indicated in the description of memcached, it is primarily designed to speed upWeb applications by alleviating requests to the database. This makes sense becausethe database is almost always the slowest retrieval device in the application tiers. Theoverhead of implementing ACID (Atomicity, Consistency, Isolation, and Durability)properties in a relational database management system is larger, especially when datahas to be written and read from disk. However, it is completely normal and advisablein some cases to use an object caching layer between other tiers of the system.
正如 memcached 的描述中所指出的,它的主要目的是通过减少对数据库的请求来加速 Web 应用程序。这是有道理的,因为数据库几乎总是应用程序层中最慢的检索设备。在关系数据库管理系统中实现 ACID(原子性、一致性、隔离性和持久性)属性的开销较大,尤其是当必须从磁盘写入和读取数据时。然而,在某些情况下,在系统的其他层之间使用对象缓存层是完全正常的并且是可取的。
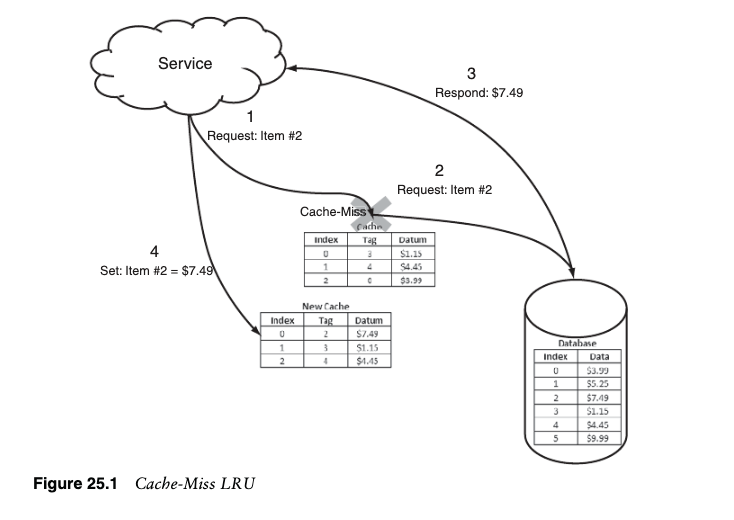
The way that an object cache fits into a typical two- or three-tier architecture is toplace it in front of the database tier. As indicated earlier, this is because it is usuallythe slowest overall performing tier and also it is often the most expensive tier toexpand. In Figure 25.2, there is a typical three-tier system stack depicted with a Webserver tier, an application server tier, and a database tier. Instead of just one objectcache, there are two. One cache is in between the application servers and the data-base, and one is between the Web servers and the application servers. This makessense if the application server is performing a great deal of calculations or manipula-tions that are cacheable. This prevents the application servers from having to con-stantly recalculate the same data and instead allows it to be cached and relieve theload on the application servers. Just as with the database, this caching layer can helpscale the tier without additional hardware. It is very likely that the objects beingcached are a subset of the total data set from either the database or the applicationservers. For example, it is possible that the application code on the Web servers makeuse of the cache for user permission objects but not for transaction amounts, becauseuser permissions are rarely changed and are accessed frequently; whereas a transac-tion amount is likely to be different with each transaction and accessed only once.
对象缓存适合典型的两层或三层体系结构的方式是将其放置在数据库层之前。如前所述,这是因为它通常是整体性能最慢的层,而且通常是扩展成本最高的层。在图 25.2 中,有一个典型的三层系统堆栈,包括 Web 服务器层、应用程序服务器层和数据库层。对象缓存不是只有一个,而是有两个。一个缓存位于应用程序服务器和数据库之间,一个缓存位于Web 服务器和应用程序服务器之间。如果应用程序服务器正在执行大量可缓存的计算或操作,那么这是有意义的。这可以防止应用程序服务器必须不断地重新计算相同的数据,而是允许对其进行缓存并减轻应用程序服务器上的负载。与数据库一样,该缓存层可以帮助扩展该层,而无需额外的硬件。被缓存的对象很可能是来自数据库或应用程序服务器的总数据集的子集。例如,Web服务器上的应用程序代码可能会使用用户权限对象的缓存,但不会使用交易金额的缓存,因为用户权限很少更改且访问频繁;而每笔交易的交易金额可能不同并且仅被访问一次。
ACID Properties of a Database 数据库的 ACID 属性
Atomicity, Consistency, Isolation, and Durability (ACID) are properties that a database manage-ment system employ to ensure that transactions are considered completely reliable.
原子性、一致性、隔离性和持久性 (ACID) 是数据库管理系统用来确保事务完全可靠的属性。
Atomicity is a property of a database management system to guarantee that all tasks of atransaction are completely performed or the entire transaction is rolled back. Failures of hard-ware or software will not result in half-completed transactions.
原子性是数据库管理系统的一个属性,用于保证事务的所有任务完全执行或整个事务回滚。硬件或软件故障不会导致交易半完成。
Consistency is the property that ensures that the database remains in a steady statebefore and after a transaction. If a transaction is successful, it moves the database from onestate to another that is “consistent” with the rules.
一致性是确保数据库在事务前后保持稳定状态的属性。如果事务成功,它将数据库从一个状态移动到另一个与规则“一致”的状态。
Isolation is the property that prevents another transaction from accessing a piece of datawhile another transaction is acting on it. Most database management systems use locks toensure this.
隔离性是当另一个事务正在处理数据时防止另一个事务访问该数据的属性。大多数数据库管理系统使用锁来确保这一点。
Durability is the property that after the system has marked the transaction as successful, itwill remain completed and not be rolled back. All consistency checks must be completed priorto the transaction being considered complete.
持久性是指系统将事务标记为成功后,事务将保持完成状态且不会回滚的属性。所有一致性检查必须在事务被视为完成之前完成。
DatabaseThe use of an object cache makes sense if you have a piece of data either in thedatabase or in the application server that gets accessed frequently but is updatedinfrequently. The database is the first place to look to offset load because it is gener-ally the slowest and most expensive of your application tiers. However, don’t stopthere; consider other tiers or pools of servers in your system for an object cache.Another very likely candidate for an object cache is as a centralized session manage-ment cache. If you make use of session data, we recommend you first eliminate ses-sion data as much as possible. Completely do away with sessions if you can as theyare costly within your infrastructure and architecture. If you cannot, we encourageyou to consider a centralized session management system that allows requests tocome to any Web server and the session be moved from one to another without dis-ruption. This way, you can make more efficient use of the Web servers through a loadbalanced solution, and in the event of a failure, users can be moved to another serverwith minimal disruption. Continue to look at your application for more candidatesfor object caches.
数据库如果数据库或应用程序服务器中有一段数据经常访问但不经常更新,则使用对象缓存是有意义的。数据库是第一个寻求抵消负载的地方,因为它通常是应用程序层中最慢且最昂贵的。然而,不要就此止步;考虑系统中的其他层或服务器池作为对象缓存。对象缓存的另一个很可能的候选者是集中式会话管理缓存。如果您使用会话数据,我们建议您首先尽可能地消除会话数据。如果可以的话,完全取消会话,因为它们在您的基础设施和架构中成本高昂。如果您做不到,我们鼓励您考虑一种集中式会话管理系统,该系统允许请求发送到任何 Web 服务器,并且会话可以在不中断的情况下从一个服务器转移到另一个服务器。这样,您可以通过负载平衡解决方案更有效地使用 Web 服务器,并且在发生故障时,可以将用户转移到另一台服务器,从而最大限度地减少中断。继续查看您的应用程序以寻找更多对象缓存候选者。
Application Caches 应用程序缓存
The next level of caching that we need to discuss is what we call application caching.There are two varieties of application caching: proxy caching and reverse proxy cach-ing. Before we dive into the details of each, let’s cover the concepts behind applica-tion caching in general. The basic premise is that you want to either speed upperceived performance or minimize the resources used. What do we mean by speed-ing up perceived performance? End users interacting with a Web based application orservice don’t care how fast the Web server actually is returning their request or howmany requests per second each server can handle. All end users care about is how fastthe application appears to respond in their browser. The use of smoke and mirrors isnot only allowed but encouraged if it doesn’t degrade the experience and improves per-formance. The smoke and mirror that people use is known as application caching. Thesame logic is applied to minimizing resources utilized. As long as end users have thesame experience, they don’t care if you utilize 100% of the available system resourcesor if you utilize 1%; they just want the pages to load quickly and accurately.
我们需要讨论的下一个级别的缓存是我们所说的应用程序缓存。应用程序缓存有两种类型:代理缓存和反向代理缓存。在我们深入研究每个细节之前,让我们先介绍一下应用程序缓存背后的一般概念。基本前提是您希望提高性能或最大限度地减少所使用的资源。加快感知性能是什么意思?与基于 Web 的应用程序或服务交互的最终用户并不关心 Web 服务器实际返回其请求的速度或每个服务器每秒可以处理多少个请求。所有最终用户关心的是应用程序在浏览器中的响应速度。如果不降低体验并提高性能,使用烟雾和镜子不仅是允许的,而且是鼓励的。人们使用的烟雾和镜子被称为应用程序缓存。应用相同的逻辑来最小化所使用的资源。只要最终用户具有相同的体验,他们就不会关心你是否利用了 100% 的可用系统资源,还是利用了 1%;他们只是希望页面能够快速准确地加载。
Proxy Caches 代理缓存
How do you speed up response time and minimize resource utilization? The way toachieve this is not to have the application or Web servers actually handle the requests.Let’s start out by looking at proxy caches. These types of caches are usually imple-mented by Internet service providers, universities, schools, or corporations. Theterms forward proxy cache or proxy server are sometimes used to be more descrip-tive. The idea is that instead of the Internet service provider (ISP) having to transmitan end user’s request through its network to a peer network to a server for the URLrequested, the ISP can proxy these requests and return them from a cache withoutever going to the URL’s actual servers. Of course, this saves a lot of resources on theISP’s network from being used as well as speeds up the processing. The caching isdone without the end user knowing that it has occurred; to her, the return page looksand behaves as if the actual site had returned her request.
如何加快响应时间并最大限度地减少资源利用率?实现此目的的方法不是让应用程序或 Web 服务器实际处理请求。让我们从查看代理缓存开始。这些类型的缓存通常由 Internet 服务提供商、大学、学校或公司实施。术语“转发代理缓存”或“代理服务器”有时用于更具描述性。这个想法是,互联网服务提供商 (ISP) 不必通过其网络将最终用户的请求传输到对等网络以获取 URL 请求的服务器,ISP 可以代理这些请求并从缓存中返回它们,而无需访问 URL实际的服务器。当然,这可以节省 ISP 网络上的大量资源,并加快处理速度。缓存是在最终用户不知道的情况下完成的;对她来说,返回页面的外观和行为就像实际站点返回了她的请求一样。
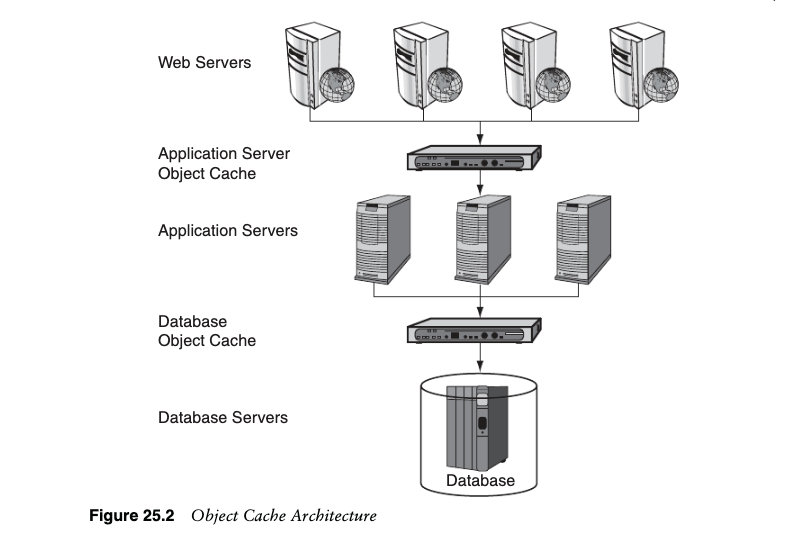
Figure 25.3 shows an implementation of a proxy cache at an ISP. The ISP hasimplemented a proxy cache that handles requests from a limited set of users for anunlimited number of applications or Web sites. The limited number of users can betheir entire subscriber population or more than likely subsets of subscribers who aregeographically collocated. All of these grouped users make requests through thecache; if the data is present, it is returned automatically; if the data is not present, theauthoritative site is requested and the data is potentially stored in cache in case someother subscriber requests it. The caching algorithm that determines whether a page orpiece of data gets updated/replaced can be customized for the subset of users that areusing the cache. It may make sense for caching to only occur if a minimum number ofrequests for that piece of data are seen over a period of time. This way, the mostrequested data is cached and sporadic requests for unique data does not replace themost viewed data.
图 25.3 显示了 ISP 中代理缓存的实现。 ISP 实施了代理缓存,用于处理有限用户对无限数量的应用程序或网站的请求。有限数量的用户可以是他们的整个订户群体或者很可能是地理上位于同一位置的订户子集。所有这些分组的用户都通过缓存发出请求;如果数据存在,则自动返回;如果数据不存在,则请求权威站点,并且数据可能存储在缓存中,以防其他订户请求它。可以为使用缓存的用户子集定制确定页面或数据是否被更新/替换的缓存算法。仅当在一段时间内看到对该数据块的最小数量的请求时,才进行缓存可能才有意义。这样,请求最多的数据就会被缓存,并且对唯一数据的零星请求不会取代查看次数最多的数据。
Database#####Reverse Proxy Cache
数据库#####反向代理缓存
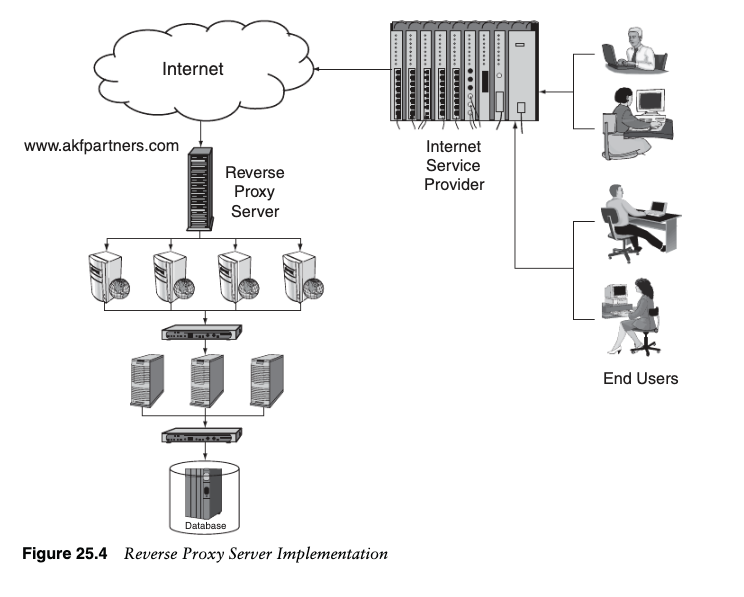
The other type of application caching is the reverse proxy cache. With proxy caching,the cache handles the requests from a limited number of users for a potentially unlim-ited number of sites or applications. A reverse proxy cache is opposite in that itcaches for an unlimited number of users or requestors and for a limited number ofsites or applications. Another term used for reverse proxy caches is gateway caches.These are most often implemented by system owners themselves in order to off loadthe requests on their Web servers. Instead of every single request coming to the Webserver, another tier is added for all or part of the set of available requests in front ofthe Web servers. Requests that are being cached can be returned immediately to therequestor without processing on the Web or application servers. The cached item canbe anything from entire static pages to static images to parts of dynamic pages. Theconfiguration of the specific application will determine what can be cached. Just becauseyour service or application is dynamic does not mean that you cannot take advantageof application caching. Even on the most dynamic sites, many items can be cached.
另一种类型的应用程序缓存是反向代理缓存。通过代理缓存,缓存可以处理来自有限数量的用户对可能无限数量的站点或应用程序的请求。反向代理缓存则相反,它为无限数量的用户或请求者以及有限数量的站点或应用程序进行缓存。用于反向代理缓存的另一个术语是网关缓存。这些缓存通常由系统所有者自己实现,以便减轻其 Web 服务器上的请求。不是每个请求都到达 Web 服务器,而是为 Web 服务器前面的所有或部分可用请求集添加了另一层。正在缓存的请求可以立即返回给请求者,无需在 Web 或应用程序服务器上进行处理。缓存的项目可以是任何内容,从整个静态页面到静态图像再到动态页面的部分。特定应用程序的配置将决定可以缓存的内容。仅仅因为您的服务或应用程序是动态的,并不意味着您不能利用应用程序缓存。即使在最动态的站点上,也可以缓存许多项目。
Figure 25.4 shows an implementation of a reverse proxy cache in front of a site’sWeb servers. The reverse proxy server handles some or all of the requests until theDatabasepages or data that is stored in them is out of date or until the server receives a requestfor which it does not have data (a cache miss). When this occurs, the request is passedthrough to a Web server to fulfill the request and to refresh the cache. Any users thathave access to make the requests for the application can be serviced by the cache.This is why a reverse proxy cache is considered the opposite of the proxy cache. Areverse proxy cache handles any number of users for a limited number of sites.
图 25.4 显示了站点 Web 服务器前面的反向代理缓存的实现。反向代理服务器处理部分或全部请求,直到数据库页或存储在其中的数据过期,或者直到服务器收到没有数据的请求(缓存未命中)。发生这种情况时,请求将传递到 Web 服务器以完成请求并刷新缓存。任何有权向应用程序发出请求的用户都可以通过缓存提供服务。这就是反向代理缓存被视为与代理缓存相反的原因。反向代理缓存可以处理有限数量站点的任意数量的用户。
HTML Headers and Meta Tags HTML 标头和元标记
Many developers believe that they can control the caching of a page by placing meta tags, suchasPragma: no-cache, in the element of the page. This is only partially true. Meta tags inthe HTML can be used to recommend how a page should be treated by browser cache, butmost browsers do not honor these tags. Because proxy caches rarely even inspect the HTML,they do not abide by these tags.
许多开发人员认为,他们可以通过在页面的 元素中放置元标记(例如 Pragma: no-cache)来控制页面的缓存。这只是部分正确。 HTML 中的元标记可用于建议浏览器缓存应如何处理页面,但大多数浏览器不支持这些标记。因为代理缓存很少检查 HTML,所以它们不遵守这些标记。
HTTP headers, on the other hand, give much more control over caching, especially withregard to proxy caches. These headers cannot be seen in the HTML and are generated by theWeb server. You can control them by configurations on the server. A typical HTTP responseheader could look like this:
另一方面,HTTP 标头对缓存提供了更多控制,尤其是代理缓存。这些标头在 HTML 中看不到,由 Web 服务器生成。您可以通过服务器上的配置来控制它们。典型的 HTTP 响应标头可能如下所示
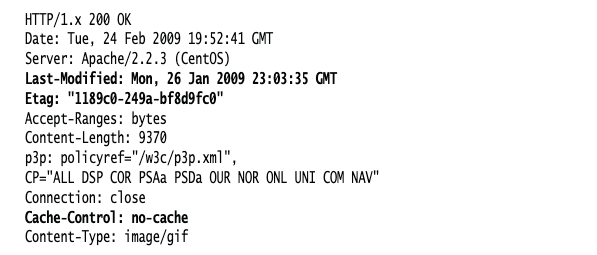
Notice the Cache-Control header identifying no-cache. In accordance with the Request ForComments (RFC) 2616 Section 14 defining the HTTP 1.1 protocol, this header must be obeyedby all caching mechanisms along the request/response chain.
请注意标识无缓存的 Cache-Control 标头。根据定义 HTTP 1.1 协议的 Request ForComments (RFC) 2616 第 14 节,请求/响应链上的所有缓存机制都必须遵守此标头。
Another header that is useful in managing caching is the Etag and Last-Modified tags.These are used to validate the freshness of the page by the caching mechanisms.
另一个在管理缓存中有用的标头是 Etag 和 Last-Modified 标记。这些标记用于通过缓存机制验证页面的新鲜度。
Understanding the request and response HTTP headers will allow you to more fully controlthe caching of your pages. This is an exercise that is well worth doing to ensure your pages arebeing handled properly by all the caching layers between your site and the end users.
了解请求和响应 HTTP 标头将使您能够更全面地控制页面的缓存。这是一个非常值得做的练习,可以确保站点和最终用户之间的所有缓存层正确处理您的页面。
Caching Software 缓存软件
Adequately covering even a portion of the caching software that is available bothfrom vendors and the open source communities is beyond the scope of this chapter.However, there are some points that should be covered to guide you in your searchfor the right caching software for your company’s needs. The first point is that youshould thoroughly understand your application and user demands. Running a sitewith multiple GB per second of traffic requires a much more robust and enterprise-class caching solution than does a small site serving 10MB per second of traffic. Areyou projecting a doubling of requests or users or traffic every month? Are you intro-ducing a brand-new video product line that is going to completely change that typeand need for caching? These are the types of questions you need to ask yourselfbefore you start shopping the Web for a solution, or you could easily fall into the trapof making your problem fit the solution.
充分涵盖供应商和开源社区提供的缓存软件的一部分超出了本章的范围。但是,应该涵盖一些要点,以指导您为您的公司寻找合适的缓存软件。需要。第一点是你应该彻底了解你的应用程序和用户需求。与每秒提供 10MB 流量的小型站点相比,运行每秒具有多个 GB 流量的站点需要更强大的企业级缓存解决方案。您是否预计每个月的请求、用户或流量都会增加一倍?您是否正在推出一个全新的视频产品线,它将彻底改变缓存的类型和需求?在开始在网上寻找解决方案之前,您需要问自己这些类型的问题,否则您很容易陷入让您的问题适合解决方案的陷阱。
The second point addresses the difference between add-on features and purpose-built solutions and is applicable to both hardware and software solutions. To under-stand the difference, let’s discuss the life cycle of a typical technology product. Aproduct usually starts out as a unique technology that sells and gains traction, or isadopted in the case of open source, as a result of its innovation and benefit within itstarget market. Over time, this product becomes less unique and eventually commod-itized, meaning everyone sells essentially the same product with the primary differen-tiation being price. High tech companies generally don’t like selling commodityproducts because the profit margins continue to get squeezed each year. And opensource communities are usually passionate about their software and want to see itcontinue to serve a purpose. The way to prevent the margin squeeze or the move intothe history books is to add features to the product. The more “value” the vendoradds the more the vendor can keep the price high. The problem with this is that theseadd-on features are almost always inferior to purpose-built products designed tosolve this one specific problem.
第二点解决了附加功能和专用解决方案之间的差异,并且适用于硬件和软件解决方案。为了理解其中的差异,我们来讨论一下典型技术产品的生命周期。产品通常以一种独特的技术开始销售并获得关注,或者在开源的情况下由于其创新和在目标市场中的利益而被采用。随着时间的推移,该产品变得不那么独特并最终商品化,这意味着每个人都销售基本上相同的产品,主要差异在于价格。高科技公司通常不喜欢销售商品,因为利润率逐年受到挤压。开源社区通常对他们的软件充满热情,并希望看到它继续服务于某个目的。防止利润挤压或被载入史册的方法是向产品添加功能。供应商增加的“价值”越多,供应商就越能保持高价。问题在于,这些附加功能几乎总是不如旨在解决这一特定问题的专用产品。
An example of this can be seen in comparing the performance of mod_cache inApache as an add-on feature with that of the purpose-built product memcached. Thisis not to belittle or take away anything from Apache, which is a very common opensource Web server that is developed and maintained by an open community of devel-opers known as the Apache Software Foundation. The application is available for awide variety of operating systems and has been the most popular Web server on theWorld Wide Web since 1996.The Apache module, mod_cache, implements an HTTPcontent cache that can be used to cache either local or proxied content. This moduleis one of hundreds available for Apache, and it absolutely serves a purpose, but whenyou need an object cache that is distributed and fault tolerant, there are better solu-tions such as memcached.
可以通过将 Apache 中作为附加功能的 mod_cache 的性能与专门构建的产品 memcached 的性能进行比较来看出这一点。这并不是要贬低或剥夺 Apache 的任何东西,它是一种非常常见的开源 Web 服务器,由称为 Apache 软件基金会的开放开发者社区开发和维护。该应用程序可用于多种操作系统,并且自 1996 年以来一直是万维网上最流行的 Web 服务器。Apache 模块 mod_cache 实现了 HTTP 内容缓存,可用于缓存本地或代理内容。该模块是 Apache 可用的数百个模块之一,它绝对有其用途,但是当您需要分布式且容错的对象缓存时,有更好的解决方案,例如 memcached。
Application caches are extensive in their types, implementations, and configura-tions. You should first become familiar with the current and future requirements ofyour application. Then, you should make sure you understand the differencesbetween add-on features and purpose-built solutions. With theses two pieces ofknowledge, you are ready to make a good decision when it comes to the ideal cachingsolution for your application.
应用程序缓存的类型、实现和配置都很广泛。您应该首先熟悉您的应用程序当前和未来的要求。然后,您应该确保您了解附加功能和专用解决方案之间的差异。有了这两条知识,您就可以在为您的应用程序选择理想的缓存解决方案时做出明智的决定。
Content Delivery Networks 内容交付网络
The last type of caching that we are going to cover in this chapter is the content deliv-ery networks (CDNs). This level of caching is used to push any of your content that iscacheable closer to the end user. The benefits of this include faster response time andfewer requests on your servers. The implementation of a CDN is varied but mostgenerically can be thought of as a network of gateway caches located in many differ-ent geographical areas and residing on many different Internet peering networks.Many CDNs use the Internet as their backbone and offer their servers to host yourcontent. Others, to provide higher availability and differentiate themselves, have builttheir own network point to point between their hosting locations.
本章要介绍的最后一种缓存类型是内容分发网络 (CDN)。此级别的缓存用于将任何可缓存的内容推送到更接近最终用户的位置。这样做的好处包括更快的响应时间和更少的服务器请求。 CDN 的实现多种多样,但最一般地可以被视为位于许多不同地理区域并驻留在许多不同 Internet 对等网络上的网关缓存网络。许多 CDN 使用 Internet 作为骨干网并提供服务器来托管你的内容。其他人为了提供更高的可用性并脱颖而出,在其托管位置之间建立了自己的点对点网络。
The advantages of CDNs are that they speed up response time, off load requestsfrom your application’s origin servers, and possibly lower delivery cost, although thisis not always the case. The concept is that the total capacity of the CDN’s strategi-cally placed servers can yield a higher capacity and availability than the networkbackbone. The reason for this is that if there is a network constraint or bottleneck,the total throughput is limited. When these are eliminated by placing CDN servers onthe edge of the network, the total capacity is increased and overall availabilityincreases as well. The way this works is that you place the CDN’s domain as an aliasfor your server by using a canonical name (CNAME) in your DNS entry. A sampleentry might look like this:
CDN 的优点是它们可以加快响应时间、减轻应用程序源服务器的请求,并可能降低交付成本,尽管情况并非总是如此。这个概念是,CDN 战略部署的服务器的总容量可以产生比网络主干网更高的容量和可用性。这样做的原因是,如果存在网络限制或瓶颈,总吞吐量就会受到限制。当通过将 CDN 服务器放置在网络边缘来消除这些问题时,总容量会增加,整体可用性也会提高。其工作原理是,您通过在 DNS 条目中使用规范名称 (CNAME) 将 CDN 的域放置为服务器的别名。示例条目可能如下所示

Here, we have our CDN, akfcdn.net, as an alias for our subdomain ads.akfpart-ners.com. The CDN alias could then be requested by the application, and as long asthe cache was valid, it would be served from the CDN and not our origin servers forour system. The CDN gateway servers would periodically make requests to ourapplication origin servers to ensure that the data, content, or Web pages that theyhave in cache is up-to-date. If the cache is out-of-date, the new content is distributedthrough the CDN to their edge servers.
在这里,我们有 CDN akfcdn.net 作为子域 ads.akfpart-ners.com 的别名。然后应用程序可以请求 CDN 别名,只要缓存有效,它就会从 CDN 提供服务,而不是我们系统的源服务器。 CDN 网关服务器会定期向我们的应用程序源服务器发出请求,以确保它们缓存中的数据、内容或网页是最新的。如果缓存已过时,新内容将通过 CDN 分发到其边缘服务器。
Today, CDNs offer a wide variety of services in addition to the primary service ofcaching your content closer to the end user. These services include DNS replacement,geo-load balancing, which is serving content to users based on their geographicallocation, and even application monitoring. All of these services are becoming morecommoditized as more providers enter into the market. In addition to commercialCDNs, there are more peer-to-peer P2P services being utilized for content delivery toend users to minimize the bandwidth and server utilization from providers.
如今,除了将内容缓存到更靠近最终用户的主要服务之外,CDN 还提供多种服务。这些服务包括 DNS 替换、地理负载平衡(根据用户的地理位置向用户提供内容),甚至应用程序监控。随着越来越多的提供商进入市场,所有这些服务都变得更加商品化。除了商业 CDN 之外,还有更多的点对点 P2P 服务用于向最终用户交付内容,以最大限度地减少提供商的带宽和服务器利用率。
Conclusion 结论
In this chapter, we started off by explaining the concept that the best way to handlelarge amounts of traffic is to avoid handling them in the first place. You can best dothis by utilizing caching. In this manner, caching can be one of the best tools in yourtool box for ensuring scalability. We identified that there are numerous forms ofcaching already present in our environments, ranging from CPU cache to DNS cacheto Web browser caches. In this chapter, we wanted to focus primarily on three levelsof caching that are most under your control from an architectural perspective. Theseare caching at the object, application, and content delivery network levels.
在本章中,我们首先解释了这样一个概念:处理大量流量的最佳方法是首先避免处理它们。您最好通过利用缓存来做到这一点。通过这种方式,缓存可以成为工具箱中确保可扩展性的最佳工具之一。我们发现我们的环境中已经存在多种形式的缓存,从 CPU 缓存到 DNS 缓存再到 Web 浏览器缓存。在本章中,我们主要关注从架构角度最受您控制的三个级别的缓存。这些是对象、应用程序和内容交付网络级别的缓存。
We started with a primer on caching in general and covered the tag-datum struc-ture of caches and how they are similar to buffers. We also covered the terminologyof cache-hit, cache-miss, and hit-ratio. We discussed the various refreshing methodol-ogies of batch and upon cache-miss as well as caching algorithms such as LRU andMRU. We finished the introductory section with a comparison of write-through ver-sus write-back methods of manipulating the data stored in cache.
我们从一般的缓存入门开始,介绍了缓存的标签数据结构以及它们与缓冲区的相似之处。我们还介绍了缓存命中、缓存未命中和命中率的术语。我们讨论了批处理和缓存未命中时的各种刷新方法以及缓存算法(例如 LRU 和 MRU)。我们通过比较操作缓存中存储的数据的直写式与回写式方法来完成介绍部分。
The first type of cache that we discussed was the object cache. These are cachesused to store objects for the application to be reused. Objects stored within the cacheusually come from either a database or have been generated by the application. Theseobjects are serialized to be placed into cache. For object caches to be used, the appli-cation must be aware of them and have implemented methods to manipulate thecache. The database is the first place to look to offset load through the use of anobject cache, because it is generally the slowest and most expensive of your applica-tion tiers; but the application tier is often a target as well.
我们讨论的第一种缓存类型是对象缓存。这些是缓存,用于存储供应用程序重用的对象。存储在缓存中的对象通常来自数据库或由应用程序生成。这些对象被序列化以放入缓存中。对于要使用的对象缓存,应用程序必须了解它们并实现操作缓存的方法。数据库是第一个通过使用对象缓存来抵消负载的地方,因为它通常是应用程序层中最慢且最昂贵的;但应用程序层通常也是目标。
The next type of cache that we discussed was the application cache. We coveredtwo varieties of application caching: proxy caching and reverse proxy caching. Thebasic premise of application caching is that you desire to speed up performance orminimize resources used. Proxy caching is used for a limited number of users request-ing an unlimited number of Web pages. This type of caching is often employed byInternet service providers or local area networks such as in schools and corporations.The other type of application caching we covered was the reverse proxy cache. Areverse proxy cache is used for an unlimited number of users or requestors and for alimited number of sites or applications. These are most often implemented by systemowners in order to off load the requests on their application origin servers.
我们讨论的下一种缓存是应用程序缓存。我们介绍了两种应用程序缓存:代理缓存和反向代理缓存。应用程序缓存的基本前提是您希望提高性能或最大限度地减少使用的资源。代理缓存用于请求无限数量网页的有限数量的用户。这种类型的缓存通常由 Internet 服务提供商或局域网(例如学校和公司)使用。我们介绍的另一种类型的应用程序缓存是反向代理缓存。反向代理缓存用于无限数量的用户或请求者以及有限数量的站点或应用程序。这些通常由系统所有者实施,以便卸载其应用程序源服务器上的请求。
The last type of caching that we covered was the content delivery networks(CDNs). The general principle of this level of caching is to push content that is cache-able closer to the end user. The benefits include faster response time and fewerrequests on the origin servers. CDNs are implemented as a network of gatewaycaches in different geographical areas utilizing different ISPs.
我们介绍的最后一种缓存类型是内容交付网络(CDN)。此级别缓存的一般原则是将可缓存的内容推送到更接近最终用户的位置。好处包括更快的响应时间和更少的源服务器请求。 CDN 是在不同地理区域利用不同 ISP 实现的网关缓存网络。
No matter what type of service or application you provide, it is important tounderstand the various methods of caching in order that you choose the right type ofcache. There is almost always a caching type or level that makes sense with Web 2.0and SaaS systems.
无论您提供什么类型的服务或应用程序,了解各种缓存方法都很重要,以便您选择正确的缓存类型。几乎总有一种缓存类型或级别对 Web 2.0 和 SaaS 系统有意义。
Key Points 关键点
The most easily scalable traffic is the type that never touches the applicationbecause it is serviced by cache.
最容易扩展的流量是从不接触应用程序的类型,因为它是由缓存提供服务的。
There are many layers to consider adding caching, each with pros and cons.
有很多层需要考虑添加缓存,每个层都有优点和缺点。
Buffers are similar to caches and can be used for performance, such as whenreordering of data is required before writing to disk.
缓冲区与缓存类似,可用于提高性能,例如在写入磁盘之前需要对数据进行重新排序时。
The structure of a cache is very similar to data structures, such as arrays withkey-value pairs. In a cache, these tuples or entries are called tags and datum.
缓存的结构与数据结构非常相似,例如具有键值对的数组。在缓存中,这些元组或条目称为标签和数据。
A cache is used for the temporary storage of data that is likely to be accessed again,such as when the same data is read over and over without the data changing.
缓存用于临时存储可能被再次访问的数据,例如当相同的数据被反复读取而数据没有改变时。
When the requesting application or user finds the data that it is asking for in thecache this is called a cache-hit.
当发出请求的应用程序或用户在缓存中找到其请求的数据时,这称为缓存命中。
When the data is not present in the cache, the application must go to the pri-mary source to retrieve the data. Not finding the data in the cache is called acache-miss.
当缓存中不存在数据时,应用程序必须转到主要源来检索数据。在缓存中找不到数据称为缓存未命中。
The number of hits to requests is called a cache ratio or hit ratio
请求的命中次数称为缓存比率或命中率
.
The use of an object cache makes sense if you have a piece of data either in thedatabase or in the application server that gets accessed frequently but is updatedinfrequently.
如果数据库或应用程序服务器中有一段数据被频繁访问但很少更新,则使用对象缓存是有意义的。
The database is the first place to look to offset load because it is generally theslowest and most expensive of your application tiers.
数据库是第一个寻求抵消负载的地方,因为它通常是应用程序层中最慢且最昂贵的。
A reverse proxy cache is opposite in that it caches for an unlimited number ofusers or requestors and for a limited number of sites or applications.
反向代理缓存则相反,它为无限数量的用户或请求者以及有限数量的站点或应用程序进行缓存。
Another term used for reverse proxy caches is gateway caches.
用于反向代理缓存的另一个术语是网关缓存。
Reverse proxy caches are most often implemented by system owners themselvesin order to off load the requests on their Web servers.
反向代理缓存通常由系统所有者自己实现,以便减轻其 Web 服务器上的请求。
Many CDNs use the Internet as their backbone and offer their servers to hostyour content.
许多 CDN 使用互联网作为骨干网,并提供服务器来托管您的内容。
Others, in order to provide higher availability and differentiate themselves, havebuilt their own network point to point between their hosting locations.
其他人为了提供更高的可用性并脱颖而出,在其托管位置之间建立了自己的点对点网络。
The advantages of CDNs are that they lower delivery cost, speed up responsetime, and off load requests from your application’s origin servers.
CDN 的优点在于它们可以降低交付成本、加快响应时间并从应用程序的源服务器卸载请求。
已有 4 条评论
你的文章让我感受到了生活的美好,谢谢! https://www.yonboz.com/video/88671.html
你的文章让我感受到了生活的美好,谢谢! https://www.yonboz.com/video/88671.html
你的才华让人惊叹,你是我的榜样。 http://www.55baobei.com/6cvAfHEoT0.html
你的文章内容非常精彩,让人回味无穷。 https://www.yonboz.com/video/83861.html