这篇文章上次修改于 296 天前,可能其部分内容已经发生变化,如有疑问可询问作者。
Chapter 31###Monitoring Applications监控应用
Gongs and drums, banners and flags, are means whereby the ears andeyes of the host may be focused on one particular point.—Sun Tzu
锣鼓、旗帜、旗帜,是使主人的耳朵和眼睛集中到某一特定点的手段。——孙子
No book on scale would be complete without addressing the unique monitoringneeds of systems that process a large volume of transactions. When you are small orgrowing slowly, you have plenty of time to identify and correct deficiencies in the sys-tems that cause customer experience problems. Furthermore, you aren’t really inter-ested in systems to help you identify scalability related issues early, as your slowgrowth obviates the need for such systems. However, when you are large or growingquickly or both, you have to be in front of your monitoring needs. You need to iden-tify scale bottlenecks quickly or suffer prolonged and painful outages. Further, smalldeltas in response time that might not be meaningful to customer experience todaymight end up being brownouts tomorrow when customer demand increases an addi-tional 10%. In this chapter, we will discuss the reason why many companies strugglein near perpetuity with monitoring their platforms and how to fix that struggle byemploying a framework for maturing monitoring over time. We will discuss whatkind of monitoring is valuable from a qualitative perspective and how that monitor-ing will aid our metrics and measurements from a quantitative perspective. Finally,we will address how monitoring fits into some of our processes including the head-room and capacity planning processes from Chapter 11, Determining Headroom forApplications, and incident and crisis management processes from Chapters 8, Man-aging Incidents and Problems, and 9, Managing Crisis and Escalations, respectively.
如果不解决处理大量交易的系统的独特监控需求,任何关于规模的书都是不完整的。当您规模较小或发展缓慢时,您有足够的时间来识别和纠正系统中导致客户体验问题的缺陷。此外,您对帮助您尽早识别可扩展性相关问题的系统并不真正感兴趣,因为您的缓慢增长消除了对此类系统的需求。然而,当您规模较大或增长迅速或两者兼而有之时,您必须满足监控需求。您需要快速识别规模瓶颈,否则会遭受长期且痛苦的停机。此外,当客户需求额外增加 10% 时,今天可能对客户体验没有意义的响应时间的小增量可能最终会在明天变得停电。在本章中,我们将讨论许多公司在监控其平台方面几乎永远陷入困境的原因,以及如何通过采用一个随着时间的推移而成熟的监控框架来解决这一问题。我们将从定性角度讨论什么样的监控是有价值的,以及这种监控如何从定量角度帮助我们的指标和测量。最后,我们将讨论监控如何融入我们的一些流程,包括第 11 章“确定应用程序的净空”中的净空和容量规划流程,以及第 8 章“管理事件和问题”和第 9 章中的事件和危机管理流程。分别管理危机和升级。
“How Come We Didn’t Catch That Earlier?” “我们怎么没早点发现呢?
If you’ve been around technical platforms, technology systems, back office IT sys-tems, or product platforms for more than a few days, you’ve likely heard questionslike, “How come we didn’t catch that earlier?” associated with the most recent fail-ure, incident, or crisis. If you’re as old as or older than we are, you’ve probably for-gotten just how many times you’ve heard that question or a similar one. The answeris usually pretty easy and it typically revolves around a service, component, applica-tion, or system not being monitored or not being monitored correctly. The answerusually ends with something like, “. . . and this problem will never happen again.”
如果您接触技术平台、技术系统、后台 IT 系统或产品平台超过几天,您可能听到过这样的问题:“我们为什么没有早点发现这一点?”与最近的失败、事件或危机有关。如果你和我们一样大或者比我们大,你可能已经忘记你听过这个问题或类似问题多少次了。答案通常非常简单,通常涉及未受监控或未正确监控的服务、组件、应用程序或系统。答案通常以“”结尾。 。 。并且这个问题永远不会再发生。
Even if that problem never happens again, and in our experience most often theproblem does happen again, a similar problem will very likely occur. The same ques-tion is asked, potentially a postmortem conducted, and actions are taken to monitorthe service correctly “again.”
即使该问题不再发生,并且根据我们的经验,该问题经常再次发生,也很可能会发生类似的问题。提出同样的问题,可能会进行事后分析,并采取措施“再次正确地监控服务”。
The question of “How come we didn’t catch it?” has a use, but it’s not nearly asvaluable as asking an even better question such as, “What in our process is flawedthat allowed us to launch the service without the appropriate monitoring to catchsuch an issue as this?” You may think that these two questions are similar, but theyare not. The first question, “How come we didn’t catch that earlier?” deals with thisissue, this point in time, and is marginally useful in helping drive the right behaviorsto resolve the incident we just had. The second question, on the other hand, addressesthe people and process that allowed the event you just had and every other event forwhich you did not have the appropriate monitoring. Think back, if you will, toChapter 8 wherein we discussed the relationship of incidents and problems. A prob-lem causes an incident and may be related to multiple incidents. Our first questionaddresses the incident, and not the problem. Our second question addresses the prob-lem. Both questions should probably be asked, but if you are going to ask and expectan answer (or a result) from only one question, we argue you should fix the problemrather than the incident.
“我们怎么没有抓住它?”的问题。有用途,但它的价值不如提出一个更好的问题,例如“我们的流程中有什么缺陷,使我们能够在没有适当监控来捕获此类问题的情况下启动服务?”您可能认为这两个问题很相似,但事实并非如此。第一个问题,“我们为什么没有早点发现这一点?”处理这个问题、这个时间点,对于帮助推动正确的行为来解决我们刚刚发生的事件有一点用处。另一方面,第二个问题涉及允许您刚刚发生的事件以及您没有适当监控的所有其他事件的人员和流程。如果你愿意的话,回想一下第八章,其中我们讨论了事件和问题的关系。一个问题会导致一个事件,并且可能与多个事件相关。我们的第一个问题针对的是事件,而不是问题。我们的第二个问题解决了这个问题。这两个问题可能都应该问,但如果您要问并期望仅从一个问题得到答案(或结果),我们认为您应该解决问题而不是事件。
We argue that the most common reason for not catching problems through moni-toring is that most systems aren’t designed to be monitored. Rather, most systems aredesigned and implemented and monitoring is an afterthought. Often, the teamresponsible for determining if the system or application is working properly had nohand in defining the behaviors of the system or in designing it. The most commonresult is that the monitoring performed on the application is developed by the teamleast capable of determining if the application is performing properly. This in turncauses critical success or failure indicators to be missed and very often means that themonitoring system is guaranteed to “fail” relative to internal expectations in identify-ing critical customer impact issues before they become crises.
我们认为,无法通过监控发现问题的最常见原因是大多数系统并不是为监控而设计的。相反,大多数系统都是设计和实施的,而监控则是事后才想到的。通常,负责确定系统或应用程序是否正常工作的团队无法定义系统的行为或设计系统。最常见的结果是,对应用程序执行的监控是由最不能够确定应用程序是否正常运行的团队开发的。这反过来会导致关键的成功或失败指标被遗漏,并且通常意味着监控系统在识别关键客户影响问题成为危机之前相对于内部预期肯定会“失败”。
Note that “designing to be monitored” means so much more than just understand-ing how to properly monitor a system for success and failure. Designing to be moni-tored is an approach wherein one builds monitoring into the application or systemrather than around it. It goes beyond logging that failures have occurred and towardidentifying themes of failure and potentially even performing automated escalation ofissues or concerns from an application perspective. A system that is designed to bemonitored might evaluate the response times of all of the services with which it inter-acts and alert someone when response times are out of the normal range for that timeof day. This same system might also evaluate the rate of error logging it performsover time and also alert the right people when that rate significantly changes or thecomposition of the errors changes. Both of these approaches might be accomplishedby employing a statistical process control chart that alerts when rates of errors orresponse times fall outside of N standard deviations from a mean calculated from thelast 30 similar days at that time of day. Here, a “similar” day would mean comparinga Monday to a Monday and a Saturday to a Saturday.
请注意,“设计为可监控的”不仅仅意味着理解如何正确监控系统的成功和失败。设计监控是一种将监控构建到应用程序或系统中而不是围绕它的方法。它不仅仅是记录已发生的故障,还包括识别故障主题,甚至可能从应用程序的角度自动升级问题或担忧。旨在监控的系统可能会评估与之交互的所有服务的响应时间,并在响应时间超出当天该时间的正常范围时向某人发出警报。该系统还可以评估其随时间执行的错误记录率,并在错误率显着变化或错误构成发生变化时向相关人员发出警报。这两种方法都可以通过采用统计过程控制图来实现,当错误率或响应时间超出从最近 30 个类似天的该时间计算得出的平均值的 N 个标准差时,该控制图会发出警报。在这里,“相似”的日子意味着将星期一与星期一以及星期六与星期六进行比较。
When companies have successfully implemented a Designed to Be Monitoredarchitectural principle, they begin asking a third question. This question is asked wellbefore the implementation of any of the systems and it usually takes place in theArchitectural Review Board (ARB) or the Joint Applications Design (JAD) meetings(see Chapters 14 and 13, respectively, for a definition of these meetings). The ques-tion is most often phrased as, “How do we know this system is functioning properlyand how do we know when it is starting to behave poorly?” Correct responses to thisthird question might include elements of our statistical process control solution men-tioned earlier. Any correct answer should include something other than that theapplication logs errors. Remember, we want the system to tell us when it is behavingnot only differently than expected, but when it is behaving differently than normal.These are really two very different things.
当公司成功实施“为监控而设计”的架构原则时,他们开始提出第三个问题。这个问题在任何系统实施之前就已提出,通常在架构审查委员会 (ARB) 或联合应用程序设计 (JAD) 会议上提出(有关这些会议的定义,分别参见第 14 章和第 13 章)。这个问题最常被表述为:“我们如何知道这个系统正在正常运行以及我们如何知道它何时开始表现不佳?”对第三个问题的正确回答可能包括前面提到的统计过程控制解决方案的要素。任何正确的答案都应该包括除应用程序日志错误之外的其他内容。请记住,我们希望系统不仅在其行为与预期不同时告诉我们,而且在其行为与正常情况不同时告诉我们。这实际上是两件非常不同的事情。
Note that the preceding is a significant change in approach compared to havingthe operations team develop a set of monitors for the application that consists oflooking for simple network management protocol (SNMP) traps or grepping throughlogs for strings that engineers indicate are of some importance. It also goes wellbeyond simply looking at CPU utilization, load, memory utilization, and so on.That’s not to say that all of those aren’t also important, but they won’t buy younearly as much as ensuring that the application is intelligent about its own health.
请注意,与让运营团队为应用程序开发一组监视器相比,前面的方法是一个重大变化,其中包括查找简单网络管理协议 (SNMP) 陷阱或在日志中查找工程师表示具有一定重要性的字符串。它也不仅仅是简单地查看 CPU 利用率、负载、内存利用率等。这并不是说所有这些都不重要,但它们不会像确保应用程序智能那样重要。它自己的健康。
The second most common reason for not catching problems through monitoring isthat we approach monitoring differently than we approach most of our other engi-neering endeavors. We very often don’t design our monitoring or we approach it in amethodical evolutionary fashion. Most of the time, we just apply effort to it and hopethat we get most of our needs covered. Often, we rely on production incidents andcrises to mature our monitoring, and this approach in turn creates a patchwork quiltwith no rhyme or reason. When asked for what we monitor, we will likely give all ofthe typical answers covering everything from application logs to system resource uti-lization, and we might even truthfully indicate that we also monitor for most of theindications of past major incidents. Rarely will we answer that our monitoring isengineered with the same rigors that we design and implement our platform or ser-vices. The following is a framework to resolve this second most common problem.
无法通过监控发现问题的第二个最常见原因是我们的监控方式与大多数其他工程工作的方式不同。我们经常不设计我们的监控,或者我们以一种有条不紊的进化方式来处理它。大多数时候,我们只是付出努力并希望能够满足我们的大部分需求。通常,我们依靠生产事件和危机来完善我们的监控,而这种方法反过来又创造了一个毫无规律或理由的拼凑被子。当被问及我们监控的内容时,我们可能会给出所有典型的答案,涵盖从应用程序日志到系统资源利用率的所有内容,我们甚至可能如实表示我们还监控过去重大事件的大多数迹象。我们很少会回答说,我们的监控与我们设计和实施平台或服务的严格程度相同。以下是解决第二个最常见问题的框架。
A Framework for Monitoring 监控框架
How often have you found yourself in a situation where, during a postmortem, youidentify that your monitoring system actually flagged the early indications of a poten-tial scalability or availability issue? Maybe space alarms were triggered on a databasethat went unanswered or potentially CPU utilization thresholds across several ser-vices were exceeded. Maybe you had response time monitoring enabled between ser-vices and saw a slow increase in the time for calls of a specific service over a numberof months. “How,” you might ask yourself, “did these go unnoticed?”
在事后分析过程中,您是否经常发现自己的监控系统实际上标记了潜在可扩展性或可用性问题的早期迹象?也许数据库触发了空间警报,但未得到答复,或者可能超过了多个服务的 CPU 使用率阈值。也许您在服务之间启用了响应时间监控,并发现特定服务的调用时间在几个月内缓慢增加。你可能会问自己:“这些怎么会被忽视呢?
Maybe you even voice your concerns to the team. A potential answer might bethat the monitoring system simply gives too many false positives (or false negatives)or that there is too much noise in the system. Maybe the head of the operations teameven indicates that she has been asking for months that they be given money toreplace the monitoring system or given the time and flexibility to reimplement thecurrent system. “If we only take some of the noise out of the system, my team cansleep better and address the real issues that we face,” she might say. We’ve heard thereasons for new and better monitoring systems time and again, and although they aresometimes valid, most often we believe they result in a destruction of shareholdervalue. The real issue isn’t typically that the monitoring system is not meeting theneeds of the company; it is that the approach to monitoring is all wrong. The teamvery likely has a good portion of the needs nailed, but it started at the wrong end ofthe monitoring needs spectrum.
也许您甚至向团队表达了您的担忧。一个可能的答案可能是监控系统给出了太多误报(或漏报),或者系统中存在太多噪音。也许运营团队的负责人甚至表示,她几个月来一直在要求给他们资金来更换监控系统,或者给他们时间和灵活性来重新实施当前系统。 “如果我们只消除系统中的一些噪音,我的团队就可以睡得更好,并解决我们面临的真正问题,”她可能会说。我们一次又一次地听到需要新的、更好的监控系统的理由,尽管它们有时是有效的,但大多数情况下我们认为它们会导致股东价值的破坏。真正的问题通常不是监控系统无法满足公司的需求;而是监控系统无法满足公司的需求。问题在于监控的方法是错误的。该团队很可能已经确定了很大一部分需求,但它从监控需求范围的错误一端开始。
Although having Design to Be Monitored as an architectural principle is necessaryto resolve the recurring “Why didn’t we catch that earlier?” problem, it is not suffi-cient to solve all of our monitoring problems or all of our monitoring needs. We needto plan our monitoring and expect that we are going to evolve it over time. Just asAgile software development methods attempt to solve the problem associated withnot knowing all of your requirements before you develop a piece of software, so mustwe have an agile and evolutionary development mindset for our monitoring plat-forms and systems. This evolutionary method we propose answers three questions,with each question supporting the delineation incidents and problems that we identi-fied in Chapter 8.
尽管将要监控的设计作为架构原则对于解决反复出现的“为什么我们不早点发现这一点?”是必要的。问题,并不足以解决我们所有的监控问题或我们所有的监控需求。我们需要规划我们的监控,并期望我们能够随着时间的推移不断改进它。正如敏捷软件开发方法试图解决在开发软件之前不了解所有需求所带来的问题一样,我们的监控平台和系统也必须具有敏捷和进化的开发思维。我们提出的这种进化方法回答了三个问题,每个问题都支持我们在第 8 章中确定的事件和问题的描述。
The first question that we ask in our evolutionary model for monitoring is, “Isthere a problem?” Specifically, we are interested in determining whether the system isnot behaving correctly and most often we are really asking if there is a problem thatcustomers can or will experience. Many companies in our experience completelybypass this very important question and immediately dive into an unguided explora-tion of the next question we should ask, “Where is the problem located?” or evenworse, “What is the problem?”
我们在监控进化模型中提出的第一个问题是“有问题吗?”具体来说,我们有兴趣确定系统是否运行不正确,并且大多数情况下我们实际上是在询问客户是否可能或将会遇到问题。根据我们的经验,许多公司完全绕过了这个非常重要的问题,并立即深入探索我们应该问的下一个问题:“问题出在哪里?”或者更糟糕的是,“问题出在哪里?
In monitoring, bypassing “Is there a problem?” or more aptly, “What is the prob-lem that customers are experiencing?” assumes that you know for all cases what sys-tems will cause what problems and in what way. Unfortunately, this isn’t often thecase. In fact, we’ve had many clients waste literally man years of effort in trying toidentify the source of the problem without ever truly understanding what the prob-lem is. You have likely taken classes in which the notion of framing the problem ordeveloping the right question has been drilled into you. The idea is that you shouldnot start down the road of attempting to solve a problem or perform analysis beforeyou understand what exactly you are trying to solve. Other examples where this holdstrue are in the etiquette of meetings, where the meeting typically has a title and purpose,and in product marketing, where we first frame the target audience before attemptingto develop a product or service for that market’s needs. The same holds true withmonitoring systems and applications: We must know that there is a problem and howthe problem manifests itself if we are to be effective in identifying its source.
在监控中,绕过“有问题吗?”或者更恰当地说,“客户遇到的问题是什么?”假设您知道所有情况下哪些系统将以何种方式导致哪些问题。不幸的是,这种情况并不常见。事实上,我们有许多客户浪费了数年的努力来试图找出问题的根源,却从未真正理解问题是什么。您可能参加过一些课程,在这些课程中,您已经被灌输了构建问题或提出正确问题的概念。这个想法是,在了解您到底要解决什么问题之前,您不应该开始尝试解决问题或进行分析。其他适用这一点的例子包括会议礼仪,会议通常有标题和目的,以及产品营销,在尝试开发满足市场需求的产品或服务之前,我们首先确定目标受众。对于监控系统和应用程序来说也是如此:如果我们要有效地识别问题的根源,我们就必须知道存在问题以及问题是如何表现出来的。
Not building systems that first answer, “Is there a problem?” result in two addi-tional issues. The first issue is that our teams often chase false positives and then veryoften start to react to the constant alerts as noise. This makes our system less usefulover time as we stop investigating alerts that may turn out to be rather large prob-lems. We ultimately become conditioned to ignore alerts, regardless of whether theyare important.
不构建首先回答“有问题吗?”的系统。导致两个额外的问题。第一个问题是,我们的团队经常追逐误报,然后经常开始将持续的警报视为噪音。随着时间的推移,这使得我们的系统不再那么有用,因为我们停止调查可能会成为相当大问题的警报。我们最终会习惯于忽略警报,无论它们是否重要。
This conditioning results in a second and more egregious issue: Customers inform-ing us of our problems. Customers don’t want to be the one telling you about prob-lems or issues with your systems or products, especially if you are a hosted solutionsuch as an application service provider (ASP) or Software as a Service (SaaS) pro-vider. Customers expect that at best they are telling you something that you alreadyknow and that you are deep in the process of fixing whatever issue they are experi-encing. Unfortunately, because we do not spend time building systems to tell us thatthere is a problem, often the irate customer is the first indication that we have a prob-lem. Systems that answer the question, “Is there a problem?” are very often customerfocused systems that interact with our platform as if they are our customer. They mayalso be diagnostic services built into our platform similar to the statistical processcontrol example given earlier.
这种调节导致了第二个更严重的问题:客户向我们通报我们的问题。客户不想告诉您系统或产品的问题,特别是如果您是托管解决方案,例如应用程序服务提供商 (ASP) 或软件即服务 (SaaS) 提供商。客户希望他们最多能告诉您一些您已经知道的事情,并且您正在深入解决他们遇到的任何问题。不幸的是,由于我们没有花时间构建系统来告诉我们存在问题,因此愤怒的客户通常是我们遇到问题的第一个迹象。回答“有问题吗?”的系统通常是以客户为中心的系统,它们与我们的平台进行交互,就好像他们是我们的客户一样。它们也可能是内置于我们平台中的诊断服务,类似于前面给出的统计过程控制示例。
The next question to answer in evolutionary fashion is, “Where is the problem?”We now have built a system that tells us definitively that we have a problem some-where in our system, ideally correlated with a single or a handful of business metrics.Now we need to isolate where the problem exists. These types of systems very oftenare broad category collection agents that give us indications of resource utilizationover time. Ideally, they are graphical in nature and maybe we are even applying ourneat little statistical process control chart trick. Maybe we even have a nice user inter-face that gives us a heat map indicating areas or sections of our system that are notperforming as we would expect. These types of systems are really meant to help usquickly identify where we should be applying our efforts in isolating what exactly theproblem is or what the root cause of our incident might be.
以进化方式回答的下一个问题是,“问题出在哪里?”我们现在已经构建了一个系统,可以明确地告诉我们系统中的某个地方存在问题,最好与单个或几个业务指标相关.现在我们需要隔离问题所在。这些类型的系统通常是广泛类别的收集代理,可以为我们提供随时间推移的资源利用率指示。理想情况下,它们本质上是图形化的,也许我们甚至正在应用我们巧妙的统计过程控制图技巧。也许我们甚至有一个很好的用户界面,它为我们提供了一个热图,指示我们系统中未达到预期性能的区域或部分。这些类型的系统实际上是为了帮助我们快速确定应该在哪里努力隔离问题到底是什么或事件的根本原因可能是什么。
Before progressing, we’ll pause and outline what might happen within a systemthat bypassed “Is there a problem?” to address, “Where is the problem?” As we’vepreviously indicated, this is an all too common occurrence. You might have an opera-tions center with lots of displays, dials, and graphs. Maybe you’ve even implementedthe heat map system we alluded to earlier. Without first knowing that there is a cus-tomer problem occurring, your team might be going through the daily “whack amole” process of looking at every subsystem that turns slightly red for some period oftime. Maybe it spends several minutes identifying that there was nothing other thanan anomalous disk utilization event occurring and potentially the team relaxes theoperations defined threshold for turning that subsystem red at any given time. All thewhile, customer support is receiving calls regarding end users’s inability to log intothe system. Customer support first assumes this is the daily rate of failed logins, butafter 10 minutes of steady calls, customer support contacts the operations center toget some attention applied to the issue.
在继续之前,我们将暂停并概述绕过“有问题吗?”的系统内可能会发生什么。去解决“问题出在哪里?”正如我们之前指出的,这种情况太常见了。您可能有一个带有大量显示器、刻度盘和图表的操作中心。也许您甚至已经实现了我们之前提到的热图系统。在不首先知道出现客户问题的情况下,您的团队可能会经历每天的“whack amole”过程,检查每个在一段时间内稍微变红的子系统。也许它需要花费几分钟的时间来确定除了发生异常磁盘利用率事件之外没有其他任何事情,并且团队可能会放宽操作定义的阈值,以便在任何给定时间将该子系统变成红色。与此同时,客户支持不断接到有关最终用户无法登录系统的电话。客户支持首先假设这是每日登录失败率,但经过 10 分钟的稳定通话后,客户支持联系运营中心以引起对该问题的关注。
As it turns out, CPU utilization and user connections to the login service were also“red” in our systems heat map while we were addressing the disk utilization report.Now, we are nearly 15 minutes into a customer related event and we have yet tobegin our diagnosis. If we had a monitoring system that reported on customer trans-actions, we would have addressed the failed logins incident first before addressingother problems that were not directly affecting customer experience. In this case, amonitoring solution that is capable of showing a reduction of certain types of trans-actions over time would have indicated that there was a potential problem (loginsfailing) and the operations team likely would have then looked for monitoring alertsfrom the systems identifying the location of the problem such as the CPU utilizationalerts on the login services.
事实证明,当我们处理磁盘利用率报告时,CPU 利用率和登录服务的用户连接在我们的系统热图中也呈“红色”。现在,我们距离客户相关事件已近 15 分钟,但我们尚未开始我们的诊断。如果我们有一个报告客户交易的监控系统,我们将首先解决登录失败事件,然后再解决其他不直接影响客户体验的问题。在这种情况下,能够显示某些类型的交易随着时间的推移而减少的监控解决方案将表明存在潜在的问题(登录失败),然后运营团队可能会寻找来自识别问题的系统的监控警报。问题的位置,例如登录服务上的 CPU 利用率警报。
The last question in our evolutionary model of monitoring is to answer, “What isthe problem?” Note that we’ve moved from identifying that there is an incident, con-sistent with our definition in Chapter 8, to isolating the area causing that incident toidentification of the problem itself, which helps us quickly get to the root cause ofany issues within our system. As we move from identifying that something is goingon to determining the cause for the incident, two things happen. The first is that theamount of data that we need to collect as we evolve from the first to the third ques-tion grows. We only need a few pieces of data to identify whether something, some-where is wrong. But to be able to answer, “What is the problem?” across the entirerange of possible problems that we might have, we need to collect a whole lot of dataover a substantial period of time. The other thing that is going on is that we are natu-rally narrowing our focus from the very broad “something is going on” to the verynarrow “I’ve found what is going on.” The two are inversely correlated in terms ofsize, as Figure 31.1 indicates. The more specific the answer to the question, the moredata we need to collect to determine the answer.
我们的监控进化模型中的最后一个问题是回答“问题是什么?”请注意,我们已经从识别存在事件(与第 8 章中的定义一致)转向隔离导致该事件的区域,再到识别问题本身,这有助于我们快速找到问题的根本原因。系统。当我们从识别正在发生的事情转向确定事件的原因时,会发生两件事。首先,随着我们从第一个问题发展到第三个问题,我们需要收集的数据量不断增加。我们只需要几条数据就可以识别出某些东西、某个地方是否有问题。但能够回答“问题是什么?”为了应对我们可能遇到的所有可能的问题,我们需要在相当长的一段时间内收集大量数据。正在发生的另一件事是,我们自然地将我们的注意力从非常广泛的“某件事正在发生”缩小到非常狭窄的“我已经发现正在发生的事情”。两者在大小方面呈负相关,如图 31.1 所示。问题的答案越具体,我们需要收集的数据就越多才能确定答案。
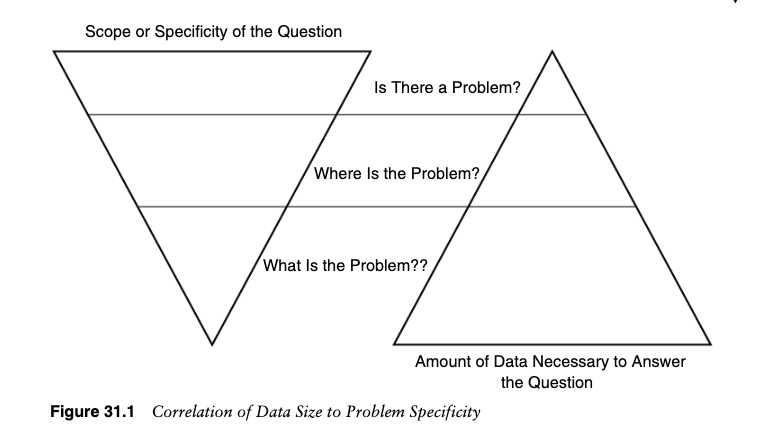
To be able to answer precisely for all problems what the source is, we must havequite a bit of data. The actual problem itself can likely be answered with one verysmall slice of this data, but to have that answer we have to collect data for all poten-tial problems. Do you see the problem this will cause? Without building a systemthat’s intelligent enough to determine if there is a problem, we will allocate people atseveral warnings of potential problems, and in the course of doing so will start to cre-ate an organization that ignores those warnings. A better approach is to build a sys-tem that alerts on impacting or pending events and then uses that as a trigger to guideus to the root cause.
为了能够准确回答所有问题的根源是什么,我们必须拥有相当多的数据。实际问题本身可能可以用一小部分数据来回答,但为了得到这个答案,我们必须收集所有潜在问题的数据。您看到这会导致什么问题吗?如果没有建立一个足够智能的系统来确定是否存在问题,我们将根据潜在问题的多个警告来分配人员,并在此过程中开始创建一个忽略这些警告的组织。更好的方法是构建一个系统,对影响或未决事件发出警报,然后将其用作触发器来引导我们找到根本原因。
“What is the problem?” is usually a deeper iteration of “Where is the problem?”Statistical process control can again be used in an even more granular basis to helpidentify the cause. Maybe, assuming we have the space and resources to do so, wecan plot the run times of each of our functions within our application over time. Wecan use the most recent 24 hours of data, compare it to the last week of data, andcompare the last week of data to the last month of data. We don’t have to keep thegranular by transaction records for each of our calls, but rather aggregate them overtime for the purposes of comparison. We can compare the rates of errors for each ofour services by error type for the time of day and day of week in question. Here, weare looking at the functions, methods, and objects that comprise a service rather thanthe operation of the service itself. As indicated earlier, it requires a lot more data, butwe can answer precisely what exactly the problem is for nearly any problem we areexperiencing.
问题是什么?”通常是“问题在哪里?”的更深入迭代,可以再次在更细粒度的基础上使用统计过程控制来帮助识别原因。也许,假设我们有足够的空间和资源来这样做,我们可以绘制应用程序中每个函数随时间的运行时间。我们可以使用最近24小时的数据,将其与上周的数据进行比较,将上周的数据与上个月的数据进行比较。我们不必为每个调用保留详细的交易记录,而是将它们随着时间的推移进行汇总以进行比较。我们可以根据相关一天中的某个时间和一周中的某一天的错误类型来比较每项服务的错误率。在这里,我们关注的是构成服务的功能、方法和对象,而不是服务本身的操作。如前所述,它需要更多的数据,但对于我们遇到的几乎任何问题,我们都可以准确地回答问题到底是什么。
Often, we can easily segment our three questions into three different types orapproaches to monitoring. “Is there a problem?” can often be implemented by find-ing a handful of user experience or real-time business metrics monitors. “Where isthe problem?” can often be accomplished by implementing out of the box systemlevel monitors. “What is the problem?” often relies on the way in which we log andcollect data for our proprietary systems.
通常,我们可以轻松地将三个问题分为三种不同的类型或监控方法。 “有问题吗?”通常可以通过找到一些用户体验或实时业务指标监视器来实现。 “哪里有问题?”通常可以通过实施开箱即用的系统级监视器来完成。 “问题是什么?”通常依赖于我们为专有系统记录和收集数据的方式。
The preceding approach is methodical in that it forces us first to build systems thatidentify problems before attempting to monitor everything within our platform orproduct. We do not mean to imply that absolutely no work should be done inanswering “Where is the problem?” and “What is the problem?” until “Is there aproblem?” is finished; rather, one should focus on applying most of the effort first inanswering the first question. As “Where is the problem?” is so easy to implement inmany platforms, applying 20% of your initial effort to this question initially will payhuge dividends, whereas forcing at least 50% of your initial effort to ensuring thatyou always know and can answer “Is there a problem?” “What is the problem?” isoften more difficult and takes careful thought regarding the design and deploymentof your proprietary technology.
前面的方法是有条不紊的,因为它迫使我们首先构建能够识别问题的系统,然后再尝试监视我们的平台或产品中的所有内容。我们并不是暗示完全不应该做任何工作来回答“问题出在哪里?”和“问题是什么?”直到“有问题吗?”完成了;相反,人们应该首先集中精力回答第一个问题。正如“问题出在哪里?”在许多平台上很容易实现,最初将 20% 的初始努力应用于这个问题将带来巨大的回报,而迫使您至少 50% 的初始努力确保您始终知道并能够回答“有问题吗?” “问题是什么?”通常更加困难,并且需要仔细考虑专有技术的设计和部署。
User Experience and Business Metrics 用户体验和业务指标
User experience and business metric monitors are meant to answer the question of“Is there a problem?” Often, you need to implement both of them to get a good viewof the overall health of a system, but in many cases, you need only a handful to beable to answer the question of whether a problem exists with a high degree of cer-tainty. For instance, in an ecommerce platform wherein revenue and profits are gen-erated primarily from sales, you may choose to look at revenue, searches, shoppingcart abandonment, and product views. You may decide to plot each of these in realtime against 7 days ago, 14 days ago, and the average of the last 52 similar weekdays.Any significant deviation from a well-established curve may be used to alert the teamthat a potential problem is occurring.
用户体验和业务指标监视器旨在回答“有问题吗?”的问题。通常,您需要同时实现这两者才能更好地了解系统的整体运行状况,但在许多情况下,您只需要少数几个就能够高度确定地回答问题是否存在的问题。例如,在收入和利润主要来自销售的电子商务平台中,您可以选择查看收入、搜索、购物车放弃和产品浏览。您可以决定根据 7 天前、14 天前以及过去 52 个类似工作日的平均值实时绘制每条曲线。任何与既定曲线的显着偏差都可以用来提醒团队正在发生潜在问题。
Advertising platforms may focus on cost per click by time of day, total clicks, cal-culated click through rates, and bid to item ratios. These too may be plotted againstthe values from 7 days ago, 14 days ago, and the average of the last 52 similar weekdays. Again, the idea here is to identify major business and customer experience met-rics that are both early and current indicators of problems.
广告平台可能会关注一天中不同时间段的每次点击成本、总点击次数、计算出的点击率以及出价与项目的比率。这些也可以根据 7 天前、14 天前的值以及过去 52 个类似工作日的平均值绘制。同样,这里的想法是确定主要的业务和客户体验指标,这些指标都是问题的早期和当前指标。
Third-party providers also offer last mile and customer experience monitoringsolutions that are useful in augmenting business metrics and user experience monitor-ing. Last mile and user agent monitoring solutions from Keynote and Gomez help usbetter understand when customers at distant locations can’t access our services andwhen those services are performing below our expectations. User experience solu-tions such as CA’s Wily products and Coradiant’s products help us better understandcustomer interactions, actions, and perceived response times.
第三方提供商还提供最后一英里和客户体验监控解决方案,这对于增强业务指标和用户体验监控非常有用。 Keynote 和 Gomez 的最后一英里和用户代理监控解决方案帮助我们更好地了解何时远方的客户无法访问我们的服务以及何时这些服务的表现低于我们的预期。 CA 的 Wily 产品和 Coradiant 的产品等用户体验解决方案帮助我们更好地了解客户交互、操作和感知响应时间。
Other metrics and thresholds that might affect your business can be consideredsuch as response times and such, but often these are more indicative of “where theproblem is” rather than that a problem exists. The best metrics here are directly cor-related to the creation of shareholder value. A high shopping cart abandonment rateand significantly lower click through rates are both indicative of likely user experi-ence problems that are negatively impacting your business.
可以考虑可能影响您的业务的其他指标和阈值,例如响应时间等,但通常这些更能表明“问题在哪里”,而不是问题存在。这里最好的指标与股东价值的创造直接相关。高购物车放弃率和显着降低的点击率都表明可能存在对您的业务产生负面影响的用户体验问题。
Systems Monitoring 系统监控
As we’ve hinted at earlier in this chapter, this is one of the areas that companies tendto cover well. We use the term systems monitoring to identify any grouping of hard-ware and software that share several components. We might have a service consistingof several functions or applications running on a pool of servers and we lump thisloose group of hardware and software into a “system.” Most monitoring systems andplatforms have agents that do this type of monitoring fairly well right out-of-the-box.You simply need to install the agents, configure them for your system, and plug theminto your monitoring framework. Where we tend to fail is in augmenting the tools tohelp us identify where there is a problem. Often, we rely on threshold alerts or highlycalibrated eyeballs to identify issues.
正如我们在本章前面所暗示的,这是公司往往擅长覆盖的领域之一。我们使用术语“系统监控”来识别共享多个组件的任何硬件和软件分组。我们可能有一个由在服务器池上运行的多个功能或应用程序组成的服务,我们将这些松散的硬件和软件组整合到一个“系统”中。大多数监控系统和平台都具有开箱即用的代理,可以很好地执行此类监控。您只需安装代理,为您的系统配置它们,然后将它们插入您的监控框架。我们往往失败的地方在于增强工具来帮助我们识别问题所在。通常,我们依靠阈值警报或高度校准的眼球来识别问题。
The problem with thresholds is that they are too often based on arbitrary values.“We shouldn’t go beyond 80% utilization for any given system.” A better approachis for us to be alerted when a system is behaving significantly different than the way ithas behaved in the past. This variation in approach is the basis for our recommenda-tions to investigate statistical process control, or at the very least, the plotting of valuesas compared to past values for a similar date and time as a method for identifying issues.
阈值的问题在于它们常常基于任意值。“对于任何给定系统,我们不应超过 80% 的利用率。”更好的方法是,当系统的行为与过去的行为方式显着不同时,我们就会收到警报。这种方法的变化是我们建议调查统计过程控制的基础,或者至少是与类似日期和时间的过去值进行比较的值绘图作为识别问题的方法。
We are relying on systems monitoring to tell us “where the problem is.” We have anew problem identified by our end user and business monitoring and, as it is a newproblem, we are probably looking for something that is performing differently than itperformed before the problem started. Threshold monitoring tells us that somethingis performing outside of our expectation, but what is even more valuable is for oursystem to tell us what is performing significantly differently than it has performed inthe past.
我们依靠系统监控来告诉我们“问题出在哪里”。我们的最终用户和业务监控发现了一个新问题,由于这是一个新问题,我们可能正在寻找与问题出现之前表现不同的东西。阈值监控告诉我们某些事情的表现超出了我们的预期,但对我们的系统来说更有价值的是告诉我们什么事情的表现与过去的表现有显着不同。
Application Monitoring 应用监控
Application monitoring is important to help identify “what is the problem?” Often, toanswer the question of “what is the problem?” we need to write some custom monitor-ing code. To do this well, we probably need to build the code into our product offer-ing itself. Although some out-of-the-box agents will tell us exactly what the problemis, as in the case of a slow I/O subsystem caused by one or more bad disks, it is sel-dom the case that an out-of-the-box agent can help us diagnose what part of our pro-prietary application has gone awry. Although the thought of self-healing applicationsare a bit of a pipe dream and not likely to be cost-effective in terms of developmenttime, the notion that an application can be self-diagnosing for the most commontypes of failures is both an admirable and achievable aspiration.
应用程序监控对于帮助识别“问题是什么?”非常重要。通常,要回答“问题是什么?”的问题。我们需要编写一些自定义监控代码。为了做好这一点,我们可能需要将代码构建到我们的产品本身中。尽管一些开箱即用的代理会准确地告诉我们问题是什么,例如由一个或多个坏磁盘引起的缓慢 I/O 子系统的情况,但很少会出现问题:即用型代理可以帮助我们诊断我们的专有应用程序的哪一部分出了问题。尽管自我修复应用程序的想法有点痴人说梦,而且在开发时间方面不太可能具有成本效益,但应用程序可以对最常见的故障类型进行自我诊断的概念既令人钦佩又可以实现。
For many companies, it is a relatively simple task, if undertaken early in develop-ment, to produce a set of reusable tools to help determine the cause of failures. Thesetools exist as services that are compiled or linked to the application or potentially justservices called by the application during runtime. Often, they are at critical chokepointswithin the application such as during the emission of an error or the calling of anotherservice or resource. Error logging routines can be augmented to classify error types in ameaningful fashion and keep track of the rate of error counts over time. Methods orfunctions can keep track of execution times by time of day and log them in a meaning-ful fashion for other processes to perform calculations. Remote service calls can log theresponse time of synchronous or asynchronous services on which an application relies.
对于许多公司来说,如果在开发早期就进行开发一套可重复使用的工具来帮助确定故障原因,那么这是一项相对简单的任务。这些工具作为编译或链接到应用程序的服务存在,或者可能只是应用程序在运行时调用的服务。通常,它们处于应用程序内的关键阻塞点,例如在发出错误或调用另一个服务或资源期间。可以增强错误记录例程,以有意义的方式对错误类型进行分类,并跟踪一段时间内的错误计数率。方法或函数可以按一天中的时间跟踪执行时间,并以有意义的方式记录它们,以便其他进程执行计算。远程服务调用可以记录应用程序所依赖的同步或异步服务的响应时间。
Monitoring Issues and a General Framework 监测问题和总体框架
Most monitoring platforms suffer from two primary problems:
大多数监控平台都面临两个主要问题
The systems being monitored were not designed to be monitored.
被监控的系统并不是为被监控而设计的。
The approach to monitoring is bottom up rather than top down and misses the critical question “Is there a problem affecting customers right now?”
监控方法是自下而上而不是自上而下,并且错过了关键问题“现在是否存在影响客户的问题?
Solving these problems is relatively easy:
解决这些问题相对容易
Designing your systems to be monitored before implementation.
将您的系统设计为在实施前进行监控。
Developing monitors to first answer the question “Is there a problem?” These are typically business metric and customer experience monitors.
开发监视器首先要回答“有问题吗?”的问题。这些通常是业务指标和客户体验监视器。
Developing monitors to next answer “Where is the problem?” These are typically systems level monitors.
开发监视器来回答“问题出在哪里?”这些通常是系统级监视器。
When completed with the first two questions, developing monitors to answer the question “What is the problem?” Often, these are monitors that you build into your application con-sistent with your design principles.
完成前两个问题后,开发监视器来回答“问题是什么?”通常,这些监视器是您根据设计原则构建到应用程序中的监视器。
It is very important to follow the steps in order, from top down, to develop a world-classmonitoring solution.
从上到下按顺序执行这些步骤对于开发世界一流的监控解决方案非常重要。
Measuring Monitoring: What Is and Isn’t Valuable? 衡量监控:什么有价值,什么不有价值?
Remember Chapter 27, Too Much Data? In that chapter, we argued that not all datais valuable to the company and that all data has a cost. Well, guess what? The same istrue for monitoring! If you monitor absolutely everything you can think of, there is avery real chance that you will use very little of the data that you collect. All the while,you will be creating the type of noise we described as being the harbinger of death formost monitoring platforms. Moreover, you are wasting employee time and companyresources, which in turn cost your shareholders money.
还记得第 27 章,数据太多吗?在那一章中,我们认为并非所有数据对公司都有价值,并且所有数据都有成本。嗯,你猜怎么着?监控也是如此!如果您绝对监控您能想到的所有内容,那么您很有可能会使用很少的收集到的数据。一直以来,您都会产生我们所说的大多数监控平台死亡预兆的噪音。此外,您还浪费了员工的时间和公司资源,这反过来又让股东损失了金钱。
The easiest way to help us understand which monitors provide us value and whichdo not are to step through our evolutionary monitoring framework in a top-downfashion and describe the value created by each of these tiers and how to limit the costof implementation.
帮助我们了解哪些监控器为我们提供价值、哪些不提供价值的最简单方法是以自上而下的方式逐步浏览我们的演化监控框架,并描述每一层所创造的价值以及如何限制实施成本。
Our first question was “Is there a problem?” As we previously indicated, there arelikely a handful, let’s say no less than three and no more than 10 monitors, that willboth serve as predictive and current indicators that there will be or currently is aproblem. As the number of items that we are tracking is relatively small, data reten-tion should not be that great of a concern. It would be great to be able to plot thisdata in minute or hourly records as compared to at least the last two weeks of similardays of the week. If today is Tuesday, we probably want the last two Tuesdays’ worthof data. We probably should just keep that data for at least the last two weeks butmaybe we expand it to a month before we collapse the data. In the grand scheme ofthings, this data will not take a whole lot of space. Moreover, it will save us a lot oftime in predicting and determining if there will be or currently is a problem.
我们的第一个问题是“有问题吗?”正如我们之前指出的,可能有少数(假设不少于 3 个且不超过 10 个)监视器,它们都将充当将存在或当前存在问题的预测和当前指标。由于我们跟踪的项目数量相对较少,因此数据保留不应引起太大关注。如果能够以分钟或每小时的记录来绘制这些数据,并与一周中至少最后两周的相似日期进行比较,那就太好了。如果今天是星期二,我们可能需要过去两个星期二的有价值的数据。我们可能应该至少保留过去两周的数据,但也许我们可以在折叠数据之前将其扩展到一个月。从长远来看,这些数据不会占用太多空间。此外,这将为我们节省大量时间来预测和确定是否会出现问题或当前是否存在问题。
The next question we ask is “Where is the problem?” In Figure 31.1, our pyramidindicates that although the specificity is narrowing, the amount of data is increasing.This should cause us some concern as we will need many more monitors to accom-plish this. It is likely that the number of monitors is somewhere between an order ofmagnitude and two orders of magnitude (10 to 100) greater than our original sets ofmonitors. In very large, complex, and distributed systems, this might be an evenlarger number. We still need to compare information to previous similar days, ideallyat a granular level. But we are going to need to be much more aggressive in our rollupand archival/deletion strategies. Ideally, we will summarize data potentially first bythe hour and then eventually just move the data into a moving average calculation.Maybe we plot and keep graphs but remove the raw data over time. We certainly donot want the raw data sitting around ad infinitum as the probability that most of itwill be used is low, the value is low, and the cost is high.
我们要问的下一个问题是“问题出在哪里?”在图 31.1 中,我们的金字塔表明,虽然特异性正在缩小,但数据量正在增加。这应该引起我们的一些担忧,因为我们将需要更多的监视器来完成此任务。监视器的数量可能比我们原来的监视器组多一个数量级到两个数量级(10 到 100)。在非常大、复杂的分布式系统中,这个数字可能更大。我们仍然需要将信息与之前类似的日子进行比较,最好是在粒度级别上进行比较。但我们需要在汇总和归档/删除策略方面更加积极主动。理想情况下,我们可能首先按小时汇总数据,然后最终将数据转移到移动平均计算中。也许我们绘制并保留图表,但随着时间的推移删除原始数据。我们当然不希望原始数据无限期地存在,因为大部分数据被使用的概率很低,价值很低,成本很高。
Finally, we come to the question of “What is the problem?” Again, we have atleast an order of magnitude increase from our previous monitoring. We are addingraw output logs, error logs, and other data to the mix. This stuff grows quickly, espe-cially in chatty environments. We probably hope to keep about two weeks of thedata, where two weeks is determined by assuming that we will catch most issueswithin two weeks. You may have better information on what to keep and what toremove, but again you simply cannot subject your shareholders to your desire tocheck up on anything at any time. That desire has a near infinite cost and a very, verylow relative return.
最后,我们提出“问题是什么?”的问题。同样,我们的监测比之前的监测至少增加了一个数量级。我们正在添加原始输出日志、错误日志和其他数据。这些东西增长得很快,尤其是在聊天的环境中。我们可能希望保留大约两周的数据,其中两周是通过假设我们将在两周内发现大多数问题来确定的。您可能对保留什么和删除什么有更好的信息,但同样,您不能让您的股东屈服于您随时检查任何内容的愿望。这种欲望的成本几乎是无限的,而相对回报却非常非常低。
Monitoring and Processes 监控和流程
Alas, we come to the point of how all of this monitoring fits into our operations andbusiness processes. Our monitoring infrastructure is the lifeblood of many of ourprocesses. The monitoring we perform to answer the questions of “Is there a prob-lem?” to “What is the problem?” will likely create the data necessary to inform thedecisions within many of the processes we described in Part II, Building Processes forScale, and even some of the measurements and metrics we described within Chapter 5,Management 101.
唉,我们谈到了所有这些监控如何融入我们的运营和业务流程的问题。我们的监控基础设施是我们许多流程的命脉。我们进行的监控是为了回答“有问题吗?”的问题。到“问题是什么?”可能会创建必要的数据,为我们在第二部分“构建规模化流程”中描述的许多流程中的决策提供信息,甚至是我们在第 5 章“管理 101”中描述的一些测量和指标。
The monitors that produce data necessary to answer the question of “Is there aproblem?” produce critical data for measuring our alignment to the creation ofshareholder value. You might remember that we discussed availability as a metric inChapter 5.The goal is to be able to consistently answer “No” to the question of “Isthere a problem?” If you can do that, you have high availability. Measuring availabil-ity from a customer perspective and from a business metric perspective, as opposedto a technology perspective, gives you both the tools to answer the “Is there a prob-lem?” question and to measure yourself against your availability goal. The differencebetween revenue or customer availability and technology availability is importantand drives cultural changes that have incredible benefit to the organization. Technol-ogists have long measured availability as a product of the availability of all thedevices within their care. That absolutely has a place and is important to such con-cerns as cost, mean time between failures, headcount needs, redundancy needs, meantime to restore, and so on. But it doesn’t really relate to what the shareholders or cus-tomers care about most; what these constituents care about most is that the service isavailable and generating the greatest value possible. As such, measuring the experi-ence of customers and the generation of profits in real time is much more valuable forboth answering our first and most important monitoring question and measuringavailability. With only a handful of monitors we can satisfy one of our key managementmeasurements, help ensure that we are identifying and reacting to impending andcurrent events, and align our culture to the creation of shareholder and customer value.
生成回答“有问题吗?”问题所需的数据的监视器。生成关键数据来衡量我们与股东价值创造的一致性。您可能还记得我们在第 5 章中讨论了可用性作为衡量标准。目标是能够对“有问题吗?”的问题始终回答“否”。如果您能做到这一点,那么您就拥有高可用性。从客户角度和业务指标角度(而不是技术角度)衡量可用性,为您提供了回答“是否存在问题?”的工具。问题并根据您的可用性目标来衡量自己。收入或客户可用性与技术可用性之间的差异很重要,并推动文化变革,为组织带来难以置信的好处。长期以来,技术人员一直将可用性作为他们所关心的所有设备的可用性的结果来衡量。这绝对占有一席之地,并且对于成本、平均故障间隔时间、人员需求、冗余需求、恢复时间等问题很重要。但这与股东或客户最关心的事情并不真正相关;这些选民最关心的是服务是否可用并产生尽可能最大的价值。因此,实时衡量客户体验和利润产生对于回答我们第一个也是最重要的监控问题和衡量可用性来说更有价值。只需少数监控器,我们就可以满足我们的一项关键管理衡量标准,帮助确保我们能够识别即将发生的和当前的事件并做出反应,并使我们的文化与股东和客户价值的创造保持一致。
The monitors that drive “Where is the problem?” are also very often the sourcesof data that we will use in our capacity planning and headroom processes fromChapter 11, Determining Headroom for Applications. The raw data here will help usdetermine where we have constraints in our system and help us focus our attentionon budgeting to horizontally scale those platforms or drive the architectural changesnecessary to scale more cost effectively. This information also helps feed our incidentand crisis management processes of Chapters 8 and 9.It is obviously useful duringthe course of an incident or crisis and it definitely proves valuable during postmortemactivities when we are attempting to find out how we could have isolated the incidentearlier or prevented the incident from happening. The data also feeds into and helpsinform changes to our performance testing processes.
驱动“问题出在哪里?”的监视器也经常是我们将在第 11 章“确定应用程序的余量”中的容量规划和余量流程中使用的数据源。这里的原始数据将帮助我们确定系统中存在哪些限制,并帮助我们将注意力集中在预算上,以水平扩展这些平台或推动必要的架构变更,以更经济有效地扩展。这些信息还有助于充实我们第 8 章和第 9 章的事件和危机管理流程。在事件或危机发生期间,它显然很有用,并且在事后活动中,当我们试图找出如何更早地隔离事件或预防事件时,它绝对证明是有价值的。事件的发生。这些数据还反馈到我们的性能测试流程中并帮助通知其变化。
The data that answers the question of “What is the problem?” is useful in many ofthe processes described for “Where is the problem?” Additionally, it is useful in help-ing us test whether we are properly designing our systems to be monitored. The out-put of our postmortems and operations reviews should be taken by the engineeringstaff and analyzed against the data and information we produce to help us identifyand diagnose problems. The intent is that we feed this information back to our codereview and design review processes so that we are creating better and more intelligentmonitoring that helps us identify issues before they occur or isolate them faster whenthey do occur.
这些数据回答了“问题是什么?”的问题。在“问题出在哪里?”描述的许多过程中都很有用。此外,它还有助于帮助我们测试是否正确设计了要监控的系统。我们的事后分析和运营审查的输出应该由工程人员进行,并根据我们产生的数据和信息进行分析,以帮助我们识别和诊断问题。目的是我们将这些信息反馈给我们的代码审查和设计审查流程,以便我们创建更好、更智能的监控,帮助我们在问题发生之前识别问题,或者在问题发生时更快地隔离它们。
That leaves us with the management of incidents and problems as identified withinChapter 8 and the management of crises and escalations as identified in Chapter 9.Inthe ideal world, incidents and crises are predicted and avoided by a robust and pre-dictive monitoring solution, but at the very least, they should be identified at thepoint at which they start to cause customer problems and impact shareholder value.In many mature monitoring solutions, the monitoring system itself will be responsi-ble not only for the initial detection of an incident but for the reporting or recordingof that incident. In this fashion, the monitoring system is responsible for both theDetect and Report of our DRIER model identified in Chapter 8.
这让我们需要对第 8 章中确定的事件和问题进行管理,以及对第 9 章中确定的危机和升级进行管理。在理想的世界中,事件和危机可以通过强大的预测性监控解决方案来预测和避免,但在至少,应该在它们开始引起客户问题并影响股东价值时识别它们。在许多成熟的监控解决方案中,监控系统本身不仅负责事件的初步检测,还负责事件的后续处理。报告或记录该事件。以这种方式,监控系统负责第 8 章中确定的 DRIER 模型的检测和报告。
Conclusion 结论
This chapter discussed monitoring. We posited that the primary reasons for mostmonitoring initiatives and platforms failing repeatedly is that our systems are notdesigned to be monitored and that our general approach to monitoring is flawed. Toooften, we attempt to monitor from the bottom up, starting with individual agents andlogs rather than attempting to first create monitors that answer the question of “Isthere a problem?”
本章讨论了监控。我们认为,大多数监控举措和平台反复失败的主要原因是我们的系统不是为被监控而设计的,而且我们的一般监控方法存在缺陷。我们常常尝试从下到上进行监控,从单个代理和日志开始,而不是尝试首先创建回答“有问题吗?”的问题的监视器。
The best organizations design their monitoring platforms from the top down. Thesesystems first are capable, with a high degree of accuracy, in answering the question of“Is there a problem?” The types of monitors that answer these questions best aretightly aligned with the business and technology drivers that create shareholdervalue. Most often, these are real-time monitors on transaction volumes, revenue cre-ation, cost of revenue, and customer interactions with the system. Third-party cus-tomer experience systems can be employed to augment real-time business metricsystems to answer this most important question.
最好的组织是自上而下设计监控平台的。这些系统首先能够高度准确地回答“有问题吗?”的问题。最能回答这些问题的监控器类型与创造股东价值的业务和技术驱动因素紧密结合。大多数情况下,这些是对交易量、收入创造、收入成本以及客户与系统交互的实时监控。可以采用第三方客户体验系统来增强实时业务指标系统,以回答这个最重要的问题。
The next step, when we’ve properly built systems to answer “Is there a problem?”is to answer build systems to answer “Where is the problem?” Often, these systemsare out-of-the-box third-party or open source solutions that you install on systems tomonitor resource utilization. Some application monitors might also be employed.The data collected by these systems help inform other processes such as our capacityplanning process and problem resolution process. Care must be taken to avoid acombinatorial explosion of data, as that data is costly and the value of immenseamounts of old data is very low.
下一步,当我们正确构建系统来回答“有问题吗?”时,就是回答构建系统来回答“问题在哪里?”通常,这些系统是开箱即用的第三方或开源解决方案,您可以将其安装在系统上以监控资源利用率。还可能使用一些应用程序监视器。这些系统收集的数据有助于为其他流程提供信息,例如我们的容量规划流程和问题解决流程。必须小心避免数据的组合爆炸,因为这些数据成本高昂,而且大量旧数据的价值非常低。
Finally, we move to answer the question of “What is the problem?” This veryoften requires us to rely heavily on our architectural principal Design to Be Moni-tored. Here, we are monitoring individual components, and often these are propri-etary applications for which we are responsible. Again, the concerns of dataexplosion are present, and we must fight to ensure that we are keeping the right dataand not diluting shareholder value.
最后,我们来回答“问题是什么?”的问题。这通常要求我们严重依赖我们的架构主要设计进行监控。在这里,我们正在监视各个组件,这些组件通常是我们负责的专有应用程序。同样,数据爆炸的担忧仍然存在,我们必须努力确保我们保留正确的数据并且不会稀释股东价值。
Focusing first on “Is there a problem?” will pay huge dividends throughout the lifeof your monitoring system. It is not necessary to focus 100% of your monitoringefforts on answering this question, but it is important to spend a majority (50% ormore) of your time on the question until you have it absolutely nailed.
首先关注“有问题吗?”将在您的监控系统的整个生命周期中带来巨大的红利。没有必要将 100% 的监控精力集中在回答这个问题上,但重要的是要花大部分(50% 或更多)时间在这个问题上,直到完全解决这个问题。
Key Points 关键点
Most monitoring platforms suffer from a failure to properly design systems tobe monitored and a bottom-up approach to monitoring that fails to answer themost important questions first.
大多数监控平台都未能正确设计要监控的系统,并且自下而上的监控方法无法首先回答最重要的问题。
- Adding Design to Be Monitored as an architectural principle helps fix this problem.
A change in approach to be top down rather than bottom up solves the secondhalf of the problem.
添加要监控的设计作为架构原则有助于解决此问题。
方法的改变是自上而下而不是自下而上解决了问题的后半部分。
Answering the questions of “is there a problem?”, “where is the problem?”, and“what is the problem?” in that order when designing a monitoring system is aneffective top-down strategy.
回答“有问题吗?”、“问题在哪里?”、“问题是什么?”等问题。在设计监控系统时按这个顺序是一种有效的自上而下的策略。
“Is there a problem?” monitors are best answered by aligning the monitors tothe measurements of shareholder and stakeholder value creation. Real-timebusiness metrics and customer experience metrics should be employed.
“有问题吗?”最好的回应监控者的方法是使监控者与股东和利益相关者价值创造的衡量标准保持一致。应采用实时业务指标和客户体验指标。
“Where is the problem?” monitors may very well be out-of-the-box third-partyor open source solutions that are relatively simple to deploy. Be careful withdata retention and attempt to use real-time statistics when employing thesemeasurements.
“哪里有问题?”监视器很可能是开箱即用的第三方或开源解决方案,部署相对简单。在采用这些测量时,请注意数据保留并尝试使用实时统计数据。
“What is the problem?” monitors are most likely homegrown and integratedinto your proprietary application.
“问题是什么?”监视器很可能是自行开发的并集成到您的专有应用程序中。
已有 7 条评论
《锤子镰刀都休息》剧情片高清在线免费观看:https://www.jgz518.com/xingkong/160372.html
你的才华让人惊叹,请继续保持。 http://www.55baobei.com/FvDQdjokPp.html
你的文章内容非常卖力,让人点赞。 http://www.55baobei.com/ZgOSIqMlbR.html
你的文章让我心情愉悦,每天都要来看一看。 http://www.55baobei.com/3HYgMF3UmN.html
你的文章让我心情愉悦,每天都要来看一看。 http://www.55baobei.com/wmK24WAmbc.html
你的文章让我心情愉悦,每天都要来看一看。 https://www.yonboz.com/video/85628.html
你的文章内容非常精彩,让人回味无穷。 http://www.55baobei.com/CTJtMOi5Qb.html