这篇文章上次修改于 299 天前,可能其部分内容已经发生变化,如有疑问可询问作者。
Chapter 24###Splitting Databases for Scale 第24章 规模化数据库拆分
So in war, the way is to avoid what is strong and to strike at what is weak.—Sun Tzu
所以战争之道是避强攻弱。——《孙子》
Chapter 22, Introduction to the AKF Scale Cube, introduced the scale cube anddescribed the concepts by applying them to organizational structures. Chapter 23,Splitting Applications for Scale, showed how the cube could be applied to applica-tions and systems. In this chapter, we are going to focus the AKF Scale Cube on data-bases and persistent storage systems. By the end of the chapter, you will have all theconcepts necessary to apply the cube to the needs of your own business. Armed withChapters 21, Creating Fault Isolative Architectural Structures, through 24, youshould be able to create a fault isolative architecture capable of nearly infinite scale,thereby increasing customer satisfaction and shareholder returns.
第 22 章“AKF 规模立方体简介”介绍了规模立方体,并通过将其应用于组织结构来描述这些概念。第 23 章,拆分应用程序以实现规模化,展示了如何将立方体应用于应用程序和系统。在本章中,我们将把 AKF Scale Cube 的重点放在数据库和持久存储系统上。到本章结束时,您将掌握将多维数据集应用到您自己的业务需求所需的所有概念。有了第 21 章“创建故障隔离架构结构”到第 24 章的帮助,您应该能够创建一个几乎无限规模的故障隔离架构,从而提高客户满意度和股东回报。
The AKF Scale Cube for Databases 适用于数据库的 AKF Scale Cube
As we discussed in Chapter 23, the AKF Scale Cube really doesn’t change whenapplied to databases and other persistent storage systems. We will, however, want tofocus the names and themes of the axes to make them more easily used as a tool tohelp us scale our data. As with our application focused descriptions, these newdescriptions won’t deviate from the original cube but will rather enable them withgreater meaning when applied to databases and data. For the following discussion,please reference Figure 22.4 (in Chapter 22) and Figure 24.1.
正如我们在第 23 章中讨论的,AKF Scale Cube 在应用于数据库和其他持久存储系统时实际上不会改变。然而,我们希望关注轴的名称和主题,以使它们更容易用作帮助我们扩展数据的工具。与我们以应用程序为中心的描述一样,这些新的描述不会偏离原始的立方体,而是在应用于数据库和数据时使它们具有更大的意义。下面的讨论请参考图22.4(第22章)和图24.1。
The x-axis, as you will recall from Chapter 22, focuses on the cloning of servicesand data with absolutely no bias. Each x-axis implementation requires the completecloning or duplication of an entire data set. We will rename our x-axis to be calledHorizontal Duplication/Cloning of Data to make it more obvious how we will applythis to our data scalability efforts.
正如您在第 22 章中所记得的那样,x 轴专注于毫无偏见的服务和数据克隆。每个 x 轴实现都需要完整克隆或复制整个数据集。我们将把 x 轴重命名为数据的水平复制/克隆,以便更明显地了解我们如何将其应用到我们的数据可扩展性工作中。
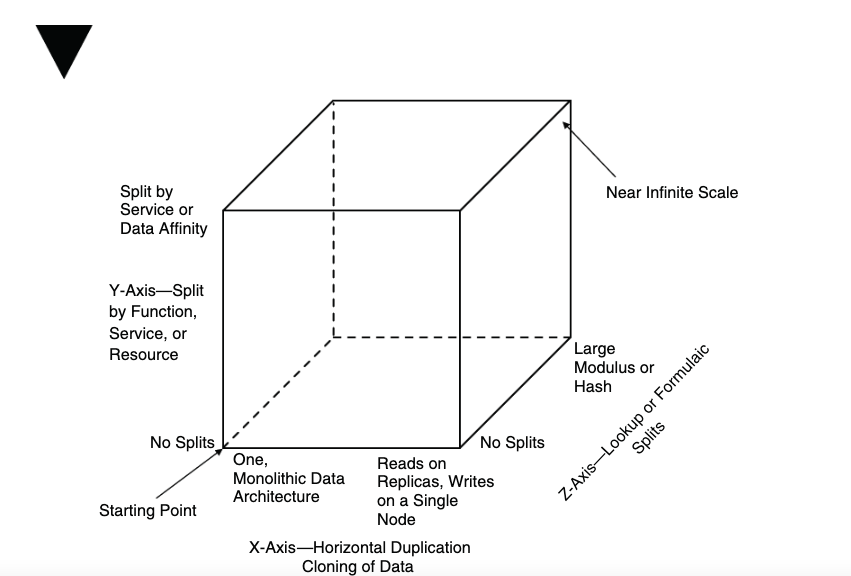
The y-axis was described as a separation of work responsibility by either the typeof data, the type of work performed for a transaction, or a combination of both.When applied to data, this definition remains completely true. Y-axis data splitseither focus on splitting data thematically with a bias to the type of data being split orwith a bias toward the work that is performed on that data. This latter definition is aservices oriented split similar to those discussed in Chapter 23.
y 轴被描述为通过数据类型、为事务执行的工作类型或两者的组合来划分工作职责。当应用于数据时,此定义仍然完全正确。 Y 轴数据拆分要么侧重于按主题拆分数据,要么偏向于所拆分的数据类型,要么偏向于对该数据执行的工作。后一个定义是面向服务的分割,类似于第 23 章中讨论的那些。
The z-axis of our database cube continues to have a customer or requestor bias.When applied to databases and data, the z-axis very often requires the implementa-tion of a lookup service or lookup algorithm. We store the relationships of user datato their appropriate split within a service or a database, or we calculate the locationbased on an algorithm such as a hash, modulus, or other deterministic means.
我们的数据库立方体的 z 轴仍然存在客户或请求者偏差。当应用于数据库和数据时,z 轴通常需要实现查找服务或查找算法。我们将用户数据的关系存储到服务或数据库中适当的分割,或者我们根据哈希、模数或其他确定性方法等算法计算位置。
The new AKF Scale Cube for databases now looks like Figure 24.1.
用于数据库的新 AKF Scale Cube 现在如图 24.1 所示。
The X-Axis of the AKF Database Scale Cube AKF 数据库比例立方体的 X 轴
The x-axis of the AKF Database Scale Cube represents cloning of data with abso-lutely no bias. If we have a data tier scaled using the x-axis alone and consisting of Nsystems, each of the N databases will have exactly the same data as other (N-1) sys-tems, with some minor differences resulting from replication delay. There is no biasto the transactions performed on this data, or to customer or any other data element;customer metadata and account information exists alongside product catalog data,inventory information, contact information, and so on. A request for data can beserved from any of the N databases or storage implementations. Typically, writes aremade to a single node within the replicated copies of data, primarily to reduce readand write contention on the nodes that make up this data tier.
AKF Database Scale Cube 的 x 轴代表绝对无偏差的数据克隆。如果我们有一个仅使用 x 轴缩放并由 N 个系统组成的数据层,则 N 个数据库中的每一个都将具有与其他 (N-1) 个系统完全相同的数据,但由于复制延迟而导致一些细微的差异。对此数据、客户或任何其他数据元素执行的交易没有偏见;客户元数据和帐户信息与产品目录数据、库存信息、联系信息等一起存在。可以从 N 个数据库或存储实现中的任何一个来提供对数据的请求。通常,写入是对数据复制副本中的单个节点进行的,主要是为了减少构成该数据层的节点上的读写争用。
As with the application cube, the x-axis approach is simple to implement in mostcases. Typically, you will implement some sort of replication system that allows forthe near real-time replication of data within the database or storage systems acrosssome scalable and configurable number N replicated databases or persistent storagesystems. Your database likely has this replication capability built into it natively, butyou can also likely find third-party tools to allow you to perform the replication.
与应用程序立方体一样,x 轴方法在大多数情况下很容易实现。通常,您将实现某种复制系统,该系统允许跨一些可扩展且可配置的 N 个复制数据库或持久存储系统对数据库或存储系统内的数据进行近乎实时的复制。您的数据库可能本身就内置了这种复制功能,但您也可能找到第三方工具来允许您执行复制。
Replication Delay Concerns 复制延迟问题
Many companies with which we work initially display some level of concern when we bring upthe topic of replication delay. The most common theme within this concern is the perceivedneed to be able to immediately access the most current data element for any write. In the mostextreme case, we’ve had clients immediately read a piece of datum out of a database to vali-date that what was just written was in fact correct.
当我们提出复制延迟的话题时,与我们合作的许多公司最初都表现出一定程度的担忧。此问题中最常见的主题是需要能够立即访问任何写入的最新数据元素。在最极端的情况下,我们让客户立即从数据库中读取一条数据,以验证刚刚写入的内容实际上是正确的。
In most cases, we are successful in helping our clients identify a large portion of their datathat need only be current within the last single digit number of seconds. Database native andthird-party replication tools within a single data center, even under high volume, can typicallykeep replicated copies of databases in synch with a master within five seconds, and sometimeseven within a second of the master copy. Geographically distant data centers can often be syn-chronized in less than 10 seconds.
在大多数情况下,我们成功地帮助客户识别出大部分数据,这些数据只需要在最后一位数秒内保持最新状态。单个数据中心内的数据库本机和第三方复制工具,即使在高容量的情况下,通常也可以在五秒内保持数据库的复制副本与主副本同步,有时甚至在一秒内与主副本保持同步。地理上遥远的数据中心通常可以在不到 10 秒的时间内实现同步。
The tests and questions that we most often recommend in determining if replicated data issufficient include the following:
在确定复制数据是否足够时,我们最常推荐的测试和问题包括以下内容
How often is this particular data element updated? If the ratio of views to updates is high, replication delay is probably acceptable. If updates are frequent and views are infrequent or very low in number, there is little benefit in replication.
该特定数据元素多久更新一次?如果视图与更新的比率很高,则复制延迟可能是可以接受的。如果更新频繁而视图不频繁或数量很少,则复制几乎没有什么好处。
Will the element that is read be used in a calculation for a future write? If so, replication delays might not be acceptable.
读取的元素是否会用于未来写入的计算中?如果是这样,复制延迟可能是不可接受的。
What is the difference in value for decision making purposes? If, for instance, the newest update changes a value insignificantly will it really make a difference in a resulting deci-sion on the part of the person viewing the data?
对于决策目的来说,价值有何不同?例如,如果最新的更新对某个值的更改并不显着,那么它真的会对查看数据的人的最终决策产生影响吗?
When considering database replication options, look first for functionality native to yourdatabase. It almost never makes sense to build replication functionality yourself, and with mostdatabases having replication built-in, there is seldom a need to purchase third-party software.
在考虑数据库复制选项时,首先寻找数据库本身的功能。自己构建复制功能几乎没有意义,并且大多数数据库都内置复制功能,因此很少需要购买第三方软件。
Writes typically happen to a single node within the replicated x-axis data tier. Bywriting to a single node, we reduce the read and write conflicts across all nodes andforce a single node to do the work of ensuring the ACID properties (Atomicity, Con-sistency, Isolation, and Durability) of the database or to ensure that the storage sub-system can be optimized for writes or reads only. Many times, the “write” copy ofthe storage tier is used only to write, but sometimes a small number of reads is sched-uled to that node if the time sensitivity of the read in question will not allow for theminor delay inherent to replication.
写入通常发生在复制的 x 轴数据层中的单个节点上。通过对单个节点的写入,减少了所有节点之间的读写冲突,强制单个节点来承担保证数据库ACID属性(原子性、一致性、隔离性、持久性)或者保证存储的工作子系统可以针对写入或只读进行优化。很多时候,存储层的“写”副本仅用于写入,但有时,如果所讨论的读取的时间敏感性不允许复制固有的较小延迟,则少量读取会被安排到该节点。
We often teach that distributed object caches and other database related caches, atleast those intended to reduce load on a database, can be examples of x-axis splits.Some might argue that if the data is represented in a format intended to be more eas-ily consumed by service that they are examples of y-axis splits. Rather than discuss-ing either in this chapter, we will have a broad treatment of caches in Chapter 25,Caching for Performance and Scale.
我们经常教导分布式对象缓存和其他与数据库相关的缓存,至少是那些旨在减少数据库负载的缓存,可以是 x 轴拆分的示例。有些人可能会争辩说,如果数据以更容易的格式表示,它们是 y 轴分割的示例,因此经常被服务消耗。我们不会在本章中讨论任何一个,而是在第 25 章“性能和规模缓存”中对缓存进行广泛的处理。
The x-axis split has several benefits and drawbacks. Consistent with Chapters 22and 23, this split is easy to envision and implement. Many databases have native rep-lication technologies that allow for “write and read only” copies or “master andslave” copies of a database. These native replication engines usually allow for multi-ple read or “slave” copies of the database. Another x-axis implementation is cluster-ing. Most open source or licensed relational database management systems have thiscapability. By clustering we mean two or more physically separated databases thatappear to the application as a single instance.
x 轴分割有几个优点和缺点。与第 22 章和第 23 章一致,这种划分很容易设想和实施。许多数据库具有本机复制技术,允许数据库的“写入和只读”副本或“主从”副本。这些本机复制引擎通常允许数据库的多个读取或“从属”副本。另一种 x 轴实现是聚类。大多数开源或许可的关系数据库管理系统都具有此功能。通过集群,我们指的是两个或多个物理上分离的数据库,它们对应用程序来说表现为单个实例。
Should a storage system without a database be the target of this technique, thereare many logical and physical replication systems existing in both open source andthird-party supported systems. The system allows for linear scale with transactions,but most replication processes have limits to the number of targets or read only nodesallowed. While this approach allows for linear transaction growth, it does notaddress data growth and the impact of that data growth on request processing timeor the impact of that data growth to addressable storage within any given storagesubsystem.
如果没有数据库的存储系统是该技术的目标,则开源和第三方支持的系统中都存在许多逻辑和物理复制系统。该系统允许事务线性扩展,但大多数复制过程对允许的目标或只读节点的数量有限制。虽然此方法允许线性事务增长,但它没有解决数据增长以及该数据增长对请求处理时间的影响或该数据增长对任何给定存储子系统内的可寻址存储的影响。
Because x-axis splits are easy to envision and implement, they should typically beyour first approach to scale any system when the number of transactions is the pri-mary driver of growth. The impact to cost in terms of loss opportunity associatedwith engineering effort is low and although the first time setup cost to implement theadditional datasets and begin replication is not trivial, it is still low relative to theother methods of data scalability. As with the application x-axis split, the impact totime to market to release functionality is generally low, as typically you are imple-menting a third-party, native, or open source replication technology.
由于 x 轴拆分很容易设想和实现,因此当事务数量是增长的主要驱动力时,它们通常应该是扩展任何系统的第一个方法。就与工程工作相关的损失机会而言,对成本的影响很低,尽管实施附加数据集和开始复制的首次设置成本并不小,但相对于其他数据可扩展性方法来说,它仍然很低。与应用程序 x 轴拆分一样,发布功能对上市时间的影响通常很低,因为通常您正在实施第三方、本机或开源复制技术。
X-axis splits also allow us to easily scale our data with the number of inboundtransactions or requests. As request growth increases, we simply add more readnodes. Capacity planning is easy as well because each of our nodes, if served fromsimilar hardware, can likely handle a similar number of requests. There is likely alimit to the number of systems that can be employed and this limit will normallydrive us to other methods of scale as our transaction growth continues to increase.Sometimes, we cannot even achieve the vendor or system supported limit due to theincrease in replication time delays because additional read only nodes are deployed.Usually, each node has some small impact to the time that it takes to replicate datafrom the write node. In some implementations, this impact may not manifest itself asa delay to all nodes but rather a consistently unacceptable delay to one of the nodeswithin the cluster as we start to reach our maximum target. As such, we cannot sim-ply rely on the x-axis for scale even in systems of relatively low data growth if trans-action growth is going to accelerate over time.
X 轴分割还允许我们轻松地根据入站事务或请求的数量来缩放数据。随着请求增长的增加,我们只需添加更多读取节点。容量规划也很容易,因为如果我们的每个节点由相似的硬件提供服务,则可能可以处理相似数量的请求。可以使用的系统数量可能存在限制,随着事务增长的不断增加,这种限制通常会促使我们采用其他扩展方法。有时,由于复制时间的增加,我们甚至无法达到供应商或系统支持的限制由于部署了额外的只读节点,因此会出现延迟。通常,每个节点对从写入节点复制数据所需的时间都有一些小的影响。在某些实现中,这种影响可能不会表现为所有节点的延迟,而是当我们开始达到最大目标时,集群内的一个节点始终出现不可接受的延迟。因此,如果交易增长随着时间的推移而加速,即使在数据增长相对较低的系统中,我们也不能简单地依赖 x 轴进行扩展。
One final benefit of the x-axis is that the team managing the infrastructure of yourplatform does not need to worry about a vast number of uniquely configured sche-mas or storage systems. Every system performing an x-axis split is exactly equivalentto every other system performing the same split, with the exception of a single systemdedicated to “writing.” Configuration management of all nodes is relatively easy toperform and new service implementation is as easy as replicating the data within anexisting system. Your application, when written to read from a “read service” andwrite to a “write service,” should scale without further involvement from your engi-neering team. Ideally, the multiple read systems are addressed through a third-partyload balancing system rather than the alternative of having your team write even asmall routine to “load balance” or evenly apportion the reads.
X 轴的最后一个好处是,管理平台基础设施的团队无需担心大量独特配置的架构或存储系统。每个执行 x 轴拆分的系统与执行相同拆分的所有其他系统完全相同,但专用于“写入”的单个系统除外。所有节点的配置管理相对容易执行,并且新服务的实现就像在现有系统中复制数据一样容易。当您的应用程序被编写为从“读取服务”读取并写入“写入服务”时,应该可以在无需工程团队进一步参与的情况下进行扩展。理想情况下,多个读取系统是通过第三方负载平衡系统来解决的,而不是让您的团队编写一个小例程来“负载平衡”或均匀分配读取。
There are two primary drivers that move us away from scaling along the x-axisalone. The first was discussed while addressing the limitations of existing replicationtechnology. The second driver is that x-axis scale techniques do not address the scaleissues inherent to an increase in the size or amount of data. As with the caching con-cern in Chapter 23, when you increase the size of data within a database, theresponse times even in indexed tables increase. This increase is not a linear relation-ship if you are properly using an index, but it represents a cost in response time andprocessing time nonetheless. This increase in response time may ultimately drive youto other splits. In nondatabase storage systems, the complexity of storage relation-ships for very large volumes of data will likely drive you to segmentation for ease ofmaintenance and operations.
有两个主要驱动因素使我们不再仅沿 x 轴进行缩放。第一个问题是在解决现有复制技术的局限性时讨论的。第二个驱动因素是 x 轴缩放技术无法解决数据大小或数量增加所固有的缩放问题。与第 23 章中的缓存问题一样,当您增加数据库中的数据大小时,即使在索引表中,响应时间也会增加。如果正确使用索引,这种增加并不是线性关系,但它仍然代表了响应时间和处理时间的成本。响应时间的增加最终可能会促使您进行其他拆分。在非数据库存储系统中,大量数据的存储关系的复杂性可能会促使您进行分段,以便于维护和操作。
Another drawback to x-axis replication is the cost of replicating large amounts ofdata. Typically, x-axis implementations are complete clones of a primary database,which in turn means that we might be moving lots of data that is seldom read relativeto data within the same replication set that is read frequently. A solution to this con-cern is to select only the data for replication that has a high volume of reads associ-ated with it. Many of the replication technologies for databases allow such aselection to occur on a by table basis, but to our knowledge few, if any, allow col-umns within a table to be selected.
x 轴复制的另一个缺点是复制大量数据的成本。通常,x 轴实现是主数据库的完整克隆,这反过来意味着我们可能会移动大量很少读取的数据(相对于同一复制集中经常读取的数据)。解决此问题的方法是仅选择与其关联的大量读取的数据进行复制。许多数据库复制技术允许在表的基础上进行此类选择,但据我们所知,很少有(如果有的话)允许选择表中的列。
Other drawbacks include data currency concerns, data consistency concerns, andthe reliance on third parties to scale. We addressed data currency in our earlier side-bar “Replication Delay Concerns.” Consistency is typically managed by the native orthird-party product that you choose to perform your replication and seldom in ourexperience does it create a problem even in the highest request volume products.More often, we see that the consistency manager stops replication due to some con-cern, which in turn creates a larger data currency issue. These issues are usually ableto be solved in a relatively short time frame. As for scaling through third parties, aslong as you are designing your solution such that any replication technology can sup-port your needs, you can always switch an underperforming partner out for anothercommodity solution.
其他缺点包括数据货币问题、数据一致性问题以及对第三方扩展的依赖。我们在之前的侧边栏“复制延迟问题”中讨论了数据货币。一致性通常由您选择执行复制的本机或第三方产品来管理,根据我们的经验,即使在请求量最高的产品中,它也很少会产生问题。更常见的是,我们看到一致性管理器由于某些原因而停止复制。 -cern,这反过来又造成了更大的数据货币问题。这些问题通常能够在相对较短的时间内得到解决。至于通过第三方进行扩展,只要您设计的解决方案使得任何复制技术都可以支持您的需求,您就可以随时将表现不佳的合作伙伴换成另一种商品解决方案。
Summarizing the Database X-Axis 总结数据库 X 轴
The x-axis of the AKF Database Scale Cube represents the replication of data such that workcan easily be distributed across nodes with absolutely no bias.
AKF Database Scale Cube 的 x 轴代表数据的复制,以便工作可以轻松地跨节点分布,绝对没有偏见。
X-axis implementations tend to be easy to conceptualize and typically can be implementedat relatively low cost. They are the most cost-effective way of scaling transaction growth,though they usually have limitations in the number of nodes that can be employed. They can beeasily created from a monolithic database or storage system, though there typically is anupfront cost to do so. They do not tend to significantly increase the complexity of your opera-tions or production environment.
X 轴的实现往往很容易概念化,并且通常可以以相对较低的成本实现。它们是扩展交易增长的最具成本效益的方式,尽管它们通常在可使用的节点数量方面受到限制。它们可以轻松地从整体数据库或存储系统创建,尽管这样做通常会产生前期成本。它们不会显着增加操作或生产环境的复杂性。
X-axis implementations are limited by the aforementioned replication technology limitationsand the size of data that is being replicated. In general, x-axis implementations do not scalewell with data size and growth.
X 轴的实现受到上述复制技术限制和正在复制的数据大小的限制。一般来说,x 轴实现不能随着数据大小和增长而很好地扩展。
The Y-Axis of the AKF Database Scale Cube AKF 数据库比例立方体的 Y 轴
The y-axis of the AKF Database Scale Cube represents a separation of data meaningwithin your database schema or data storage system. When discussing database scale,we are usually aligning data with a predetermined application y-axis split. The y-axissplit addresses the monolithic nature of the data architecture by separating the datainto schemas that have meaning relative to the applications performing work on thatdata or reading from that data. A pure x-axis split might have 100 instances of theexact same data with one write and 99 read instances. In a y-axis split, we might splitthe data into the same “chunks” as we split our application in Chapter 23.Thesemight be exactly the data necessary to perform such separate functions as login,logout, read profile, update profile, search profiles, browse profiles, checkout, dis-play similar items, and so on. Obviously, there might be overlap in the data such ascustomer specific data present in the login/logout functionality, as well as the updateprofile functionality. We’ll address ways to handle this later.
AKF Database Scale Cube 的 y 轴代表数据库架构或数据存储系统中数据含义的分离。在讨论数据库规模时,我们通常将数据与预定的应用程序 y 轴分割对齐。 y 轴分割通过将数据分离为相对于在该数据上执行工作或读取该数据的应用程序有意义的模式来解决数据架构的整体性质。纯 x 轴分割可能有 100 个完全相同的数据实例,其中有 1 个写入实例和 99 个读取实例。在 y 轴拆分中,我们可以将数据拆分为与第 23 章中拆分应用程序相同的“块”。这些可能正是执行登录、注销、读取配置文件、更新配置文件、搜索配置文件等单独功能所需的数据、浏览个人资料、结帐、显示类似项目等等。显然,数据可能存在重叠,例如登录/注销功能以及更新配置文件功能中存在的客户特定数据。稍后我们将讨论处理此问题的方法。
You might also consider splitting data from a “noun” perspective, rather thanleading with the y-axis services based split first. The difference here is that we thinkof how we might partition our data in a resource oriented fashion rather than in aservice (or verb) oriented fashion as in our application example. This change inapproach might lead us to put customer data in one spot, product data in another,user generated content in a third, and so on. This approach has the benefit of leverag-ing the affinity data elements often have with each other and leveraging the talents ofdatabase architects who are familiar with entity relationships within relational data-bases. The drawback of this approach is that we must either change our approach forsplitting applications to also be resource based (that is, “all services that interact withcustomer data in one application”) or suffer the consequences of not having a swimlane based application and as a result non fault isolative architecture. More to thepoint, if we split our data along resource meaningful boundaries and split our appli-cation along service meaningful boundaries, we will almost certainly have servicestalking to several resources. As we discussed in Chapter 21, this will absolutely lowerour availability, which likely runs counter to our overall company objectives. For thisreason, we strongly suggest sticking with resource oriented or services oriented splitsfor both your application and your data.
您还可以考虑从“名词”角度拆分数据,而不是首先基于 y 轴服务进行拆分。这里的区别在于,我们考虑如何以面向资源的方式分区数据,而不是像我们的应用程序示例中那样以面向服务(或动词)的方式分区数据。这种方法的改变可能会导致我们将客户数据放在一个位置,将产品数据放在另一个位置,将用户生成的内容放在第三个位置,依此类推。这种方法的优点是利用数据元素之间通常具有的亲和力,并利用熟悉关系数据库中实体关系的数据库架构师的才能。这种方法的缺点是,我们必须改变我们的应用程序分割方法,使之也基于资源(即“在一个应用程序中与客户数据交互的所有服务”),或者承受没有基于泳道的应用程序的后果。结果非故障隔离架构。更重要的是,如果我们沿着资源有意义的边界分割数据,并沿着服务有意义的边界分割我们的应用程序,我们几乎肯定会有服务与多个资源通信。正如我们在第 21 章中讨论的,这绝对会降低我们的可用性,这可能与我们公司的总体目标背道而驰。因此,我们强烈建议您的应用程序和数据坚持面向资源或面向服务的拆分。
Consistent with our past explanations of split complexities in Chapters 22 and 23,y-axis data splits are more complex than x-axis data splits. You can lower some ofthe initial cost and prove your concepts by performing splits of virtual data storage ordatabases without an actual physical split. In a database, this might be implementedby moving tables and data to a different schema or even to another database instancewithin the same physical hardware. Although this move saves you the initial capitalexpense of purchasing additional equipment, it unfortunately does not allow you toforego the engineering cost of changing your code to address different storage imple-mentations or databases. For the physical split you can, temporarily, use tools thatlink the separate physical databases together so that if your engineers missed anytables being moved they have the opportunity to fix the code before breaking theapplication. After you are sure that the application is properly accessing the movedtables, you should remove these links because they can cause a chain reaction ofdegraded performance in some instances.
与我们过去在第 22 章和第 23 章中对分割复杂性的解释一致,y 轴数据分割比 x 轴数据分割更复杂。您可以通过执行虚拟数据存储或数据库的拆分而无需进行实际的物理拆分,从而降低一些初始成本并证明您的概念。在数据库中,这可以通过将表和数据移动到不同的模式,甚至移动到同一物理硬件内的另一个数据库实例来实现。尽管这一举措为您节省了购买额外设备的初始资本支出,但遗憾的是,它并不能让您放弃更改代码以解决不同存储实现或数据库的工程成本。对于物理拆分,您可以暂时使用将单独的物理数据库链接在一起的工具,这样,如果您的工程师错过了任何被移动的表,他们就有机会在破坏应用程序之前修复代码。在确定应用程序正确访问移动的表后,您应该删除这些链接,因为它们在某些情况下可能会导致性能下降的连锁反应。
Y-axis splits are most commonly implemented to address the issues associatedwith a dataset that has grown significantly in complexity or size and which is likelyto continue to grow. These splits also help scale transaction volumes because as youperform the splits you are moving requests to multiple physical or logical systems andin turn decreasing logical and/or physical contention for the data. Ultimately, inhyper-growth environments where both the data and transaction volume grows, thesplits need to happen to separate physical instances of a database or storage on sepa-rate hardware instances.
Y 轴分割最常用于解决与复杂性或大小显着增长且可能继续增长的数据集相关的问题。这些拆分还有助于扩展事务量,因为当您执行拆分时,您会将请求移动到多个物理或逻辑系统,从而减少数据的逻辑和/或物理争用。最终,在数据和事务量都增长的高速增长环境中,需要对数据库的物理实例或单独的硬件实例上的存储进行分离。
Operationally, y-axis splits help reduce the time necessary to process any giventransaction as the data being searched and very likely retrieved is smaller and tailoredto the service performing the transaction. Conceptually, y-axis splits allow you tobetter understand vast amounts of data by thematically bundling that data, ratherthan lumping everything into the same “storage” container. Y-axis splits also aid infault isolation as identified within Chapter 21; a failure of a given data element doesnot bring down all of the functionality of your platform (assuming that you haveproperly implemented the swim lane concept).
从操作上来说,y 轴分割有助于减少处理任何给定事务所需的时间,因为正在搜索和很可能检索到的数据较小,并且是针对执行事务的服务量身定制的。从概念上讲,y 轴分割允许您通过按主题捆绑数据来更好地理解大量数据,而不是将所有内容集中到同一个“存储”容器中。 Y 轴分割也有助于故障隔离,如第 21 章中所述;给定数据元素的故障不会降低平台的所有功能(假设您已正确实现泳道概念)。
When bundled with similar splits at an application level, y-axis splits allow you togrow your team more easily by focusing teams on specific services or functionswithin your product and the data relevant to those functions and services. As dis-cussed in Chapter 23, you can dedicate a person or a team to searching and brows-ing, a team toward the development of an advertising platform, a team to accountfunctionality, and so on. All of the engineering benefits including “on boarding” andthe application of experience to a problem set discussed in Chapter 23 are realizedwhen both the data and the services acting on that data are split together.
当与应用程序级别的类似拆分捆绑在一起时,y 轴拆分可以让您的团队专注于产品中的特定服务或功能以及与这些功能和服务相关的数据,从而更轻松地发展团队。正如第 23 章所讨论的,您可以指定一个人或一个团队来搜索和浏览,一个团队来开发广告平台,一个团队来开发帐户功能,等等。当数据和作用于该数据的服务被分割在一起时,所有的工程效益,包括“入门”和将经验应用于第 23 章中讨论的问题集,都可以实现。
Y-axis splits also have drawbacks. They are absolutely more costly to implementin engineering time than x-axis splits. Not only do services need to be rewritten toaddress different data storage systems and databases, but the actual data likely needsto be moved if you have a product that has already launched. The operations andinfrastructure teams will now need to support more than one schema. This in turnmight mean that there is more than one class or size of server in the operations envi-ronment to get the most cost-efficient systems for each type of transaction.
Y 轴分割也有缺点。与 x 轴分割相比,它们在工程时间中的实施成本绝对更高。不仅需要重写服务以适应不同的数据存储系统和数据库,而且如果您有已经推出的产品,则可能需要移动实际数据。运营和基础设施团队现在需要支持不止一种模式。这反过来可能意味着操作环境中存在不止一种类型或规模的服务器,以便为每种类型的交易获得最具成本效益的系统。
Summarizing the Database Y-Axis 总结数据库 Y 轴
The y-axis of the AKF Database Scale Cube represents separation of data meaning, often byservice, resource, or data affinity.
AKF Database Scale Cube 的 y 轴代表数据含义的分离,通常按服务、资源或数据亲和力分离。
Y-axis splits are meant to address the issues associated with growth and complexity in datasize and its impact to requests or operations on that data. If implemented and architected to beconsistent with an application y-axis split, it can create fault isolation as described in Chapter 21.
Y 轴拆分旨在解决与数据大小的增长和复杂性及其对该数据的请求或操作的影响相关的问题。如果实现和架构与应用程序 y 轴分割一致,它可以创建第 21 章中所述的故障隔离。
Y-axis splits can scale with both the growth in number of transactions and the size of data.They tend to cost more than x-axis splits as the engineering team needs to rewrite servicesand determine how to move data between separate schemas and systems
Y 轴拆分可以随着事务数量和数据大小的增长而扩展。它们的成本往往比 X 轴拆分更高,因为工程团队需要重写服务并确定如何在单独的模式和系统之间移动数据
The Z-Axis of the AKF Database Scale Cube AKF 数据库比例立方体的 Z 轴
As with the Application Scale Cube, the z-axis of the AKF Database Scale Cube con-sists of splits based on values that are “looked up” or determined at the time of thetransaction. This split is most commonly performed by looking up or determining thelocation of data based on a reference to the customer or requestor. However, it canalso be applied to any split of data within a resource or service where that split isdone without a bias to affinity or theme. Examples would be a modulus or hash ofproduct number if that modulus or hash was not indicative of the product type. Forinstance, if an ecommerce company sold jewelry and decided to split its data intogroups such as watches, rings, bracelets, and necklaces, such splits would not bez-axis splits; such splits are actually y-axis splits as they are splits relevant to themesor affinity of the resource in question. On the other hand, if the company decided tosplit its product catalog by a modulus (say mod 10) of the unique product numberfor each item, and the resulting databases storing the items each had a roughly equalquantity of watches, rings, necklaces, and so on, the item would be a z-axis split.
与应用程序规模立方体一样,AKF 数据库规模立方体的 z 轴由基于“查找”或在事务时确定的值的分割组成。这种分割最常见的方式是根据对客户或请求者的引用查找或确定数据的位置。然而,它也可以应用于资源或服务内的任何数据分割,其中分割的完成不存在亲和力或主题的偏见。示例是产品编号的模数或散列,如果该模数或散列不指示产品类型。例如,如果一家电子商务公司销售珠宝并决定将其数据拆分为手表、戒指、手镯和项链等组,则此类拆分不会是 z 轴拆分;这样的分割实际上是 y 轴分割,因为它们是与相关资源的主题或亲和力相关的分割。另一方面,如果公司决定按照每件商品的唯一产品编号的模数(例如 mod 10)分割其产品目录,并且存储每个商品的数据库都包含大致相等数量的手表、戒指、项链等打开时,该项目将是 z 轴分割。
The easiest way to think of the difference between y- and z-axis splits is to differenti-ate between things that we know before a request happens and things we must look upor determine at the time of the transaction. For instance, if we were to split watchesfrom our jewelry retailer into their own database, we know that any call for watchesgoes to the watches database. On the other hand, if we split watches across severaldatabases and combine them with other pieces of jewelry by performing a modulusof the product id, we must look at the product id sent in the request, perform ourmodulus on that product id, and determine the database in which the watch is located.A similar relationship can be made to customer information. Let’s consider thecase where we split customers by geography. Technically speaking, if we predeter-mine the geographic location of a customer and that customer is always guaranteedto be in the Northwest U.S. database and we make that determination prior to therequest (say through a URL), that split is a y-axis split. However, if we make thatdetermination at the time of the request by looking up the username and determiningthe password or performing a geo-location test of the requestor IP address, we haveperformed a z-axis split. For the sake of simplicity, we usually just reduce this to themost common case that all customer based splits are z-axis splits.
考虑 y 轴和 z 轴分割之间的差异的最简单方法是区分请求发生之前我们知道的事情和我们在事务时必须查找或确定的事情。例如,如果我们要将珠宝零售商的手表拆分到他们自己的数据库中,我们知道任何对手表的调用都会进入手表数据库。另一方面,如果我们将手表拆分到多个数据库中,并通过执行产品 ID 的取模将它们与其他珠宝组合起来,则我们必须查看请求中发送的产品 ID,对该产品 ID 执行取模,并确定数据库手表所在的位置。可以对客户信息建立类似的关系。让我们考虑一下按地理位置划分客户的情况。从技术上讲,如果我们预先确定客户的地理位置,并且始终保证该客户位于美国西北部数据库中,并且我们在请求之前(例如通过 URL)做出该确定,则该分割就是 y 轴分割。但是,如果我们在请求时通过查找用户名并确定密码或对请求者 IP 地址执行地理位置测试来进行确定,那么我们就执行了 z 轴分割。为了简单起见,我们通常只是将其简化为最常见的情况,即所有基于客户的拆分都是 z 轴拆分。
As with the Application Scale Cube, for the z-axis split to be valuable, it must helpus scale our transactions and the data upon which those transactions are performed.A z-axis split attempts to accomplish the benefits of a y-axis split without a bias tothe action (service) or resource itself. In doing so, it also tends to offer a more bal-anced demand across all of your data than a y-axis split in isolation. If you assumethat each datum has a relatively equal opportunity to be in high demand, averagedemand, or low demand, and if you apply a deterministic and unbiased algorithm tostore and locate such data, you will likely get a relatively equal distribution ofdemand across all of your databases or storage systems. This is not true for the y-axissplit, which may cause certain systems to have unique demand spikes based on theircontents. For instance, the rings database may have incredibly high utilization rela-tive to the watches database during the peak wedding month of August, whereas az-axis split that implemented a modulus would spread that peak demand for ringsacross all of the databases. There might in fact be one ring with very high demand,but the more likely case is that a few rings would exhibit high demand and thosewould have a good chance of being on different databases.
与应用程序规模立方体一样,要使 z 轴拆分有价值,它必须帮助我们扩展事务以及执行这些事务的数据。z 轴拆分尝试实现 y 轴拆分的好处,而无需对操作(服务)或资源本身的偏见。这样做时,与孤立的 y 轴分割相比,它还往往可以为所有数据提供更加平衡的需求。如果您假设每个数据都有相对均等的机会处于高需求、平均需求或低需求,并且应用确定性且无偏差的算法来存储和定位此类数据,那么您可能会在所有数据中获得相对均等的需求分布。数据库或存储系统。对于 y 轴分割来说,情况并非如此,这可能会导致某些系统根据其内容出现独特的需求峰值。例如,在八月的婚礼高峰期,戒指数据库相对于手表数据库的利用率可能非常高,而实现模数的 z 轴分割会将戒指的峰值需求分散到所有数据库中。事实上可能有一个环具有非常高的需求,但更可能的情况是几个环会表现出高需求,并且这些环很有可能位于不同的数据库上。
Because we are splitting our data and as a result our transactions across multiplesystems, we can achieve a transactional scale similar to that within the x-axis. Further-more, we aren’t inhibited to the replication constraints of the x-axis because in a z-axisonly split we are not replicating any data. Unfortunately, as with the y-axis, we increaseour operational complexity somewhat as we now have many unique databases or datastorage systems; the schema or setup of these databases is similar, but the data isunique. Unlike the y-axis, we don’t likely get the benefit of splitting up our architecturein a service or resource oriented fashion. Schemas or setups are monolithic in z-axisonly implementations, though the data is segmented as with the y-axis split. Finally,there is some software cost associated with z-axis splits in that the code must be able torecognize that requests are not all equivalent. As with our application splits, very oftenan algorithm to determine where the request should be sent is created, or a lookup ser-vice is created that can determine to what system or pod a request should be sent.
因为我们正在分割数据,因此我们的交易跨多个系统,所以我们可以实现类似于 x 轴内的交易规模。此外,我们不会受到 x 轴的复制约束,因为在仅 z 轴分割中,我们不会复制任何数据。不幸的是,与 y 轴一样,我们在某种程度上增加了操作复杂性,因为我们现在拥有许多独特的数据库或数据存储系统;这些数据库的架构或设置相似,但数据是唯一的。与 y 轴不同,我们不太可能从以服务或资源为导向的方式拆分架构中获得好处。尽管数据像 y 轴分割一样被分段,但模式或设置在仅 z 轴实现中是整体的。最后,存在一些与 z 轴分割相关的软件成本,因为代码必须能够识别请求并不全部相等。与我们的应用程序拆分一样,通常会创建一个算法来确定应将请求发送到何处,或者创建一个查找服务来确定应将请求发送到哪个系统或 Pod。
The benefits of a z-axis split are that we increase fault isolation, increase transac-tional scalability, increase data scalability, and increase our ability to adequately pre-dict demand across multiple databases as our load will likely be fairly evenlydistributed. The end results we would expect from these are higher availability,greater scalability, faster transaction processing times, and a better capacity planningfunction within our organization.
z 轴拆分的好处是,我们可以增强故障隔离,提高事务可扩展性,提高数据可扩展性,并提高我们充分预测跨多个数据库的需求的能力,因为我们的负载可能相当均匀地分布。我们期望的最终结果是更高的可用性、更大的可扩展性、更快的事务处理时间以及我们组织内更好的容量规划功能。
The z-axis, however, is more costly given the need to develop new code. We alsoadd some operational complexity to our production environment; we now need tomonitor several different systems with similar code bases performing similar func-tions for different clients. Configuration files may differ as a result and systems maynot be easily moved when configured depending upon your implementation.
然而,考虑到需要开发新代码,z 轴的成本更高。我们还为我们的生产环境增加了一些操作复杂性;我们现在需要监控几个不同的系统,这些系统具有相似的代码库,为不同的客户端执行相似的功能。因此,配置文件可能会有所不同,并且根据您的实现进行配置时,系统可能无法轻松移动。
As stated in Chapter 23, because we are leveraging characteristics unique to agroup of transactions, we can also improve our disaster recovery plans by geographi-cally dispersing our services.
正如第 23 章所述,由于我们利用了一组交易的独特特征,因此我们还可以通过在地理上分散我们的服务来改进我们的灾难恢复计划。
Summarizing the Database Z-Axis 总结数据库 Z 轴
The z-axis of the AKF Database Scale Cube represents separation of work based on attributesthat are looked up or determined at the time of the transaction. Most often, these are imple-mented as splits by requestor, customer, or client, though they can also be splits within a prod-uct catalog and determined by product id or any other split that is determined and looked up atthe time of the request.
AKF Database Scale Cube 的 z 轴表示基于事务时查找或确定的属性的工作分离。大多数情况下,这些是由请求者、客户或客户以拆分的形式实现的,尽管它们也可以在产品目录中进行拆分,并由产品 ID 或在请求时确定和查找的任何其他拆分来确定。
Z-axis splits are often the most costly implementation of the three types of splits. Softwareneeds to be modified to determine where to find, operate on, and store information. Very often,a lookup service or deterministic algorithm will need to be written for these types of splits.
Z 轴分割通常是三种分割类型中成本最高的实现方式。需要修改软件以确定在哪里查找、操作和存储信息。很多时候,需要为这些类型的分割编写查找服务或确定性算法。
Z-axis splits aid in scaling transaction growth, aid in decreasing processing time by limitingthe data necessary to perform any transaction, and aid the capacity planning function by moreevenly distributing demand across systems. The z-axis is most effective at evenly scalinggrowth in customers, clients, requesters, or other data elements that can be evenly distributed.
Z 轴分割有助于扩展事务增长,通过限制执行任何事务所需的数据来帮助减少处理时间,并通过在系统之间更均匀地分配需求来帮助容量规划功能。 z 轴对于均匀扩展客户、客户、请求者或其他可以均匀分布的数据元素的增长最为有效。
Putting It All Together 把它们放在一起
You may have noticed that Chapters 22, 23, and 24 have all had similar messageswith very little deviation. That’s because the AKF Scale Cube is a very powerful andflexible tool. Of all the tools we’ve used in our consulting practice, our clients havefound it to be the most useful in figuring out how to scale their systems, databases,and even their organizations. Because it represents a common framework and lan-guage, little energy is wasted in defining what is meant by different approaches.Groups can now argue over the relative merits of an approach rather than spendingtime trying to understand how something is being split. Furthermore, teams canrather easily and quickly start applying the concepts within any of their meetingsrather than struggle with the options on how to scale something. As with Chapter 23,in this section, we will discuss how the cube can be applied to create near infinitescalability within your databases and storage systems.
你可能已经注意到,第 22 章、第 23 章和第 24 章都有类似的信息,几乎没有什么偏差。这是因为 AKF Scale Cube 是一个非常强大且灵活的工具。在我们在咨询实践中使用的所有工具中,我们的客户发现它对于弄清楚如何扩展他们的系统、数据库甚至组织来说是最有用的。因为它代表了一个共同的框架和语言,所以很少有精力被浪费在定义不同方法的含义上。现在,小组可以就一种方法的相对优点进行争论,而不是花时间试图理解某些东西是如何被分割的。此外,团队可以轻松快速地开始在任何会议中应用这些概念,而不是纠结于如何扩展某些内容的选项。与第 23 章一样,在本节中,我们将讨论如何应用多维数据集在数据库和存储系统中创建近乎无限的可扩展性。
A z-axis only implementation of the AKF Database Scale Cube has several prob-lems when implemented in isolation. Let’s assume the previous case where you makeN splits of your customer base in a jewelry ecommerce platform. Because we are onlyimplementing the z-axis here, each instance is a single virtual or physical server. If itfails for hardware or software reasons, the services for that customer or set of cus-tomers have become completely unavailable. That availability problem alone is rea-son enough for us to implement an x-axis split for each of our z-axis splits. At thevery least, we should have one additional database that we can use in the event thatour primary database for any given set of customers fails. The same holds true if thez-axis is used to split our product catalog. If we split our customer base or productcatalog N ways along the z-axis, with each of the N splits having at least 1/Nth ofour customers initially, we would put at least two “cloned” or x-axis servers in eachof the N splits. This ensures that should a server fail we still service the customers inthat pod.
AKF Database Scale Cube 的仅 z 轴实现在单独实现时存在多个问题。让我们假设之前的案例,您在珠宝电子商务平台上对客户群进行了 N 次分割。因为我们在这里只实现 z 轴,所以每个实例都是一个虚拟或物理服务器。如果由于硬件或软件原因而失败,则该客户或该组客户的服务将完全不可用。仅可用性问题就足以让我们为每个 z 轴分割实现 x 轴分割。至少,我们应该有一个额外的数据库,以便在任何给定客户组的主数据库发生故障时可以使用。如果使用 z 轴来分割我们的产品目录,同样如此。如果我们沿 z 轴将客户群或产品目录划分为 N 种方式,并且 N 种划分中的每一种最初都至少有 1/N 的客户,那么我们将在每个 N 种划分中至少放置两个“克隆”或 x 轴服务器分裂。这确保了如果服务器出现故障,我们仍然可以为该 Pod 中的客户提供服务。
It is likely more costly for us to perform continued customer or product catalogoriented splits to scale our transactions than it is to simply add databases within oneof our customer or product oriented splits. The reason for this is that each time weperform a split, we need to update our code to recognize where the split informationis or at the very least update a configuration file giving the new modulus or hash val-ues. Additionally, we need to create programs or scripts to move the data to theexpected positions within the newly split database or storage infrastructure. There-fore, in an effort to reduce overall cost of scale, we will probably implement a z-axissplit with an x-axis split within each z-axis split. We can also now perform x-axisscale within each of our z-axis splits. If a customer grows significantly in transac-tions, we can perform a cost-effective x-axis split (the addition of more replicateddatabases) within that customer’s pod.
对我们来说,执行持续的面向客户或产品目录的拆分来扩展我们的交易,比简单地在面向客户或产品的拆分中添加数据库的成本可能更高。原因是每次执行拆分时,我们都需要更新代码以识别拆分信息在哪里,或者至少更新配置文件以提供新的模数或哈希值。此外,我们需要创建程序或脚本将数据移动到新拆分的数据库或存储基础设施中的预期位置。因此,为了降低总体规模成本,我们可能会实现 z 轴分割,并在每个 z 轴分割内包含 x 轴分割。我们现在还可以在每个 z 轴分割中执行 x 轴缩放。如果客户的交易量显着增长,我们可以在该客户的 Pod 内执行经济高效的 X 轴拆分(添加更多复制数据库)。
Y-axis splits, in conjunction with z-axis splits can help us create fault isolation. Ifwe led an architectural split by splitting customers first, we could then create faultisolative swim lanes by function or resource within each of the z-axis splits. We mighthave product information in each of the z-axis splits separate from customer accountinformation and so on.
Y 轴分割与 z 轴分割相结合可以帮助我们创建故障隔离。如果我们首先通过划分客户来进行架构划分,那么我们就可以在每个 z 轴划分中按功能或资源创建故障隔离泳道。我们可能在每个 z 轴分割中都有与客户帐户信息等分开的产品信息。
The y-axis split has its own set of problems when implemented in isolation. Thefirst is similar to the problem of the z-axis split in that a single database focused on asubset of functionality results in the functionality being unavailable when the serverfails. As with the z-axis split, we are going to want to increase our availability byadding at least another cloned or x-axis server for each of our functions. We also savemoney by adding servers in an x-axis fashion for each of our y-axis splits versus con-tinuing to split along the y-axis. As with our z-axis split, it costs us engineering timeto continue to split off functionality or resources, and we likely want to spend asmuch of that time on new product functionality as possible. Rather than modifyingthe code and further deconstructing our databases, we simply add replicated data-bases into each of our y-axis splits and bypass the cost of further code modification.Of course, this assumes that we’ve already written the code to write to a single data-base and read from multiple databases.
单独实现时,y 轴分割有其自身的一系列问题。第一个类似于 z 轴拆分的问题,因为专注于功能子集的单个数据库会导致服务器故障时功能不可用。与 z 轴拆分一样,我们希望通过为每个功能添加至少另一个克隆或 x 轴服务器来提高可用性。我们还通过以 x 轴方式为每个 y 轴拆分添加服务器而不是继续沿 y 轴拆分来节省资金。与我们的 z 轴拆分一样,我们需要花费工程时间来继续拆分功能或资源,并且我们可能希望将尽可能多的时间花在新产品功能上。我们不需要修改代码并进一步解构我们的数据库,而是简单地将复制的数据库添加到每个 y 轴分割中,并绕过进一步代码修改的成本。当然,这假设我们已经编写了要写入的代码单个数据库并从多个数据库读取。
The y-axis split also does not scale as well with customer growth, product growth,or some other data elements as the z-axis split. Y-axis splits in databases help us dis-aggregate data, but they have a finite number of splits determined by the affinity ofdata and your application architecture. Take the case that you split all product infor-mation off from the rest of your data. You now have your entire product catalog sep-arated from everything else within your data architecture. You may be able toperform several y-axis splits in this area similar to our previous discussion in thischapter of splitting watches from rings, necklaces, and so on. But what happenswhen the number of rings available grows to a point that it becomes difficult for youto further split them by categories? What if the demand on a subset of rings is suchthat you need to be careful about which hardware serves them? A z-axis split canhelp out quite a bit here by allowing the rings to exist across several databases with-out regard to the type of ring. As we’ve previously indicated, the load will likely alsobe relatively uniformly distributed.
y 轴分割也不像 z 轴分割那样随着客户增长、产品增长或其他一些数据元素的扩展而扩展。数据库中的 Y 轴拆分有助于我们分解数据,但它们的拆分数量有限,具体取决于数据的亲和力和应用程序架构。以将所有产品信息与其余数据分开的情况为例。现在,您的整个产品目录与数据架构中的其他所有内容都分开了。您可以在此区域中执行多次 y 轴分割,类似于我们之前在本章中将手表与戒指、项链等分割的讨论。但是,当可用环的数量增加到您很难按类别进一步划分它们时,会发生什么?如果对环子集的需求使得您需要小心哪些硬件为它们服务怎么办? z 轴分割可以在此处提供很大帮助,因为它允许环存在于多个数据库中,而不考虑环的类型。正如我们之前指出的,负载也可能会相对均匀地分布。
As we’ve stated previously, the x-axis approach is often the easiest to implementand as such is very often the very first type of split within data architectures. It scaleswell with transactions, but very often has a limit to the number of nodes to whichyou can scale. As your transaction volume grows and the amount of data that youserve grows, you will need to implement another axis of scale. The x-axis is veryoften the first axis of scale implemented by most companies, but as the product andtransaction base grows, it typically becomes subordinate to either the y- or z-axis.
正如我们之前所说,x 轴方法通常是最容易实现的,因此通常是数据架构中的第一种分割类型。它随着事务的扩展而扩展,但通常可以扩展的节点数量受到限制。随着交易量的增长和所服务的数据量的增长,您将需要实施另一个规模轴。 x 轴通常是大多数公司实施的第一个规模轴,但随着产品和交易基础的增长,它通常会从属于 y 轴或 z 轴。
Ideally, as we indicated in Chapter 12, Exploring Architectural Principles, you willplan for at least two axes of scale even if you only implement a single axis. Planningfor y or z in addition to initially implementing an x-axis of scale is a good approach.If you find yourself in a hyper-growth situation, you will want to plan for all three. Inthis situation, you should determine a primary implementation (say a z-axis by cus-tomer), a secondary (a y-axis by functionality), and an x-axis for redundancy andtransaction growth. Then, apply a fault isolative swim lane per Chapter 21 and evena swim lane within a swim lane concept. You may swim lane your customers in a z-axis, and then swim lane each of the functions within each z-axis in a y-axis fashion.The x-axis then exists for redundancy and transaction scale. Voila! You are bothhighly available and highly scalable.
理想情况下,正如我们在第 12 章“探索架构原则”中所指出的,即使您只实现一个轴,您也将规划至少两个缩放轴。除了最初实施 x 轴尺度之外,还规划 y 或 z 轴是一个好方法。如果您发现自己处于高速增长的情况,您将需要同时规划这三个轴。在这种情况下,您应该确定主要实现(例如,客户的 z 轴)、次要实现(功能的 y 轴)和用于冗余和事务增长的 x 轴。然后,根据第 21 章应用故障隔离泳道,甚至在泳道概念内应用泳道。您可以在 z 轴上对您的客户进行泳道,然后以 y 轴方式对每个 z 轴内的每个功能进行泳道。然后,x 轴的存在是为了实现冗余和交易规模。瞧!您既具有高可用性又具有高可扩展性。
AKF Database Scale Cube Summary AKF 数据库规模多维数据集摘要
Here is a summary of the three axes of scale:
这是三个尺度轴的总结
The x-axis represents the distribution of the same data or mirroring of data across multi-ple entities. It typically relies upon replication and has a limit to how many nodes can be employed.
x 轴表示相同数据的分布或跨多个实体的数据镜像。它通常依赖于复制,并且对可以使用的节点数量有限制。
The y-axis represents the distribution and separation of the meaning of data by service, resource, or data affinity.
Y 轴表示按服务、资源或数据关联性划分的数据含义的分布和分离。
The z-axis represents distribution and segmentation of data by attributes that are looked up or determined at the time of request processing.
z 轴表示按在请求处理时查找或确定的属性进行的数据分布和分段。
Hence, x-axis splits are mirror images of data, y-axis splits separate data thematically, andz-axis splits separate data by a lookup or modulus. Often, z-axis splits happen by customer, butmay also happen by product id or some other value.
因此,x 轴分割是数据的镜像,y 轴分割按主题分离数据,z 轴分割通过查找或模数分离数据。通常,z 轴分割是由客户发生的,但也可能是由产品 ID 或其他值发生的。
Practical Use of the Database Cube 数据库多维数据集的实际使用
Let’s examine the practical use of our application cube for three unique purposes. Wewill look at the same implementations as we discussed in Chapter 23, continuingwith our fictitious company AllScale.
让我们检查一下应用程序立方体在三个独特用途中的实际用途。我们将研究与第 23 章中讨论的相同的实现,并继续我们的虚构公司 AllScale。
Ecommerce Implementation 电子商务实施
The AllScale data architects ultimately decide that the data architecture is going to beimpacted along three dimensions: transaction growth upon the databases, decisionsmade in Chapter 23 to scale the application, and growth in customers and products. Assuch, they are going to need to rely on all three axes of our AKF Application Scale Cube.
AllScale 数据架构师最终决定数据架构将受到三个维度的影响:数据库上的事务增长、第 23 章中为扩展应用程序而做出的决策以及客户和产品的增长。因此,他们将需要依赖我们 AKF Application Scale Cube 的所有三个轴。
In Chapter 23, the team decided to split functionality of the site to allow forgrowth and complexity in the application. You may recall that browsing, searching,catalog upload, inventory management, and so on, and every other verb that can beperformed without needing to know specific information about a particular cus-tomer, became a branch of functionality within the site and its own code base. Apply-ing the principles of Chapter 21, the team decides to make these swim lanes; eachswim lane needs to have data relevant to the needs of the application. The team rec-ognizes that in so doing it is changing the normal form of its data architecture andthere will be elements of data replicated throughout the architecture. It is very impor-tant that the team ensures that for any given data element there is a single “point oftruth” that holds the most current and up-to-date value for this data. Ideally, theteam limits the updates to one lane, with some form of asynchronous updates hap-pening outside of the customer transactions to update the elements in other portionsof their architecture.
在第 23 章中,团队决定拆分站点的功能,以允许应用程序的增长和复杂性。您可能还记得,浏览、搜索、目录上传、库存管理等,以及无需了解特定客户的具体信息即可执行的所有其他动词,都成为网站及其自身代码中的功能分支。根据。应用第 21 章的原则,团队决定制作这些泳道;每个泳道都需要有与应用程序需求相关的数据。该团队认识到,这样做正在改变其数据架构的正常形式,并且整个架构中将会复制数据元素。非常重要的是,团队确保对于任何给定的数据元素,都有一个“事实点”来保存该数据的最新值。理想情况下,团队将更新限制在一条通道,并在客户事务之外进行某种形式的异步更新,以更新其架构其他部分中的元素。
Per our decisions in Chapter 23, all customer information will be split into Npods, where N is a configurable number. Each of these pods will host roughly 1/Nthof our customers. This is a z-axis split of the customer base. Within each of these z-axis splits, the team is going to perform y-axis splits of the code base and the datanecessary to handle those splits. Login/logout will be its own function, checkout willbe its own function, account status and summary will be its own function, and thedata necessary to support each of these will be split appropriately with the applica-tion. No single Y lane will need to know about more than 1/Nth the customers; as aresult, caching for things like login information will be much more lightweight andmuch faster.
根据我们在第 23 章中的决定,所有客户信息都将分为 Npod,其中 N 是可配置的数字。每个 Pod 将容纳大约 1/N 的客户。这是客户群的 z 轴划分。在每个 z 轴拆分中,团队将对代码库和处理这些拆分所需的数据执行 y 轴拆分。登录/注销将是其自己的功能,结帐将是其自己的功能,帐户状态和摘要将是其自己的功能,并且支持每个功能所需的数据将根据应用程序进行适当的分割。单个 Y 通道无需了解超过 1/N 的客户;因此,诸如登录信息之类的缓存将变得更加轻量且更快。
Finally, the team applies x-axis splits everywhere to scale the number of transac-tions through any given segmentation.
最后,团队在各处应用 x 轴分割,以通过任何给定的分割来扩展交易数量。
Search causes the AllScale data and software architects some concern, so they ulti-mately decide to focus a bit of attention on this area. They are going to leverage thex-, y-, and z-axes of the scale cube to address the search needs and to make searchresults very fast for their end customers. Splitting search off alone is a y-axis split sowe will focus on the x- and z-axes next. Please reference Figure 24.2 for the discus-sion in the following paragraphs.
搜索引起了 AllScale 数据和软件架构师的一些担忧,因此他们最终决定将注意力集中在这一领域。他们将利用比例立方体的 x、y 和 z 轴来满足搜索需求,并为最终客户提供非常快速的搜索结果。单独拆分搜索是 y 轴拆分,因此接下来我们将重点关注 x 轴和 z 轴。以下段落的讨论请参考图 24.2。
The team decides to use an aggregator concept to help it make search requestsspeedy. The aggregators are responsible for growth in the number of transactions andeach is a clone of the others, creating an x-axis implementation. They ultimatelymake requests of systems that have 1/Nth of the total items for sale in a modulus ofthe product catalog, where N is the modulus applied to the product catalog. This Nway split is a z-axis split along the product id. Additionally, each N-way z-axis splithas M replicated datasets further allowing transaction growth.
该团队决定使用聚合器概念来帮助快速发出搜索请求。聚合器负责交易数量的增长,并且每个聚合器都是其他聚合器的克隆,从而创建 x 轴实现。他们最终向系统发出以产品目录模数表示的待售商品总数的 1/N 的请求,其中 N 是应用于产品目录的模数。此 Nway 分割是沿产品 id 的 z 轴分割。此外,每个 N 路 z 轴拆分有 M 个复制数据集,进一步允许交易增长。
A search request is load balanced across any one of the aggregators. That aggrega-tor in turn makes N separate requests, one to each of our N tiers of product data-bases. Each of these has 1/Nth the data (product id mod N). Each tier in turn has Mxreplicated copies of the 1/Nth the data and the request to that tier is load balanced toone of the M copies. As each N tier returns a result, the aggregator compiles the com-plete list of elements and when complete returns the ordered list to the requester.
搜索请求在任一聚合器之间进行负载平衡。该聚合器依次发出 N 个单独的请求,每个请求针对我们的 N 层产品数据库中的每一层。其中每个都有 1/N 的数据(产品 id mod N)。每个层依次具有 1/N 数据的 Mx 个复制副本,并且对该层的请求将负载平衡到 M 个副本中的一个。当每个 N 层返回一个结果时,聚合器会编译完整的元素列表,并在完成后将有序列表返回给请求者。
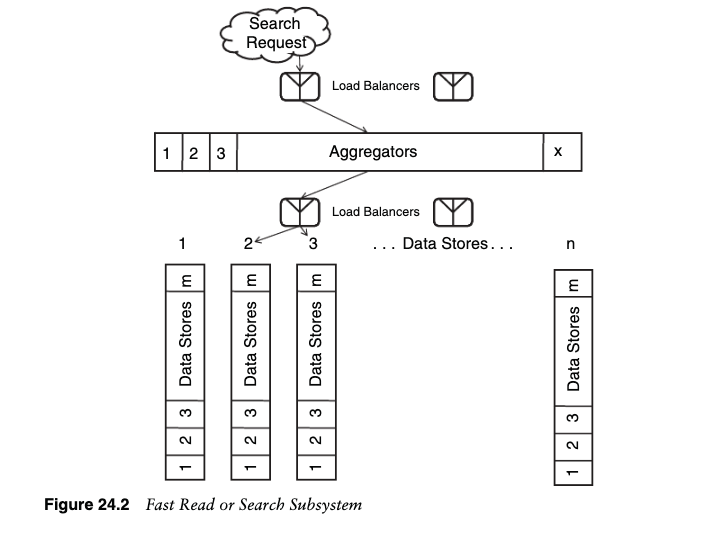
Returns from each of the N z-axis splits are very fast as the data can be kept inmemory and each database is searching only 1/Nth the data. The system is com-pletely redundant given the multiple aggregators and the M x-axis copies of each ofthe N z-axis splits. The system scales easily with transactions by adding more aggre-gators and x-axis copies of the data. If necessary, aggregators of aggregators can beadded should the aggregators need to talk to too many z-axis splits at once.
每个 N z 轴分割的返回速度非常快,因为数据可以保存在内存中,并且每个数据库仅搜索 1/N 的数据。考虑到多个聚合器和每个 N z 轴分割的 M 个 x 轴副本,该系统是完全冗余的。通过添加更多聚合器和数据的 x 轴副本,系统可以轻松扩展交易。如有必要,如果聚合器需要同时与太多 z 轴分割进行通信,则可以添加聚合器的聚合器。
Human Resources ERP Implementation 人力资源ERP实施
The AllScale HRM database architecture needs to support the decisions the teammade in Chapter 23.In Chapter 23, the architects decided that they wanted to buildwhat appeared to be one large application to their customers but with each modulecapable of growing in complexity without affecting other modules in the system. Theservice separations or y-axis splits in Chapter 23 need to have data that supportsthem so the architects will split our data up accordingly. The architects remember ouradvice to ensure that there is only one updated copy of any piece of data, with asyn-chronous updates to all copies in other tiers of data. Performance and Career Plan-ning, Learning and Education, Compliance Tracking, Recruiting, CompensationPlanning, and Succession Planning all become modules with other modules scheduledfor the future.
AllScale HRM 数据库架构需要支持团队在第 23 章中做出的决策。在第 23 章中,架构师决定他们想要构建对客户来说似乎是一个大型应用程序,但每个模块都能够在不影响其他模块的情况下增加复杂性。系统。第 23 章中的服务分离或 y 轴分割需要有支持它们的数据,以便架构师相应地分割我们的数据。架构师记住我们的建议,以确保任何数据只有一个更新的副本,并对其他数据层中的所有副本进行异步更新。绩效和职业规划、学习和教育、合规跟踪、招聘、薪酬规划和继任规划都将成为模块,并与未来计划的其他模块一起使用。
Each company has its own database, which is a z-axis split of the product, andadditionally the architects allow for employee splits within a company split. As such,companies are split in z fashion, data supporting products are split in a y fashion, andemployees within those products are split in a z fashion. This follows the architect’scode decisions from Chapter 23.Additionally, the AllScale architects employ readdatabases where necessary, which is an x-axis implementation.
每个公司都有自己的数据库,这是产品的 z 轴分割,此外,架构师还允许在公司分割内进行员工分割。因此,公司以 z 方式划分,数据支持产品以 y 方式划分,这些产品中的员工以 z 方式划分。这遵循第 23 章中架构师的代码决策。此外,AllScale 架构师在必要时使用 readdatabases,这是一个 x 轴实现。
Back Office IT System 后台IT系统
Remember the system defined in Chapter 23 that is focused on developing personal-ized marketing emails for AllScale’s current and future client base. The team decidedto split the system up by classes of data relevant to each of the existing and potentialcustomers. The team needs to ensure that mail campaigns launch and finish within afew hours so it is going to need a fairly aggressive split of the mail system given thenumber of mails that it sends.
请记住第 23 章中定义的系统,该系统专注于为 AllScale 当前和未来的客户群开发个性化营销电子邮件。该团队决定按照与每个现有和潜在客户相关的数据类别来划分系统。该团队需要确保邮件活动在几个小时内启动并完成,因此考虑到发送的邮件数量,需要对邮件系统进行相当积极的拆分。
The team’s first split was a z-axis split defined by the recency, frequency, monetiza-tion, and class of purchase as a criterion. The team had an additional split for all peo-ple for whom it has data and who did not purchase from AllScale. All told, the teamhad 199 unique splits consisting of 99 unique customer splits and 100 potential cus-tomer splits. The data for these needs to be split consistent with the z-axis splits forthe AllScale services.
该团队的第一次划分是 z 轴划分,以新近度、频率、货币化和购买类别为标准定义。该团队对拥有数据且未从 AllScale 购买产品的所有人员进行了额外的划分。总而言之,该团队有 199 个独特的细分,其中包括 99 个独特的客户细分和 100 个潜在的客户细分。这些数据的分割需要与 AllScale 服务的 z 轴分割保持一致。
In Chapter 23, the team created y-axis functional splits of its application consis-tent with the functions of the marketing system. Creative development, mail sending,mail viewing, bounce reporting, and so on all became separate Y splits within the endcustomer oriented Z splits and as such the team will need to have the data relevant tothese functions split within their databases.
在第 23 章中,团队创建了与营销系统功能一致的应用程序的 y 轴功能划分。创意开发、邮件发送、邮件查看、退回报告等都成为面向最终客户的 Z 分割中单独的 Y 分割,因此团队需要在其数据库中分割与这些功能相关的数据。
The team needs to ensure that each of the databases is highly available so at thevery least it will make a single x-axis split or replicated copy of each of the databasesidentified earlier.
团队需要确保每个数据库都具有高可用性,因此至少会对之前确定的每个数据库进行单个 x 轴拆分或复制副本。
Observations 观察结果
We’ve twice now discussed when to use which axis of scale. We discussed it first inthe “Observations” section of Chapter 23 and again earlier in this chapter after wediscussed each of the axes. The next obvious question you are probably asking is“When do I decide to allow the application considerations to lead my architecturaldecisions and when do I decide to allow the data concerns to drive my decisions?”
我们已经两次讨论了何时使用哪个比例轴。我们首先在第 23 章的“观察”部分讨论了它,并在本章早些时候讨论了每个轴之后再次讨论了它。您可能会问的下一个明显问题是“我什么时候决定让应用程序考虑因素引导我的架构决策以及我什么时候决定让数据问题驱动我的决策?
The answer to that question is not an easy one, and again we refer back to the“Art” portion of our title. In some situations, the decision is easier to make, such asthe decision within data warehousing discussions. Data warehouses are most oftensplit by data concerns, though this is not always the case. The real question to ask is“What portion of my architecture most limits my scale?”
这个问题的答案并不容易,我们再次参考标题中的“艺术”部分。在某些情况下,决策更容易做出,例如数据仓库讨论中的决策。数据仓库最常因数据问题而分裂,尽管情况并非总是如此。真正要问的问题是“我的架构的哪一部分最限制我的规模?
You may have a low transaction, low data growth environment, but an applicationthat is very complex. An example may be encryption or cipher breaking systems. Here,the application likely needs to be broken up into services to allow specialists to developthe systems in question effectively. Alternatively, you may have a system such as a contentsite where the data itself (the content) is the thing that drives most of your scale concerns,and as such you would likely design your architecture around the data concerns.
您可能拥有低事务、低数据增长的环境,但应用程序非常复杂。一个例子可以是加密或密码破解系统。在这里,应用程序可能需要分解为服务,以便专家能够有效地开发相关系统。或者,您可能有一个诸如内容网站之类的系统,其中数据本身(内容)是驱动您大部分规模问题的因素,因此您可能会围绕数据问题设计您的架构。
If you are a site with transaction growth, complexity growth, and growth in data,you will probably switch between application leading design and database leadingdesign to meet your needs. You choose the one that is most limiting for any givenarea and allow it to lead your architectural efforts. The most mature teams see themas one holistic system.
如果您的网站交易量增长、复杂性增长、数据增长,您可能会在应用程序主导设计和数据库主导设计之间切换来满足您的需求。您可以选择对任何给定区域限制最大的一个,并让它来引导您的架构工作。最成熟的团队将主题视为一个整体系统。
Timeline Considerations 时间线考虑因素
One of the most common questions we get asked is, “When do I perform an x-axissplit, and when should I consider y- and z-axis splits?” Put simply, the question reallyaddresses whether there is an engineered maturity to the process of the AKF ScaleCube. In theory, there is no general timeline for these splits, but in implementation,most companies follow a similar path.
我们最常见的问题之一是,“我什么时候执行 x 轴分割,什么时候应该考虑 y 轴和 z 轴分割?”简而言之,问题实际上涉及 AKF ScaleCube 流程是否达到设计成熟度。理论上,这些拆分没有通用的时间表,但在实施中,大多数公司都遵循类似的路径。
Ideally, a technology or architecture team would select the right axes of scale forits data and transaction growth needs and implement them in a cost-effective manner.Systems with high transaction rates, low data needs, and a high read to write ratioare probably most cost effectively addressed with an x-axis split. Such a system orcomponent may never need more than simple replication in both the data tier and thesystems tier. Where customer data growth, complex functionality, and high transac-tion growth intersect, a company may need to perform all three axes.
理想情况下,技术或架构团队会根据其数据和交易增长需求选择正确的规模轴,并以经济高效的方式实施它们。具有高交易率、低数据需求和高读写比率的系统可能是成本最高的通过x轴分割有效解决了这个问题。这样的系统或组件可能只需要在数据层和系统层中进行简单的复制。当客户数据增长、复杂功能和高交易增长交叉时,公司可能需要执行所有三个轴。
In practice, what typically happens is that a technology team will find itself in abind and need to do something quickly. Most often, x-axis splits are easiest to imple-ment in terms of time and overall cost. The team will rush to this implementation,and then start to look for other paths. Y- and z-axis splits tend to follow, with yimplementations tending to be more common as a second step than z implementa-tions, due to the conceptual ease of splitting functions within an application.
在实践中,通常发生的情况是技术团队会发现自己陷入困境,需要快速采取行动。大多数情况下,就时间和总体成本而言,x 轴分割最容易实现。团队会急于实现这一点,然后开始寻找其他路径。 Y 轴和 z 轴拆分往往随之而来,由于在应用程序中拆分功能的概念很容易,因此 y 实现往往比 z 实现更常见作为第二步。
Our recommendation is to design your systems with all of the axes in mind. At thevery least, make sure that you are not making decisions that will preclude you fromeasily splitting customers or functions in the future. Attempt to implement your prod-uct with x-axis splits for both the application and the database and have designsavailable to split the application and data by both functions and customers. In thisfashion, you can rapidly scale should demand take off without struggling to keep upwith the needs of your end users.
我们的建议是在设计系统时考虑所有轴。至少,确保您做出的决策不会妨碍您将来轻松拆分客户或职能。尝试通过应用程序和数据库的 x 轴拆分来实现您的产品,并提供可按功能和客户拆分应用程序和数据的设计。通过这种方式,您可以在需求起飞时快速扩展,而无需努力跟上最终用户的需求。
Conclusion 结论
This chapter discussed the employment of the AKF Scale Cube to databases and dataarchitectures within a product, service, or platform. We modified the AKF Scale Cubeslightly, narrowing the scope and definition of each of the axes so that it becamemore meaningful to databases and data architecture.
本章讨论了 AKF Scale Cube 在产品、服务或平台内的数据库和数据架构中的应用。我们稍微修改了 AKF Scale Cubes,缩小了每个轴的范围和定义,使其对数据库和数据架构变得更有意义。
Our x-axis still addresses the growth in transactions or work performed by anyplatform or system. Although the x-axis handles the growth in transaction volumewell, it suffers by the limitations of replication technology and does not handle datagrowth well.
我们的 x 轴仍然涉及任何平台或系统执行的交易或工作的增长。尽管x轴可以很好地处理交易量的增长,但它受到复制技术的限制,不能很好地处理数据增长。
The y-axis addresses data growth as well as transaction growth. Unfortunately, itdoes not distribute demand well across databases as it focuses on data affinity. Assuch, we will often get irregular demand characteristics, which might make capacitymodeling difficult and will likely result in x- or z-axis splits.
Y 轴表示数据增长和交易增长。不幸的是,它不能很好地跨数据库分配需求,因为它专注于数据亲和力。因此,我们经常会得到不规则的需求特征,这可能会使容量建模变得困难,并可能导致 x 或 z 轴分裂。
The z-axis addresses growth in data and is most often related to customer growthor inventory element (product) growth. Z-axis splits have the ability to more evenlydistribute demand (or load) across a group of systems.
z 轴解决数据增长问题,通常与客户增长或库存元素(产品)增长相关。 Z 轴拆分能够在一组系统之间更均匀地分配需求(或负载)。
Not all companies need all three axes of scale to survive. When more than one axisis employed, the x-axis is almost subordinate to the other axes. You might, forinstance, have multiple x-axis splits, each occurring within a y- or z-axis split. Ideally,all such splits occur in relationship to application splits with either the application orthe data being the reason for making a split.
并非所有公司都需要规模的所有三个轴才能生存。当使用多个轴时,x 轴几乎从属于其他轴。例如,您可能有多个 x 轴分割,每个分割都发生在 y 轴或 z 轴分割内。理想情况下,所有此类拆分都与应用程序拆分相关,应用程序或数据是进行拆分的原因。
Key Points 关键点
X-axis database splits scale linearly with transaction growth but usually havepredetermined limits as to the number of splits allowed. They do not help withthe growth in customers or data. X-axis splits are mirrors of each other.
X 轴数据库拆分随事务增长线性扩展,但通常对允许的拆分数量有预先确定的限制。它们无助于客户或数据的增长。 X 轴分割是彼此的镜像。
The x-axis tends to be the least costly to implement.
x 轴的实施成本往往是最低的。
Y-axis database splits help scale data as transaction growth. They are mostlymeant for data scale because in isolation they are not as effective as the x-axis intransaction growth.
Y 轴数据库拆分有助于随着事务的增长扩展数据。它们主要用于数据规模,因为孤立地看,它们在交易增长方面不如 x 轴那么有效。
Y-axis splits tend to be more costly to implement than x-axis splits as a result ofengineering time necessary to separate monolithic databases.
由于分离整体数据库所需的工程时间,Y 轴拆分的实施成本往往比 X 轴拆分更高。
Y-axis splits aid in fault isolation.
Y 轴分割有助于故障隔离。
Z-axis application splits help scale transaction and data growth.
Z 轴应用程序拆分有助于扩展事务和数据增长。
Z-axis splits allow for more even demand or load distribution than most y-axissplits.
Z 轴分割比大多数 y 轴分割允许更均匀的需求或负载分配。
As with y-axis splits, z-axis splits aid in fault isolation.
与 y 轴分割一样,z 轴分割有助于故障隔离。
The choice of when to use what method or axis of scale is both art and scienceas is the decision of when to use an application leading architecture split or adata leading architecture split.
选择何时使用何种方法或尺度轴既是一门艺术,也是一门科学,就像决定何时使用应用主导架构拆分或数据主导架构拆分一样。
已有 4 条评论
你的文章让我感受到了无尽的欢乐,谢谢分享。 https://www.yonboz.com/video/21995.html
《梦洒满乡》喜剧片高清在线免费观看:https://www.jgz518.com/xingkong/42170.html
你的文章内容非常精彩,让人回味无穷。 http://www.55baobei.com/hDSh3Eqiw8.html
《妲己不是坏狐狸 漫动画第二季》国产动漫高清在线免费观看:https://www.jgz518.com/xingkong/48487.html