这篇文章上次修改于 300 天前,可能其部分内容已经发生变化,如有疑问可询问作者。
Chapter 26 Asynchronous Design for Scale 第26章 规模化异步设计
In all fighting, the direct method may be used for joining battle,but indirect methods will be needed in order to secure victory.—Sun Tzu
一切战斗,可以用直接的方法来加入战斗,但必须使用间接的方法才能获得胜利。——孙子
This last chapter in Part III, Architecting Scalable Solutions, will address an oftenoverlooked problem when developing services or product—that is, overlooked untilit becomes a noticeable and costly inhibitor to scaling. This problem is the use of syn-chronous calls in the application. We will explore the reasons that most developers over-look asynchronous calls as a scaling principle and how converting synchronous calls toasynchronous ones can greatly improve the scalability and availability of the system.
第三部分“构建可扩展解决方案”的最后一章将解决开发服务或产品时经常被忽视的问题,即,一直被忽视,直到它成为可扩展的明显且成本高昂的阻碍因素。这个问题是在应用程序中使用同步调用造成的。我们将探讨大多数开发人员忽视异步调用作为扩展原则的原因,以及将同步调用转换为异步调用如何能够极大地提高系统的可扩展性和可用性。
We will explore the use of state in applications including why it is used, how it isoften used, why it can be problematic, and how to make the best of it when neces-sary. Examining the need for state and eliminating it where possible will pay hugedividends within your architecture if it is not already a problem. If it already is aproblem in your system, this chapter will give you some tools to fix it.
我们将探讨状态在应用程序中的使用,包括为什么使用它、如何经常使用它、为什么它会出现问题,以及如何在必要时充分利用它。检查状态需求并在可能的情况下消除它,如果状态还不是问题的话,将为您的架构带来巨大的好处。如果你的系统已经出现问题,本章将为你提供一些修复它的工具。
Synching Up on Synchronization 同步上同步
Let’s start our discussion by covering some of the basics of synchronization, startingwith a definition and some different types of synchronization methods. The processof synchronization refers to the use and coordination of simultaneously executedthreads or processes that are part of an overall task. These processes must run in thecorrect order to avoid a race condition or erroneous results. Stated another way, syn-chronization is when two or more pieces of work must be in a specific order toaccomplish a task. An example is a login task. First, the user’s password must beencrypted; then it must be compared against the encrypted version in the database;then the session data must be updated marking the user as authenticated; then thewelcome page must be generated; and finally the welcome page must be presented. Ifany of those pieces of work are done out of order, the task of logging the user in failsto get accomplished.
让我们从同步的一些基础知识开始讨论,从定义和一些不同类型的同步方法开始。同步过程是指作为整体任务一部分的同时执行的线程或进程的使用和协调。这些进程必须以正确的顺序运行,以避免竞争条件或错误结果。换句话说,同步是指两个或多个工作必须按特定顺序才能完成一项任务。一个例子是登录任务。首先,用户的密码必须加密;然后必须将其与数据库中的加密版本进行比较;然后必须更新会话数据,将用户标记为已通过身份验证;那么必须生成欢迎页面;最后必须呈现欢迎页面。如果其中任何一项工作没有按顺序完成,则用户登录的任务就无法完成。
There are many types of synchronization processes that take place in program-ming. One that all developers should be familiar with is the mutex or mutual exclu-sion. Mutex refers to how global resources are protected from concurrently runningprocesses to ensure only one process is updating or accessing the resource at a time.This is often accomplished through semaphores, which is kind of a fancy flag. Sema-phores are variables or data types that mark or flag a resource as being in use or free.Another classic synchronization method is known as thread join. Thread join is whena process is blocked from executing until a thread terminates. After the thread termi-nates, the other process is free to continue. An example would be for a parent pro-cess, such as a “look up,” to start executing. The parent process kicks off a childprocess to retrieve the location of the data that it is going to look up, and this childthread is “joined.” This means that the parent process cannot complete until thechild process terminates.
编程中发生多种类型的同步过程。所有开发人员都应该熟悉互斥体或互斥体。互斥是指如何保护全局资源免受同时运行的进程的影响,以确保一次只有一个进程正在更新或访问资源。这通常是通过信号量来完成的,信号量是一种奇特的标志。信号量是标记资源正在使用或空闲的变量或数据类型。另一种经典的同步方法称为线程连接。线程连接是指进程被阻止执行,直到线程终止。线程终止后,其他进程可以自由地继续。一个例子是父进程(例如“查找”)开始执行。父进程启动一个子进程来检索它将要查找的数据的位置,并且该子线程被“加入”。这意味着父进程在子进程终止之前无法完成。
Dining Philosophers Problem 哲学家就餐问题
This analogy is credited to Sir Charles Anthony Richard Hoare (a.k.a. Tony Hoare), as in theperson who invented the Quicksort algorithm. This analogy is used as an illustrative example ofresource contention and deadlock. The story goes that there were five philosophers sittingaround a table with a bowl of spaghetti in the middle. Each philosopher had a fork to his left,and therefore each had one to his right. The philosophers could either think or eat, but not both.Additionally, in order to serve and eat the spaghetti, each philosopher required the use of twoforks. Without any coordination, it is possible that all the philosophers pick up their forks simul-taneously and therefore no one has two forks in which to serve or eat.
这个类比归功于查尔斯?#23433;东尼?#29702;查德?#38669;尔爵士(又名托尼?#38669;尔),他是快速排序算法的发明者。这个类比被用作资源争用和死锁的说明性示例。故事是这样的:有五位哲学家围坐在一张桌子旁,桌子中间放着一碗意大利面。每个哲学家的左边都有一把叉子,因此每个哲学家的右边都有一把叉子。哲学家可以思考或吃东西,但不能两者兼而有之。此外,为了盛放和吃意大利面,每个哲学家都需要使用两把叉子。如果没有任何协调,所有哲学家都可能同时拿起他们的叉子,因此没有人有两把叉子来服务或吃饭。
This analogy is used to show that without synchronization the five philosophers couldremain stalled indefinitely and starve just as five computer processes waiting for a resourcecould all enter into a deadlocked state. There are many ways to solve such a dilemma. One isto have a rule that each philosopher when reaching a deadlock state will place his fork down,freeing up a resource, and think for a random time. If this solution sounds familiar, it might bebecause it is the basic idea of retransmission that takes place in the Transmission Control Pro-tocol (TCP). When no acknowledgement for data is received, a timer is started to wait for aretry. The amount of time is adjusted by the smoothed round trip time algorithm and doubledafter each unsuccessful retry.
这个类比用于表明,如果没有同步,五位哲学家可能会无限期地停滞并挨饿,就像等待资源的五个计算机进程可能全部进入死锁状态一样。有很多方法可以解决这种困境。其中之一是制定一条规则,即每个哲学家在达到僵局状态时都会放下他的叉子,释放资源,并随机思考一段时间。如果这个解决方案听起来很熟悉,那可能是因为它是传输控制协议 (TCP) 中发生的重传的基本思想。当没有收到数据确认时,启动定时器等待重试。时间量通过平滑往返时间算法进行调整,并在每次不成功的重试后加倍。
As you might expect, there are many other types of synchronization processes andmethods that are employed in programming. We’re not presenting an exhaustive listbut rather attempting to give you an overall understanding that synchronization isused throughout programming in many different ways. Eliminating synchronizationis not possible, nor would it be advisable. It is, however, prudent to understand thepurpose and cost of synchronization so that when you use it you do so wisely.
正如您所料,编程中还使用了许多其他类型的同步过程和方法。我们并不是提供详尽的列表,而是试图让您全面了解同步在整个编程过程中以多种不同的方式使用。消除同步是不可能的,也不可取。然而,明智的做法是了解同步的目的和成本,以便在使用它时明智地使用它。
Synchronous Versus Asynchronous Calls 同步调用与异步调用
Now that we have a basic definition and some examples of synchronization, we canmove on to a broader discussion of synchronous versus asynchronous calls within theapplication. Synchronous calls perform their action completely by the time the callreturns. If a method is called and control is given to this method to execute, the pointin the application that made the call is not given control back until the method hascompleted its execution and returned either successfully or with an error. In otherwords, synchronous methods are called, they execute, and when they finish, you getcontrol back. As an example of a synchronous method, let’s look at a method calledquery_exec from AllScale’s human resource management (HRM) service. Thismethod is used to build and execute a dynamic database query. One step in thequery_exec method is to establish a database connection. The query_exec methoddoes not continue executing without explicit acknowledgement of successful comple-tion of this database connection task. Doing so would be a waste of resources andtime. If the database is not available, the application should not waste time creatingthe query and waiting for it to become available. Indeed, if the database is not avail-able, the team should reread Chapter 24, Splitting Databases for Scale, on how toscale the database so that there is improved availability. Nevertheless, this is anexample of how synchronous calls work. The originating call is halted and notallowed to complete until the invoked process returns.
现在我们有了同步的基本定义和一些示例,我们可以继续更广泛地讨论应用程序中的同步与异步调用。同步调用在调用返回时完全执行其操作。如果调用某个方法并将控制权交给该方法来执行,则在该方法完成其执行并成功返回或返回错误后,应用程序中发出调用的点才会获得控制权。换句话说,同步方法被调用、执行,当它们完成时,您将获得控制权。作为同步方法的示例,让我们看一下 AllScale 人力资源管理 (HRM) 服务中名为 query_exec 的方法。该方法用于构建和执行动态数据库查询。 query_exec 方法中的一步是建立数据库连接。如果没有明确确认此数据库连接任务成功完成,query_exec 方法不会继续执行。这样做会浪费资源和时间。如果数据库不可用,应用程序不应浪费时间创建查询并等待它变得可用。事实上,如果数据库不可用,团队应该重新阅读第 24 章,拆分数据库以实现扩展,了解如何扩展数据库以提高可用性。尽管如此,这是同步调用如何工作的一个示例。原始调用将停止,并且在调用的进程返回之前不允许完成。
A nontechnical example of synchronicity is communication between two individu-als either in a face-to-face fashion or over a phone line. If both individuals areengaged in meaningful conversation, there is not likely to be any other action goingon. One individual cannot easily start another conversation with another individualwithout first stopping the conversation with the first person. Phone lines are heldopen until one or both callers terminate the call.
同步性的一个非技术示例是两个人之间以面对面方式或通过电话线进行的通信。如果两个人都进行有意义的对话,则不太可能发生任何其他行动。如果不先停止与第一个人的对话,一个人就无法轻易地与另一个人开始另一次对话。电话线路将保持开放状态,直到呼叫者之一或双方终止呼叫。
Contrast the synchronous methods or threads with an asynchronous method.With an asynchronous method call, the method is called to execute in a new thread,and it immediately returns control back to the thread that called it. The design pat-tern that describes the asynchronous method call is known as the asynchronousdesign, or the asynchronous method invocation (AMI). The asynchronous call con-tinues to execute in another thread and terminates either successfully or with errorwithout further interaction with the initiating thread. Let’s turn back to our AllScaleexample with the query_exec method. After calling synchronously for the databaseconnection, the method needs to prepare and execute the query. In the HRM system,AllScale has a monitoring framework that allows them to note the duration and suc-cess of all queries by asynchronously calling a method for start_query_time andend_query_time. These methods store a system time in memory and wait for the endcall to be placed in order to calculate duration. The duration is then stored in a mon-itoring database that can be queried to understand how well the system is performingin terms of query run time. Monitoring the query performance is important but notas important as actually servicing the users’ requests. Therefore, the calls to the mon-itoring methods of start_query_time and end_query_time are done asynchronously. Ifthey succeed and return, great—AllScale’s operations and engineering teams get thequery time in the monitoring database. If the monitoring calls fail or get delayed for20 seconds waiting on the monitoring database connection, they don’t care. The userquery continues on without any concern over the asynchronous calls.
将同步方法或线程与异步方法进行对比。通过异步方法调用,方法被调用并在新线程中执行,并且它立即将控制权返回给调用它的线程。描述异步方法调用的设计模式称为异步设计或异步方法调用 (AMI)。异步调用继续在另一个线程中执行,并成功或错误地终止,而无需与发起线程进行进一步交互。让我们回到带有 query_exec 方法的 AllScale 示例。同步调用数据库连接后,该方法需要准备并执行查询。在HRM系统中,AllScale有一个监控框架,允许他们通过异步调用start_query_time和end_query_time方法来记录所有查询的持续时间和成功情况。这些方法将系统时间存储在内存中,并等待结束调用以计算持续时间。然后,持续时间存储在监控数据库中,可以查询该数据库以了解系统在查询运行时间方面的执行情况。监控查询性能很重要,但不如实际服务用户的请求那么重要。因此,对start_query_time和end_query_time的监控方法的调用是异步完成的。如果他们成功并返回,那就太棒了 - AllScale 的运营和工程团队可以在监控数据库中获取查询时间。如果监控调用失败或在等待监控数据库连接时延迟 20 秒,他们也不在乎。用户查询继续进行,而不关心异步调用。
Returning to our communication example, email is a great example of asynchro-nous communication. You write an email and send it, immediately moving on toanother task, which may be another email, a round of golf, or whatever. When theresponse comes in, at an appropriate time, you read the response and potentiallyissue yet another email in response. The communication chain blocks neither thesender nor receiver for anything but the time to process the communication and issuea response.
回到我们的通信示例,电子邮件是异步通信的一个很好的例子。您写了一封电子邮件并发送,然后立即转到另一项任务,这可能是另一封电子邮件、一轮高尔夫球或其他任何事情。当收到回复时,您会在适当的时间阅读该回复,并可能会发出另一封电子邮件作为回复。除了处理通信和发出响应的时间之外,通信链不会阻止发送者和接收者进行任何操作。
Scaling Synchronously or Asynchronously 同步或异步缩放
Now we understand the difference between synchronous and asynchronous calls.Why does this matter? The answer lies in scalability. Synchronous calls, if used exces-sively or incorrectly, cause undue burden on the system and prevent it from scaling.Let’s continue with our query_exec example where we were trying to execute a user’squery. If we had implemented the two monitoring calls synchronously using therationale that (1) monitoring is important, (2) the monitoring methods are veryquick, and (3) even if we slow down a user query what’s the worst that could happen.These are all good intentions, but they are wrong. As we stated earlier, monitoring isimportant but it is not more important than returning a user’s query. The monitoringmethods might be very quick, when the monitoring database is operational, but whathappens when it has a hardware failure and is inaccessible? The monitoring queriesback up waiting to time out. This means the users’ queries are blocked waiting forcompletion of the monitoring queries and are in turn backed up. When the user que-ries are slowed down or temporarily halted waiting for a time out, it is still taking upa database connection on the user database and is still consuming memory on theapplication server trying to execute this thread. As more and more user threads startstalling waiting for their monitoring calls to time out, the user database might runout of connections preventing other nonmonitored queries from executing, and thethreads on the app servers get written to disk to free up memory, which causes swap-ping on the app servers. This swapping in turn slows down all processing and mayresult in the TCP stack of the app server reaching some maximum limit and refusingsubsequent connections. Ultimately, new user requests are not processed and users sitwaiting for browser or application timeouts. Your application or platform is essen-tially “down.” As you see, this ugly chain of events can quite easily occur because ofa simple oversight on whether a call should be synchronous or asynchronous. Theworst thing about this scenario is the root cause can be elusive. As we step throughthe chain it is relatively easy to follow but when the symptoms of a problem are thatyour system’s Web pages start loading slowly and over the next 15 minutes this con-tinues to get worse and worse until finally the entire system grinds to a halt, diagnos-ing the problem can be very difficult. Hopefully, you have sufficient monitoring inplace to help you diagnose these types of problems, but these extended chains ofevents can be very daunting to unravel when your site is down and you are frantic toget it back into service.
现在我们了解了同步调用和异步调用之间的区别。为什么这很重要?答案在于可扩展性。同步调用如果使用过度或不正确,会给系统造成过度的负担并阻止其扩展。让我们继续我们的 query_exec 示例,其中我们尝试执行用户的查询。如果我们使用以下理由同步实现两个监控调用:(1) 监控很重要,(2) 监控方法非常快,(3) 即使我们减慢用户查询的速度,最糟糕的情况也会发生。这些都是意图是好的,但他们错了。正如我们之前所说,监控很重要,但并不比返回用户的查询更重要。当监控数据库运行时,监控方法可能非常快,但是当它出现硬件故障并且无法访问时会发生什么?监控查询备份等待超时。这意味着用户的查询将被阻止,等待监控查询完成并依次备份。当用户查询减慢或暂时停止等待超时时,它仍然占用用户数据库上的数据库连接,并且仍然消耗尝试执行该线程的应用程序服务器上的内存。随着越来越多的用户线程开始停滞等待其监视调用超时,用户数据库可能会耗尽连接,从而阻止其他非监视查询的执行,并且应用程序服务器上的线程会写入磁盘以释放内存,这会导致交换 ping在应用程序服务器上。这种交换反过来会减慢所有处理速度,并可能导致应用服务器的 TCP 堆栈达到某个最大限制并拒绝后续连接。最终,新的用户请求不会得到处理,用户会等待浏览器或应用程序超时。您的应用程序或平台基本上“宕机”了。正如您所看到的,由于对调用应该是同步还是异步的简单监督,这种丑陋的事件链很容易发生。这种情况最糟糕的是根本原因可能难以捉摸。当我们逐步浏览整个链条时,相对容易理解,但当问题的症状是系统的网页开始加载缓慢,并且在接下来的 15 分钟内,情况会变得越来越糟,直到最后整个系统停止运行。 ,诊断问题可能非常困难。希望您有足够的监控来帮助您诊断这些类型的问题,但是当您的网站关闭并且您急于使其恢复服务时,这些扩展的事件链可能会非常令人畏惧。
Despite the fact that synchronous calls can be problematic if used incorrectly orexcessively, method calls are very often done synchronously. Why is this? The answeris that synchronous calls are simpler than asynchronous calls. “But wait!” you say.“Yes, they are simpler but often times our methods require that the other methodsinvoked do successfully complete and therefore we can’t put a bunch of asynchro-nous calls in our system.” Ah, yes; good point. There are many times when you doneed an invoked method to complete and you need to know the status of that inorder to continue along your thread. We are not going to tell you that all synchro-nous calls are bad; in fact, many are necessary and make the developer’s life a thou-sand times less complicated. However, there are times when asynchronous calls canand should be used in place of synchronous calls, even when there is dependency asdescribed earlier. If the main thread could care less whether the invoked thread fin-ishes, such as with the monitoring calls, a simple asynchronous call is all that isrequired. If, however, you require some information from the invoked thread, butyou don’t want to stop the primary thread from executing, there are ways to use call-backs to retrieve this information. An in-depth discussion of callbacks are beyond thescope of this chapter. An example of callback functionality is interrupt handlers inoperating systems that report on hardware conditions.
尽管如果使用不正确或过度,同步调用可能会出现问题,但方法调用通常是同步完成的。为什么是这样?答案是同步调用比异步调用更简单。 “可是等等!” “是的,它们更简单,但通常我们的方法要求调用的其他方法成功完成,因此我们不能在我们的系统中放置一堆异步调用。”是啊;好点子。很多时候,当您完成了一个调用的方法来完成时,您需要知道该方法的状态才能继续您的线程。我们不会告诉你所有的同步调用都是不好的;事实上,许多都是必要的,并且可以使开发人员的生活变得简单一千倍。然而,有时可以并且应该使用异步调用来代替同步调用,即使存在如前所述的依赖性。如果主线程不太关心被调用的线程是否完成,例如监视调用,则只需要一个简单的异步调用。但是,如果您需要来自调用线程的一些信息,但又不想停止主线程的执行,则可以使用回调来检索此信息。对回调的深入讨论超出了本章的范围。回调功能的一个示例是报告硬件状况的操作系统中的中断处理程序。
Asynchronous Coordination 异步协调
Asynchronous coordination and communication between the original method and the invokedmethod requires a mechanism that the original method determines when or if a called methodhas completed executing. Callbacks are methods passed as an argument to other methodsand allow for the decoupling of different layers in the code.
原始方法和被调用方法之间的异步协调和通信需要一种机制,由原始方法确定被调用方法何时或是否完成执行。回调是作为参数传递给其他方法的方法,并允许解耦代码中的不同层。
In C/C
- , this is done through function pointers; in Java, it is done through object refer-ences. There are many design patterns that use callbacks, such as the delegate design patternand the observer design pattern. The higher level process acts as a client of the lower level andcalls the lower level method by passing it by reference. An example of what a callback methodmight be invoked for would be an asynchronous event like file system changes.
在C/C
- 中,这是通过函数指针完成的;在Java中,它是通过对象引用来完成的。有许多使用回调的设计模式,例如委托设计模式和观察者设计模式。较高级别的进程充当较低级别的客户端,并通过引用传递来调用较低级别的方法。回调方法可能被调用的一个例子是像文件系统更改这样的异步事件。
In the .NET Framework, the asynchronous communication is characterized by the use ofBeginBlah, where Blah is the name of the synchronous version of the method. There are fourways to determine if an asynchronous call has been completed: first is polling (the IsCompletedproperty), second is a callback Delegate, third is the AsyncWaitHandle to wait on the call to com-plete, and fourth the EndBlah, which waits on the call to complete.
在.NET Framework中,异步通信的特点是使用BeginBlah,其中Blah是该方法的同步版本的名称。有四种方法可以确定异步调用是否已完成:第一个是轮询(IsCompleted 属性),第二个是回调 Delegate,第三个是 AsyncWaitHandle 等待调用完成,第四个是 EndBlah,它等待调用即可完成。
Different languages offer different solutions to the asynchronous communication and coordi-nation problem. Understand what your language and frameworks offer so that you can imple-ment them when needed.
不同的语言为异步通信和协调问题提供了不同的解决方案。了解您的语言和框架提供什么,以便您可以在需要时实施它们。
In the preceding paragraph, we said that synchronous calls are simpler than asyn-chronous calls and therefore they get used an awful lot more often. Although this iscompletely true, it is only part of the reason that engineers don’t pay enough atten-tion to the impact of synchronous calls. The second part of the problem is that devel-opers typically only see a small portion of the application. Very few people in theorganization get the advantage of viewing the application in total from a higher levelperspective. Your architects should certainly be looking at this level, as should someof your management team. These are the people that you will have to rely on to helpchallenge and explain how synchronization might cause scaling issues.
在上一段中,我们说过同步调用比异步调用更简单,因此它们的使用频率要高得多。尽管这完全正确,但这只是工程师没有对同步调用的影响给予足够重视的部分原因。问题的第二部分是开发人员通常只能看到应用程序的一小部分。组织中很少有人能够从更高层次的角度整体查看应用程序。您的架构师当然应该关注这个级别,您的一些管理团队也应该如此。您必须依靠这些人来帮助挑战并解释同步如何可能导致扩展问题。
Example Asynchronous Systems 异步系统示例
To fully understand how synchronous calls can cause scaling issues and how you caneither design from the start or convert a system in place to use asynchronous calls, weshall invoke an example system that we can explore. The system that we are going todiscuss is taken from an actual client implementation that we reviewed in our advi-sory practice at AKF Partners, but obviously it is obfuscated to protect privacy andsimplified to derive the relevant teaching points quickly.
为了充分理解同步调用如何导致扩展问题以及如何从一开始就设计或将系统转换为使用异步调用,我们将调用一个可以探索的示例系统。我们将要讨论的系统取自我们在 AKF Partners 的咨询实践中审查的实际客户实施,但显然为了保护隐私而对其进行了混淆,并进行了简化以快速得出相关的教学要点。
The client had a system, we’ll call it MailScale, that allowed subscribed users toemail groups of other users with special notices, newsletters, and coupons (see Figure26.1). The volume of emails sent in a single campaign could be very large, as many asseveral hundred thousand recipients. These jobs were obviously done asynchronouslyfrom the main site. When a subscribed user was finished creating or uploading theemail notice, he submitted the email job to process. Because processing tens of thou-sands of emails can take several minutes, it really would be ridiculous to hold up theuser’s done page with a synchronous call while the job actually processes. So far, sogood; we have email batch jobs that are performed asynchronously from the mainuser site.
客户有一个系统,我们称之为 MailScale,它允许订阅用户通过电子邮件向其他用户组发送特殊通知、时事通讯和优惠券(见图 26.1)。一次活动中发送的电子邮件量可能非常大,多达数十万收件人。这些工作显然是从主站点异步完成的。当订阅用户完成创建或上传电子邮件通知后,他提交了电子邮件作业以进行处理。由于处理数万封电子邮件可能需要几分钟的时间,因此在作业实际处理时通过同步调用来阻止用户的完成页面确实是荒谬的。到目前为止,一切都很好;我们有从主用户站点异步执行的电子邮件批处理作业。
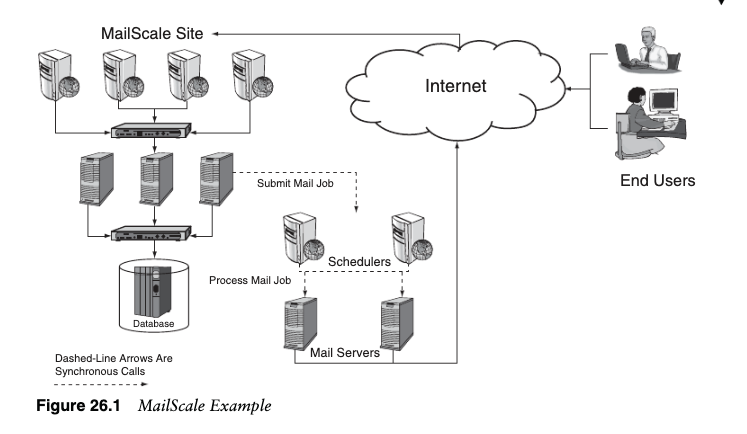
The problem was that behind the main site there were schedulers that queued theemail jobs and parsed them out to available email servers when they became avail-able. These schedulers were the service that received the email job from the main sitewhen submitted by the user. This was done synchronously: a user clicked Send, thecall was placed to the scheduler to receive the email job, and a confirmation wasreturned that the job was received and queued. This makes sense that you don’t wantthis submission to fail without the user knowing it and the call takes a couple hun-dred milliseconds usually, so this is just a simple synchronous method invocation.However, the engineer who made this decision did not know that the schedulers wereplacing synchronous calls to the mail servers.
问题在于,主站点后面有调度程序,它们对电子邮件作业进行排队,并在它们可用时将其解析到可用的电子邮件服务器。这些调度程序是在用户提交时从主站点接收电子邮件作业的服务。这是同步完成的:用户单击“发送”,调用调度程序以接收电子邮件作业,并返回作业已接收并排队的确认信息。这是有道理的,你不希望这个提交在用户不知情的情况下失败,并且调用通常需要几百毫秒,所以这只是一个简单的同步方法调用。但是,做出这个决定的工程师并不知道调度程序正在对邮件服务器进行同步调用。
When a scheduler received a job, it queued it up until a mail server became avail-able. Then, the scheduler would establish a synchronous stream of communicationbetween itself and the mail server to pass all the information about the job and mon-itor the job while it completed. When all the mail servers were running under maxi-mum capacity, and there were the proper number of schedulers for the number ofmail servers, everything worked fine. When mail slowed down because of an exces-sive number of bounce back emails or an ISP mail server was slow receiving the out-bound emails, the MailScale email servers could slow down and get backed up. Thisin turn backed up the schedulers because they relied on a synchronous communica-tion channel for monitoring the status of the jobs. When the schedulers slowed downand became unresponsive, this backed up into the main site, making the applicationDatabaseservers trying to synchronously insert and schedule email jobs to slow down. Theentire site became slow and unresponsive, all because of a chain of synchronous callsthat no single person was aware of.
当调度程序收到作业时,它会将其排队,直到邮件服务器可用。然后,调度程序将在其自身和邮件服务器之间建立同步通信流,以传递有关作业的所有信息并在作业完成时监视作业。当所有邮件服务器都在最大容量下运行,并且有适合邮件服务器数量的调度程序时,一切都工作正常。当邮件由于退回电子邮件数量过多或 ISP 邮件服务器接收出站电子邮件速度缓慢而变慢时,MailScale 电子邮件服务器可能会变慢并进行备份。这反过来又支持了调度程序,因为它们依赖同步通信通道来监视作业的状态。当调度程序变慢并变得无响应时,这会备份到主站点,从而使应用程序数据库服务器尝试同步插入和调度电子邮件作业速度变慢。整个站点变得缓慢且无响应,这都是因为没有人意识到的一系列同步调用。
The fix for this problem was to break the synchronous communication into asyn-chronous calls, preferably at both the app to scheduler and scheduler to email serv-ers, but at least at one of those places. There are a few lessons to be learned here. Thefirst and most important is that synchronous calls can cause problems in your systemin unexpected places. One call can lead to another call to another, which can get verycomplicated with all the interactions and multitude of independent code pathsthrough most systems, often referred to as the cyclomatic complexity of a program.The next lesson that we can take from this is that engineers usually do not have theoverall architecture vision, and this can cause them to make decisions that daisychain processes together. This is the reason that architects and managers are criticalto help with designs, constantly teach engineers about the larger system, and overseeimplementations in an attempt to avoid these problems. The last lesson that we cantake from this example is the complexity in debugging problems of this nature.Depending on the monitoring system, it is likely that the first alert comes from theslowdown of the site and not the mail servers. If that occurs, it is natural that every-one start looking at why the site is slowing down the mail servers instead of the otherway around. These problems can take a while to unravel and decipher.
这个问题的解决方法是将同步通信分解为异步调用,最好是在应用程序到调度程序以及调度程序到电子邮件服务器上,但至少在其中一个地方。这里有一些值得吸取的教训。第一个也是最重要的一点是,同步调用可能会在系统中意外的地方导致问题。一个调用可能会导致对另一个调用的另一个调用,这可能会因为大多数系统中的所有交互和大量独立代码路径而变得非常复杂,通常称为程序的圈复杂度。我们可以从中吸取的下一个教训是,工程师通常没有整体架构愿景,这可能导致他们做出菊花链一起处理的决策。这就是为什么架构师和管理人员必须帮助设计、不断向工程师传授更大系统的知识并监督实施以避免这些问题。我们从这个例子中得到的最后一个教训是调试这种性质的问题的复杂性。根据监控系统,第一个警报很可能来自站点的速度变慢,而不是邮件服务器。如果发生这种情况,很自然,每个人都会开始研究为什么该网站会减慢邮件服务器的速度,而不是相反。这些问题可能需要一段时间才能解开和破译。
Another reason to analyze and remove synchronous calls is the multiplicativeeffect of failure. If you are old enough, you might remember the old Christmas treelights. These were strings of lights where if you had a single bulb out in the entirestring of lights, it caused every other bulb to be out. These lights were wired in series,and should any single light fail, the entire string would fail. As a result, the “avail-ability” of the string of lights was the product of the availability (1—the probabilityof failure) of all the lights. If any light had a 99.999% availability or a 0.001%chance of failure and there were 100 lights in the string, the theoretical availability ofthe string of lights was 0.99999100 or 0.999, reduced from 5-nine availability to 3-nineavailability. In a year’s time, 5-nine availability, 99.999%, has just over five minutesof downtime, bulbs out, whereas a 3-nine availability, 99.9%, has over 500 minutesof downtime. This equates to increasing the chance of failure from 0.001% to 0.1%.No wonder our parents hated putting up those lights!
分析和删除同步调用的另一个原因是失败的乘数效应。如果您足够大,您可能还记得旧的圣诞树灯。这些是一串灯,如果整串灯中只有一个灯泡熄灭,就会导致其他所有灯泡都熄灭。这些灯是串联的,如果任何一个灯发生故障,整个灯串都会发生故障。因此,灯串的“可用性”是所有灯的可用性(1——故障概率)的乘积。如果任何灯的可用性为 99.999% 或故障率为 0.001%,并且灯串中有 100 个灯,则灯串的理论可用性为 0.99999100 或 0.999,从 5-9 可用性减少到 3-9 可用性。在一年的时间内,5 点 9 的可用性(99.999%)的停机时间刚刚超过 5 分钟,灯泡坏了,而 3 点 9 的可用性(99.9%)的停机时间超过 500 分钟。这相当于将失败的几率从 0.001% 增加到 0.1%。难怪我们的父母讨厌挂那些灯!
Systems that rely upon each other for information in a series and in synchronousfashion are subject to the same rates of failure as the Christmas tree lights of yore.Synchronous calls cause the same types of problems as lights wired in series. If onefails, it is going to cause problems within the line of communication back to the endcustomer. The more calls we make, the higher the probability of failure. The higherthe probability of failure, the more likely it is that we hold open connections andrefuse future customer requests. The easiest fix to this is to make these calls asynchro-nous and ensure that they have a chance to recover gracefully with timeouts shouldthey not receive responses in a timely fashion. If you’ve waited two seconds and aresponse hasn’t come back, simply discard the request and return a friendly errormessage to the customer.
以串联和同步方式相互依赖信息的系统会遇到与以前的圣诞树灯相同的故障率。同步调用会导致与串联灯相同类型的问题。如果失败,将会在返回最终客户的通信线路中造成问题。我们拨打的电话越多,失败的可能性就越高。失败的概率越高,我们保持开放连接并拒绝未来客户请求的可能性就越大。最简单的解决方法是使这些调用异步,并确保它们有机会在超时后优雅地恢复(如果它们没有及时收到响应)。如果您等待了两秒钟并且没有返回响应,只需放弃请求并向客户返回一条友好的错误消息即可。
This entire discussion of synchronous and asynchronous calls is one of the oftenmissed but necessary topics that must be discussed, debated, and taught to organiza-tions. Skipping over this is asking for problems down the road when loads start togrow, servers start reaching maximum capacity, or services get added. Adopting prin-ciples, standards, and coding practices now will save a lot of downtime and wastedresources on tracking down and fixing these problems in the future.
对同步和异步调用的整个讨论是经常被忽略但必须向组织进行讨论、辩论和教授的主题之一。跳过这一点会在负载开始增长、服务器开始达到最大容量或添加服务时引发问题。现在采用原则、标准和编码实践将在未来跟踪和解决这些问题时节省大量停机时间和资源浪费。
Defining State 定义状态
Another oft ignored engineering topic is stateful versus stateless applications. Anapplication that uses state is called stateful and it relies on the current condition ofexecution as a determinant of the next action to be performed. An application or pro-tocol that doesn’t use state is referred to as stateless. Hyper Text Transfer Protocol(HTTP) is a stateless protocol because it doesn’t need any information about the pre-vious request to know everything necessary to fulfill the next request. An example ofthe use of state would be in a monitoring program that first identifies that a querywas requested instead of a cache request and then, based on that information, it cal-culates a duration time for the query. In a stateless implementation of the same pro-gram, it would receive all the information that it required to calculate the duration atthe time of request. If it was a duration calculation for a query, this informationwould be passed to it upon invocation.
另一个经常被忽视的工程主题是有状态应用程序与无状态应用程序。使用状态的应用程序称为有状态应用程序,它依赖当前的执行条件作为下一个要执行的操作的决定因素。不使用状态的应用程序或协议称为无状态。超文本传输协议 (HTTP) 是一种无状态协议,因为它不需要有关先前请求的任何信息来了解满足下一个请求所需的所有信息。使用状态的一个示例是在监视程序中,该程序首先识别出请求的是查询而不是缓存请求,然后基于该信息计算查询的持续时间。在同一程序的无状态实现中,它将接收计算请求时的持续时间所需的所有信息。如果它是查询的持续时间计算,则该信息将在调用时传递给它。
You may recall from a computer science computational theory class the descrip-tion of Mealy and Moore machines, which are known as state machines or finitestate machines. A state machine is an abstract model of states and actions that is usedto model behavior; these can be implemented in the real world in either hardware orsoftware. There are other ways to model or describe behavior of an application, butthe state machine is one of the most common.
您可能还记得计算机科学计算理论课程中对 Mealy 和 Moore 机的描述,它们被称为状态机或有限状态机。状态机是状态和动作的抽象模型,用于对行为进行建模;这些可以在现实世界中通过硬件或软件来实现。还有其他方法可以对应用程序的行为进行建模或描述,但状态机是最常见的方法之一。
Mealy Moore Machines 米利摩尔机器
A Mealy machine is a finite state machine that generates output based on the input and thecurrent state of the machine. A Moore machine, on the other hand, is a finite state machine thatgenerates output based solely on the current state. A very simple example of a Moore machineis a turn signal that alternates on and off. The output is the light being turned on or off and iscompletely determined by the current state. If it is on, it gets turned off. If it is off, it gets turned on.
Mealy 机是一种有限状态机,它根据输入和机器的当前状态生成输出。另一方面,摩尔机是一种有限状态机,它仅根据当前状态生成输出。摩尔机器的一个非常简单的例子是交替打开和关闭的转向信号灯。输出是灯的打开或关闭,完全由当前状态决定。如果它打开,它就会关闭。如果它关闭,它就会打开。
Another very simple example, this time of a Mealy machine, is a traffic signal. Assume thatthe traffic signal has a switch to determine whether a car is present. The output is the trafficlight red, yellow, or green. The input is a car at the intersection waiting on the light. The outputis determined by the current state of the light as well as the input. If a car is waiting and the cur-rent state is red, the signal gets turned to green. Obviously, these are both overly simplifiedexamples, but you get the point that there are different ways of modeling behavior using states,inputs, outputs, and actions.
另一个非常简单的例子,这次是 Mealy 机器,是交通信号灯。假设交通信号灯有一个开关来确定是否有汽车。输出是交通灯红色、黄色或绿色。输入是一辆在十字路口等待信号灯的汽车。输出由光的当前状态以及输入决定。如果汽车正在等待并且当前状态为红色,则信号将变为绿色。显然,这些都是过于简化的示例,但您会发现使用状态、输入、输出和操作来建模行为有不同的方法。
Given that finite state machines are one of the fundamental aspects of theoreticalcomputer science as mathematically modeled by automatons, it is no wonder whythis is a fundamental structure of our system designs. But why exactly do we see statein almost all of our programs, and are there alternatives? The reason that most appli-cations rely on state is that the languages used for Web based or Software as a Service(SaaS) development are almost all imperative based. Imperative programming is theuse of statements to describe how to change the state of a program. Declarative pro-gramming is the opposite and uses statements to describe what changes need to takeplace. Procedural, structured, and object-oriented programming all are imperative-based programming methodologies. Example languages include Pascal, C/C
- andJava. Functional or logical programming is declarative and therefore does not makeuse of the state of the program. Standard Query Language (SQL) is a common exam-ple of a logical language that is stateless.
鉴于有限状态机是理论计算机科学的基本方面之一,由自动机进行数学建模,因此它成为我们系统设计的基本结构也就不足为奇了。但为什么我们在几乎所有的程序中都看到了状态,还有其他选择吗?大多数应用程序依赖状态的原因是用于基于 Web 或软件即服务 (SaaS) 开发的语言几乎都是基于命令式的。命令式编程是使用语句来描述如何更改程序的状态。声明性编程则相反,它使用语句来描述需要进行哪些更改。过程式、结构化和面向对象的编程都是基于命令的编程方法。示例语言包括 Pascal、C/C
- 和 Java。函数或逻辑编程是声明性的,因此不利用程序的状态。标准查询语言 (SQL) 是无状态逻辑语言的常见示例。
Now that we have explored the definition of state and understand why state isfundamental to most of our systems, we can start to explore how this can cause prob-lems when we need to scale our applications. Having an application run as a singleinstance on a single server, the state of the machine is known and easy to manage. Allusers run on the one server, so knowing that a particular user has logged in allows theapplication to use this state of being logged in and whatever input arrives, such asclicking a link, to determine what the resulting output should be. The complexity ofthis comes when we begin to scale our application along the X-axis by adding serv-ers. If a user arrives on one server for this request and on another server for the nextrequest, how would each machine know the current state of the user? If your applica-tion is split along the Y-axis and the login service is running in a completely differentpool than the report service, how does each of these services know the state of theother? These are all questions that arise when trying to scale applications that requirestate. These are not insurmountable, but they do require some thought, hopefullybefore you are in a bind with your current capacity and have to rush out a new serveror split the services.
现在我们已经探索了状态的定义并理解了为什么状态对于我们大多数系统来说是基础,我们可以开始探索当我们需要扩展应用程序时这会如何导致问题。让应用程序作为单个服务器上的单个实例运行,机器的状态是已知的并且易于管理。所有用户都在一台服务器上运行,因此知道特定用户已登录,应用程序就可以使用这种登录状态以及到达的任何输入(例如单击链接)来确定结果输出应该是什么。当我们开始通过添加服务器沿 X 轴扩展应用程序时,事情就变得复杂了。如果用户针对此请求到达一台服务器,并针对下一个请求到达另一台服务器,那么每台计算机如何知道用户的当前状态?如果您的应用程序沿 Y 轴拆分,并且登录服务在与报表服务完全不同的池中运行,那么这些服务中的每一个如何知道另一个服务的状态?这些都是在尝试扩展需要状态的应用程序时出现的问题。这些并不是不可克服的,但它们确实需要一些思考,希望在您受到当前容量的束缚并且必须匆忙推出新服务器或拆分服务之前。
One of the most common implementations of state is the user session. Just becausean application is stateful does not mean that it must have a user sessions. The oppo-site is true also. An application or service that implements a session may do so as astateless manner; consider the stateless session beans in enterprise java beans. A usersession is an established communication between the client, typically the user’sbrowser, and the server that gets maintained during the life of the session for thatuser. There are lots of things that developers store in user sessions, perhaps the mostcommon is the fact that the user is logged in and has certain privileges. This obvi-ously is important unless you want to continue validating the user’s authentication ateach page request. Other items typically stored in session include account attributessuch as preferences for first seen reports, layout, or default settings. Again, havingthese retrieved once from the database and then kept with the user during the sessioncan be the most economical thing to do.
状态最常见的实现之一是用户会话。仅仅因为应用程序是有状态的并不意味着它必须具有用户会话。相反的情况也是如此。实现会话的应用程序或服务可以以无状态方式实现;考虑企业 Java Bean 中的无状态会话 Bean。用户会话是客户端(通常是用户的浏览器)和服务器之间建立的通信,该通信在该用户的会话生命周期内得到维护。开发人员在用户会话中存储了很多东西,也许最常见的是用户已登录并具有某些权限。这显然很重要,除非您想在每个页面请求时继续验证用户的身份验证。通常存储在会话中的其他项目包括帐户属性,例如首次看到的报告的首选项、布局或默认设置。同样,从数据库中检索一次这些数据,然后在会话期间保留给用户可能是最经济的做法。
As we laid out in the previous paragraph, there are lots of things that you maywant to store in a user’s session, but storing this information can be problematic interms of increased complexity for scaling. It makes great sense to not have to con-stantly communicate with the database to retrieve a user’s preferences as they bouncearound your site, but this improved performance makes it difficult when there is apool of servers handling user requests. Another complexity of keeping session is thatif you are not careful the amount of information stored there will become unwieldy.Although not common, sometimes an individual user’s session data reaches orexceeds hundreds of kilobytes. Of course, this is excessive, but we’ve seen clients failto manage their session data and the result is a Frankenstein’s monster in terms ofboth size and complexity. Every engineer wants his information to be quickly andeasily available, so he sticks his data in the session. After you’ve stepped back andlooked at the size and the obvious problems of keeping all these user sessions inmemory or transmitting them back and forth between the user’s browser and theserver, this situation needs to be remedied quickly.
正如我们在上一段中所述,您可能希望在用户会话中存储很多内容,但存储这些信息可能会增加扩展的复杂性,从而产生问题。当用户在您的网站上跳来跳去时,不必不断与数据库通信来检索用户的首选项,这是很有意义的,但是当有大量服务器处理用户请求时,这种改进的性能会变得很困难。保持会话的另一个复杂性是,如果不小心,存储在其中的信息量将变得难以处理。尽管并不常见,但有时单个用户的会话数据会达到或超过数百千字节。当然,这是过度的,但我们已经看到客户无法管理他们的会话数据,结果是在大小和复杂性方面都是弗兰肯斯坦的怪物。每个工程师都希望他的信息能够快速、轻松地获得,因此他将他的数据保留在会话中。在您退后一步并查看将所有这些用户会话保留在内存中或在用户浏览器和服务器之间来回传输的大小和明显问题之后,需要快速纠正这种情况。
If you have managed to keep the user sessions to a reasonable size, what methodsare available for saving state or keeping sessions in environments with multiple serv-ers? There are three basic approaches: avoid, centralize, and decentralize. Similar toour approach with caching, the best way to solve a user session scaling issue is toavoid having the issue. You can achieve this by either removing session data fromyour application or making it stateless. The other way to achieve avoidance is tomake sure each user is only placed on a single server. This way, the session data canremain in memory on the server because that user will always come back to thatserver for requests; other users will go to other servers in the pool. You can accom-plish this manually in the code by performing a z-axis split (modulus or lookup) andput all users with usernames A through M on one server and all users with usernamesN through Z on another server. If DNS pushes a user with username jackal to the sec-ond server, it just redirects her to the first server to process her request. Another solu-tion to this is to use session cookies on the load balancer. These cookies assign allusers to a particular server for the duration of the session. This way, every requestthat comes through from a particular user will land on the same server. Almost allload balancer solutions offer some sort of session cookie that provides this function-ality. There are several solutions for avoiding the problem all together.
如果您已设法将用户会话保持在合理的大小,那么有哪些方法可用于在具有多个服务器的环境中保存状态或保持会话?共有三种基本方法:避免、集中和分散。与我们的缓存方法类似,解决用户会话扩展问题的最佳方法是避免出现该问题。您可以通过从应用程序中删除会话数据或使其无状态来实现此目的。实现避免的另一种方法是确保每个用户仅放置在一台服务器上。这样,会话数据就可以保留在服务器的内存中,因为该用户总是会返回该服务器来请求;其他用户将转到池中的其他服务器。您可以在代码中手动完成此操作,方法是执行 z 轴拆分(取模或查找),并将用户名 A 到 M 的所有用户放在一台服务器上,将用户名 N 到 Z 的所有用户放在另一台服务器上。如果 DNS 将用户名为 jackal 的用户推送到第二台服务器,它只会将她重定向到第一台服务器来处理她的请求。另一个解决方案是在负载平衡器上使用会话 cookie。这些 cookie 在会话期间将所有用户分配到特定服务器。这样,来自特定用户的每个请求都将落在同一服务器上。几乎所有负载均衡器解决方案都提供某种提供此功能的会话 cookie。有多种解决方案可以同时避免该问题。
Let’s assume that for some reason none of these solutions work. The next methodof solving the complexities of keeping session on a myriad of servers when scaling isdecentralization of session storage. The way that this can be accomplished is by stor-ing session in a cookie on the user’s browser. There are many implementations of this,such as serializing the session data and then storing all of it in a cookie. This sessiondata must be transferred back and forth, marshalled/unmarshalled, and manipulatedby the application, which can add up to lots of time required for this. Remember thatmarshalling and unmarshalling are processes where the object is transformed into adata format suitable for transmitting or storing and converted back again. Anothertwist to this is to store a very little amount of information in the session cookie anduse it as a reference index to a list of objects in a session database or file that containall the session information about each user. This way, the transmission and marshal-ling costs are minimized.
让我们假设由于某种原因这些解决方案都不起作用。解决扩展时在无数服务器上保持会话的复杂性的下一个方法是会话存储的分散化。实现此目的的方法是将会话存储在用户浏览器上的 cookie 中。有很多实现方式,例如序列化会话数据,然后将其全部存储在 cookie 中。该会话数据必须由应用程序来回传输、编组/解组和操作,这可能会增加所需的大量时间。请记住,编组和解组是将对象转换为适合传输或存储并再次转换回来的数据格式的过程。另一个变化是在会话 cookie 中存储极少量的信息,并将其用作会话数据库或文件中包含有关每个用户的所有会话信息的对象列表的引用索引。这样,传输和编组成本就会最小化。
The third method of solving the session problem with scaling systems is centraliza-tion. This is where all user session data is stored centrally in a cache system and allWeb or app servers can access his data. This way, if a user lands on Web server 1 forthe login and then on Web server 3 for a report, both servers can access the centralcache and see that the user is logged in and what that user’s preferences are. A cen-tralized cache system such as memcached that we discussed in Chapter 25, Cachingfor Performance and Scale, would work well in this situation for storing user sessiondata. Some systems have success using session databases, but the overhead of connec-tions and queries seem too much when there are other solutions such as caches forroughly the same cost in hardware and software. The issue to watch for with sessioncaching is that the cache hit ratio needs to be very high or the user experience will beawful. If the cache expires a session because it doesn’t have enough room to keep allthe user sessions, the user who gets kicked out of cache will have to log back in. Asyou can imagine, if this is happening 25% of the time, it is going to be extremelyannoying.
解决扩展系统会话问题的第三种方法是集中化。所有用户会话数据都集中存储在缓存系统中,所有 Web 或应用程序服务器都可以访问他的数据。这样,如果用户登陆 Web 服务器 1 进行登录,然后登陆 Web 服务器 3 进行报告,则两台服务器都可以访问中央缓存并查看用户是否已登录以及该用户的首选项是什么。集中式缓存系统(例如我们在第 25 章“性能和规模缓存”中讨论的 memcached)在这种情况下可以很好地存储用户会话数据。有些系统使用会话数据库取得了成功,但是当有其他解决方案(例如硬件和软件成本大致相同的缓存)时,连接和查询的开销似乎太大了。会话缓存需要注意的问题是缓存命中率需要非常高,否则用户体验会很差。如果缓存由于没有足够的空间来保存所有用户会话而导致会话过期,则被踢出缓存的用户将不得不重新登录。正如您可以想象的,如果这种情况发生的概率为 25%,则将会非常烦人。
Three Solutions to Scaling with Sessions 通过会话进行扩展的三种解决方案
There are three basic approaches to solving the complexities of scaling an application thatuses session data: avoidance, decentralization, and centralization.
解决扩展使用会话数据的应用程序的复杂性有三种基本方法:避免、分散和集中。
Avoidance
回避
Remove session data completely
完全删除会话数据
Modulus users to a particular server via the code
Modulus用户通过代码连接到特定服务器
Stick users on a particular server per session with session cookies from the load balancer
使用来自负载均衡器的会话 cookie 将用户固定在每个会话的特定服务器上
Decentralization
去中心化
Store session cookies with all information in the browser’s cookie.
将会话 cookie 与浏览器 cookie 中的所有信息一起存储。
Store session cookies as an index to session objects in a database or file system with all
将会话 cookie 作为会话对象的索引存储在数据库或文件系统中,其中包含所有内容
the information stored there.
存储在那里的信息。
Centralization
集权
Store sessions in a centralized session cache like memcached.
将会话存储在集中式会话缓存中,例如 memcached。
Databases can be used as well but are not recommended.
也可以使用数据库,但不推荐。
There are many creative methods of solving the session complexities when scaling applica-tions. Depending on the specific needs and parameters of your application, one or more ofthese might work better for you than others.
有许多创造性的方法可以解决扩展应用程序时的会话复杂性。根据您的应用程序的具体需求和参数,其中一项或多项可能比其他项更适合您。
Whether you decide to design your application to be stateful or stateless andwhether you use session data or not are decisions that must be made on an applica-tion by application basis. In general, it is easier to scale applications that are statelessand do not care about sessions. Although this may aid in scaling, it may be unrealisticin the complexities that it causes for the application development. When you dorequire the use of state—in particular, session state—consider how you are going toscale your application in all three axes of the AKF Scale Cube before you need to doso. Scrambling to figure out the easiest or quickest way to fix a session issue acrossmultiple servers might lead to poor long-term decisions. These on the spot architec-tural decisions should be avoided as much as possible.
无论您决定将应用程序设计为有状态还是无状态,以及是否使用会话数据,都必须根据应用程序的具体情况做出决定。一般来说,扩展无状态且不关心会话的应用程序更容易。尽管这可能有助于扩展,但由于它给应用程序开发带来的复杂性,这可能是不现实的。当您确实需要使用状态(特别是会话状态)时,请在需要之前考虑如何在 AKF Scale Cube 的所有三个轴上扩展应用程序。急于找出解决跨多个服务器的会话问题的最简单或最快的方法可能会导致糟糕的长期决策。应尽可能避免这些现场架构决策。
Conclusion 结论
In this last chapter of Part III, we dealt with synchronous versus asynchronous calls.This topic is often overlooked when developing services or products until it becomesa noticeable inhibitor to scaling. We started our discussion exploring synchroniza-tion. The process of synchronization refers to the use and coordination of simulta-neously executed threads or processes that are part of an overall task. We definedsynchronization as the situation when two or more pieces of work must be done toaccomplish a task. One example of synchronization that we covered was a mutex ormutual exclusion. Mutex was a process of protecting global resources from concur-rently running processes, often accomplished through the use of semaphores.
在第三部分的最后一章中,我们讨论了同步调用与异步调用。在开发服务或产品时,这个主题经常被忽视,直到它成为扩展的明显阻碍。我们开始讨论探索同步。同步过程是指作为整体任务一部分的同时执行的线程或进程的使用和协调。我们将同步定义为必须完成两项或多项工作才能完成一项任务的情况。我们介绍的同步示例之一是互斥或互斥。互斥是一个保护全局资源免受并发运行进程影响的过程,通常通过使用信号量来实现。
After we covered synchronization, we tackled the topics of synchronous and asyn-chronous calls. We discussed synchronous methods as ones that, when they are called,execute, and when they finish, the calling method gets control back. This was con-trasted with the asynchronous methods calls where the method is called to execute ina new thread and it immediately returns control back to the thread that called it. Thedesign pattern that describes the asynchronous method call is known as the asynchro-nous method invocation (AMI). With the general definitions under our belt, we con-tinued with an analysis of why synchronous calls can become problematic for scaling.We gave some examples of how an unsuspecting synchronous call can actually causesevere problems across the entire system. Although we did not encourage the com-plete elimination of synchronous calls, we did express the recommendation that youthoroughly understand how to convert synchronous calls to asynchronous ones.Additionally, we discussed why it is important to have individuals like architects andmanagers overseeing the entire system design to help point out to engineers whenasynchronous calls could be warranted.
在介绍了同步之后,我们讨论了同步和异步调用的主题。我们讨论的同步方法是这样的:当调用它们时,执行它们,当它们完成时,调用方法将控制权收回。这与异步方法调用形成对比,异步方法调用在新线程中调用该方法并立即将控制权返回给调用它的线程。描述异步方法调用的设计模式称为异步方法调用 (AMI)。有了一般定义,我们继续分析同步调用为何会成为扩展问题。我们给出了一些示例,说明毫无戒心的同步调用实际上如何导致整个系统出现严重问题。尽管我们并不鼓励完全消除同步调用,但我们确实表达了建议,即让您大致了解如何将同步调用转换为异步调用。此外,我们还讨论了为什么让架构师和经理等个人监督整个系统设计很重要帮助向工程师指出何时可以保证异步调用。
Another topic that we covered in this chapter was the use of state in an applica-tion. We started with what is state within application development. We then doveinto a discussion in computational theory on finite state machines and concludedwith a distinction between imperative and declarative languages. We finished thestateful versus stateless conversation with one of the most commonly used implemen-tations of state: that being the session state. Session as we defined it was an estab-lished communication between the client, typically the user’s browser, and the server,that gets maintained during the life of the session for that user. We noted that keepingtrack of session data can become laborious and complex, especially when dealingwith scaling an application on any of the axes from the AKF Scale Cube. We coveredthree broad classes of solutions—avoidance, centralization, and decentralization—and gave specific examples and alternatives for each.
本章讨论的另一个主题是在应用程序中使用状态。我们从应用程序开发中的状态开始。然后,我们深入讨论有限状态机的计算理论,并得出命令式语言和声明式语言之间的区别。我们通过最常用的状态实现之一完成了有状态与无状态的对话:即会话状态。正如我们所定义的,会话是客户端(通常是用户的浏览器)和服务器之间建立的通信,该通信在该用户的会话生命周期内得到维护。我们注意到,跟踪会话数据可能会变得费力且复杂,尤其是在处理 AKF Scale Cube 中任何轴上的应用程序缩放时。我们涵盖了三大类解决方案——避免、集中和分散——并为每种解决方案提供了具体的示例和替代方案。
The overall lesson that this chapter should impart on the reader is that there arereasons that we see engineers use synchronous calls and write stateful applications,some due to carefully considered reasons and others because of the nature of moderncomputational theory and languages. The important point is that you should spendthe time up front discussing these so that there are more, carefully considered deci-sions about the uses of these rather than finding yourself needing to scale an applica-tion and finding out that there are designs that prevent you from doing so.
本章应该向读者传授的总体教训是,我们看到工程师使用同步调用和编写有状态应用程序是有原因的,一些是由于仔细考虑的原因,另一些是由于现代计算理论和语言的性质。重要的一点是,您应该花时间预先讨论这些内容,以便对这些内容的使用做出更多、经过仔细考虑的决定,而不是发现自己需要扩展应用程序并发现存在阻碍您的设计这样做。
Key Points 关键点
Synchronization is when two or more pieces of work must be done in order toaccomplish a task.
同步是指必须完成两项或多项工作才能完成一项任务。
Mutex is a synchronization method that defines how global resources are pro-tected from concurrently running processes.
互斥体是一种同步方法,定义如何保护全局资源免受并发运行进程的影响。
Synchronous calls perform their action completely by the time the call returns.
同步调用在调用返回时完全执行其操作。
With an asynchronous method call, the method is called to execute in a newthread and it immediately returns control back to the thread that called it.
通过异步方法调用,该方法被调用以在新线程中执行,并且它立即将控制权返回给调用它的线程。
The design pattern that describes the asynchronous method call is known as theasynchronous design and alternatively as the asynchronous method invocation(AMI).
描述异步方法调用的设计模式称为异步设计,也称为异步方法调用 (AMI)。
Synchronous calls can, if used excessively or incorrectly, cause undue burden onthe system and prevent it from scaling.
如果过度或不正确地使用同步调用,可能会对系统造成过度的负担并阻止其扩展。
Synchronous calls are simpler than asynchronous calls.
同步调用比异步调用更简单。
The second part of the problem of synchronous calls is that developers typicallyonly see a small portion of the application.
同步调用问题的第二部分是开发人员通常只能看到应用程序的一小部分。
An application that uses state is called stateful and it relies on the current stateof execution as a determinant of the next action to be performed.
使用状态的应用程序称为有状态应用程序,它依赖于当前执行状态作为要执行的下一个操作的决定因素。
An application or protocol that doesn’t use state is referred to as stateless.
不使用状态的应用程序或协议称为无状态。
Hyper Text Transfer Protocol (HTTP) is a stateless protocol because it doesn’tneed any information about the previous request to know everything necessaryto fulfill the next request.
超文本传输协议 (HTTP) 是一种无状态协议,因为它不需要有关先前请求的任何信息来了解满足下一个请求所需的所有信息。
A state machine is an abstract model of states and actions that is used to modelbehavior; these can be implemented in the real world in either hardware orsoftware.
状态机是状态和动作的抽象模型,用于对行为进行建模;这些可以在现实世界中通过硬件或软件来实现。
The reason that most applications rely on state is that the languages used forWeb based or SaaS development are almost all imperative based.
大多数应用程序依赖状态的原因是用于基于Web 或SaaS 开发的语言几乎都是基于命令式的。
Imperative programming is the use of statements to describe how to change thestate of a program.
命令式编程是使用语句来描述如何更改程序的状态。
Declarative programming is the opposite and uses statements to describe whatchanges need to take place.
声明式编程则相反,它使用语句来描述需要发生的更改。
One of the most common implementations of state is the user session.
状态最常见的实现之一是用户会话。
Choosing wisely between synchronous/asynchronous as well as stateful/statelessis critical for scalable applications.
在同步/异步以及有状态/无状态之间明智地选择对于可扩展应用程序至关重要。
Have discussions and make decisions early, when standards, practices, and prin-ciples can be followed.
当标准、实践和原则可以遵循时,尽早进行讨论并做出决定。
Solving Other Issues and Challenges
解决其他问题和挑战
已有 4 条评论
《护国利刃(特别版)》短片剧高清在线免费观看:https://www.jgz518.com/xingkong/160073.html
你的文章充满了创意,真是让人惊喜。 http://www.55baobei.com/hD9cSMftQj.html
《元龙第三季(全新数字修复版 )》国产动漫高清在线免费观看:https://www.jgz518.com/xingkong/142440.html
你的文章内容非常精彩,让人回味无穷。 http://www.55baobei.com/CTJtMOi5Qb.html