这篇文章上次修改于 217 天前,可能其部分内容已经发生变化,如有疑问可询问作者。 ###《可扩展的艺术》Chapter 23 Splitting Applications for Scale 第23章 针对规模拆分应用程序 > Whether to concentrate or to divide your troops must be decided by circumstances.—Sun Tzu > 集中兵力还是分兵作战,要根据情况而定。——《孙子》 The previous chapter introduced the model by which we describe splits to allow fornearly infinite scale. Now we’re going to apply the concepts we discussed withinChapter 22, Introduction to the AKF Scale Cube, to our realworld technology plat-form needs. To do this, we will separate the platform into pieces that address ourapplication and service offerings (covered in this chapter) and the splits necessary toallow our storage and databases to scale (covered in the next chapter). The samemodel and set of principles hold true for both approaches, but the implementationvaries enough that it makes sense for us to address them in two separate chapters. 上一章介绍了我们描述分裂以允许近乎无限规模的模型。现在,我们将把第 22 章“AKF Scale Cube 简介”中讨论的概念应用于我们现实世界的技术平台需求。为此,我们将把平台分成几个部分,以解决我们的应用程序和服务产品(在本章中介绍)以及允许我们的存储和数据库扩展所需的分割(在下一章中介绍)。相同的模型和一组原则适用于这两种方法,但实现方式差异很大,因此我们有必要在两个单独的章节中讨论它们。 ####The AKF Scale Cube for Applications 适用于应用的 AKF Scale Cube The underlying meaning of the AKF Scale Cube really doesn’t change when discuss-ing either databases or applications. However, given that we are now going to usethis tool to accomplish a specific purpose, we are going to add more specificity to theaxes. These new descriptions, although remaining absolutely true to our original def-initions, will make it more useful for us to apply the AKF Scale Cube to the architect-ing of applications to allow for greater scalability. Let’s first start with the AKF ScaleCube from the end of Chapter 22. 在讨论数据库或应用程序时,AKF Scale Cube 的基本含义实际上并没有改变。然而,鉴于我们现在要使用此工具来实现特定目的,我们将为轴添加更多特异性。这些新的描述虽然完全符合我们最初的定义,但将使我们更有用地将 AKF Scale Cube 应用于应用程序的架构,以实现更大的可扩展性。我们首先从第 22 章末尾的 AKF ScaleCube 开始。 In Chapter 22, we defined the x-axis of our cube as the cloning of services anddata with absolutely no bias. In the x-axis approach to scale, the only thing that isdifferent between one system and 100 systems is that the transactions are evenly splitbetween those 100 systems as if each of them was a single instance capable of han-dling 100% of the original requests rather than the 1% that they actually handle. Wewill rename our x-axis to Horizontal Duplication/Cloning of Services to make itmore obvious how we will apply this to our architecture efforts. 在第 22 章中,我们将立方体的 x 轴定义为完全没有偏见的服务和数据的克隆。在 X 轴扩展方法中,一个系统和 100 个系统之间的唯一区别是,事务在这 100 个系统之间均匀分配,就好像每个系统都是能够处理 100% 原始请求的单个实例一样而不是他们实际处理的 1%。我们将把 x 轴重命名为水平复制/服务克隆,以便更明显地看出我们将如何将其应用到我们的架构工作中。 The y-axis from Chapter 22 was described as a separation of work responsibilityby either the type of data, the type of work performed for a transaction, or a combi-nation of both. We most often describe this as a service oriented split within an appli-cation and as such we will now label this axis as a split by function or service. Here,function and service are indicative of the actions performed by your platform, butthey can just as easily be resource oriented splits such as the article upon which anaction is being taken. A function or service oriented split should be thought of as beingsplit along action or “verb” boundaries, whereas a resource oriented split is mostoften split along “noun” boundaries. We’ll describe these splits later in this chapter. 第 22 章中的 y 轴被描述为通过数据类型、为事务执行的工作类型或两者的组合来划分工作职责。我们最常将其描述为应用程序内面向服务的拆分,因此我们现在将此轴标记为按功能或服务进行拆分。在这里,功能和服务表示您的平台执行的操作,但它们也可以轻松地进行面向资源的拆分,例如正在执行操作的文章。面向功能或服务的拆分应该被认为是沿着操作或“动词”边界进行拆分,而面向资源的拆分通常是沿着“名词”边界进行拆分。我们将在本章后面描述这些分裂。 The z-axis from Chapter 22 was described as being focused on data and actionsthat are unique to the person or system performing the request, or alternatively theperson or system for which the request is being performed. In other words, these arerequests that are split by the person or system making a request or split based on theperson or system for whom the data is intended. We also often refer to the z-axis asbeing a “lookup oriented” split in applications. The lookup here is an indication thatusers or data are subject to a non action oriented bias that is represented somewhereelse within the system. We store the relationships of users to their appropriate split orservice somewhere, or determine an algorithm such as a hash or modulus of user_idthat will reliably and consistently send us to the right location set of systems to getthe answers for the set of users in question. 第 22 章中的 z 轴被描述为专注于执行请求的人员或系统、或者正在执行请求的人员或系统所特有的数据和操作。换句话说,这些请求是由发出请求的人或系统分割的,或者是根据数据所针对的人或系统分割的。我们还经常将 z 轴称为应用程序中的“面向查找”分割。这里的查找表明用户或数据受到非行动导向的偏见的影响,这种偏见在系统内的其他地方表现出来。我们将用户与其适当的分割或服务的关系存储在某处,或者确定诸如哈希值或 user_id 模数之类的算法,该算法将可靠且一致地将我们发送到系统的正确位置集,以获得相关用户集的答案。 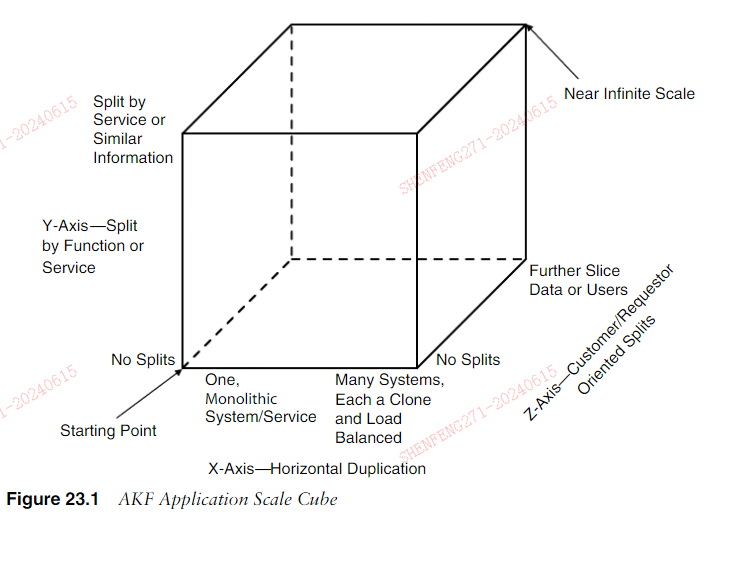 The new AKF Scale Cube for applications now looks like Figure 23.1.####The X-Axis of the AKF Application Scale Cube 用于应用程序的新 AKF Scale Cube 现在如图 23.1 所示。####AKF Application Scale Cube 的 X 轴 The x-axis of the AKF Application Scale Cube represents cloning of services withabsolutely no bias. As described previously, if we have a service or platform that isscaled using the x-axis alone and consisting of N systems, each of the N systems canrespond to any request and will give exactly the same answer as the other (N-1) sys-tems. There is no bias to service performed, customer, or any other data element.Login functionality exists in the same location and application as shopping cart,checkout, catalog, and search functionality. Regardless of the request, it is sent to oneof the N systems that comprise our x-axis split. AKF 应用程序规模立方体的 x 轴代表绝对无偏见的服务克隆。如前所述,如果我们有一个仅使用 x 轴进行缩放并由 N 个系统组成的服务或平台,则 N 个系统中的每个系统都可以响应任何请求,并给出与其他 (N-1) 个系统完全相同的答案-项目。对所执行的服务、客户或任何其他数据元素没有偏见。登录功能与购物车、结帐、目录和搜索功能存在于同一位置和应用程序中。无论请求如何,它都会发送到构成 x 轴拆分的 N 个系统中的一个。 The x-axis approach is simple to implement in most cases. You simply take exactlythe same code that existed in a single instance implementation and put it on multipleservers. If your application is not “stateful,” meaning per our previous definitionsthat you are not using a user’s previous transactions to inform future decisions, sim-ply load balance all of the inbound requests to any of the N systems. If you are main-taining data associated with user state or otherwise are requiring persistence from auser to an application or Web server, both of which increase the cost of implementa-tion for a number of reasons, the implementation is slightly more difficult, but thesame basic approach is used. In the cases where persistency or state is necessary (orpersistency resulting from the need for state), a series of transactions from a singleuser is simply pegged to one of the N instances of the x-axis split. This can be accom-plished with session cookies from a load balancer. Additionally, as we will discussmore in Chapter 26, Asynchronous Design for Scale, there are methods of centraliz-ing session management to still allow any of N systems to respond to an individualuser’s request without requiring persistency to that system. 在大多数情况下,x 轴方法很容易实现。您只需将单个实例实现中存在的完全相同的代码放在多个服务器上即可。如果您的应用程序不是“有状态的”,即根据我们之前的定义,您没有使用用户之前的事务来通知未来的决策,则只需对 N 个系统中的任何一个入站请求进行负载平衡即可。如果您正在维护与用户状态相关的数据,或者需要从用户到应用程序或 Web 服务器的持久性,这两种情况都会由于多种原因增加实现成本,那么实现会稍微困难一些,但效果是一样的使用基本方法。在需要持久性或状态的情况下(或者由于需要状态而导致持久性),来自单个用户的一系列事务简单地与 x 轴分割的 N 个实例之一挂钩。这可以通过负载均衡器的会话 cookie 来完成。此外,正如我们将在第 26 章“大规模异步设计”中详细讨论的那样,有一些集中会话管理的方法,仍然允许 N 个系统中的任何一个响应单个用户的请求,而不需要对该系统进行持久性。 The x-axis split has several benefits and drawbacks. As a benefit, this split is rela-tively simple to envision and implement. Other benefits include that it allows for nearinfinite scale from a number of transactions perspectives and when hosting yourapplications or services it does not increase the complexity of your hosting environ-ment. Drawbacks of the x-axis approach include the inability of this split to addressscalability from a data/cache perspective or instruction complexity perspective. x 轴分割有几个优点和缺点。好处是,这种拆分的设想和实施相对简单。其他好处包括,它允许从多个事务角度实现近乎无限的规模,并且在托管您的应用程序或服务时,它不会增加托管环境的复杂性。 x 轴方法的缺点包括这种分割无法从数据/缓存角度或指令复杂性角度解决可扩展性问题。 As just stated, x-axis splits are easy to envision and implement. As such, when putin a position of needing a quick solution to any scale initiative, x-axis splits should beone of the first that you consider. Because it is generally easy to clone services, theimpact to cost in terms of design expense and implementation expense is low. Fur-thermore, the impact to time to market to release functionality with an x-axis split isgenerally low compared to other implementations as you are, after all, merely cloningthe services in question. 正如刚才所说,x 轴分割很容易设想和实现。因此,当需要快速解决任何规模计划时,x 轴分割应该是您首先考虑的问题之一。由于克隆服务通常很容易,因此对设计费用和实施费用方面的成本影响很小。此外,与其他实现相比,使用 x 轴分割发布功能对上市时间的影响通常较低,因为毕竟您只是克隆相关服务。 X-axis splits also allow us to easily scale our platforms with the number ofinbound transactions or requests. If you have a single user or small number of userswho grow from making 10 requests per second to 1000 requests per second, youneed only add roughly 100 times the number of systems or cloned services to handlethe increase in requests. There isn’t a lot of engineering magic involved—simply input thedemand increase and a spreadsheet can tell you how many systems to buy and when. X 轴拆分还使我们能够根据入站交易或请求的数量轻松扩展我们的平台。如果您的单个用户或少量用户从每秒发出 10 个请求增加到每秒 1000 个请求,则只需添加大约 100 倍数量的系统或克隆服务即可处理请求的增加。不需要太多的工程魔法——只需输入需求增长,电子表格就可以告诉您购买多少系统以及何时购买。 Finally, the team responsible for managing the services of your platform does notneed to worry about a vast number of uniquely configured systems or servers. Everysystem performing an x-axis split is roughly equivalent to every other system per-forming the same split. Configuration management of all servers is relatively easy toperform and new service implementation is as easy as cloning an existing system orgenerating a new system from a “jumpstart server” and assigning it a unique name oraddress. Configuration files do not vary and the only thing the operations groupneeds to be concerned about is the total number of systems in an x-axis implementa-tion and that each is getting an appropriate amount of traffic. 最后,负责管理平台服务的团队无需担心大量独特配置的系统或服务器。每个执行 x 轴分割的系统大致相当于执行相同分割的每个其他系统。所有服务器的配置管理相对容易执行,新服务的实施就像克隆现有系统或从“快速启动服务器”生成新系统并为其分配唯一的名称或地址一样简单。配置文件不会发生变化,运营团队唯一需要关心的是 x 轴实施中的系统总数以及每个系统获得适当的流量。 Although x-axis splits scale well with increased transaction volumes, they do notaddress the problems incurred by increasing amounts of data. If your system requiresthat you cache a great deal of data to serve client requests, as that data grows, yourtime to serve any given request will likely increase, which is obviously bad for thecustomer experience. Additionally, you might find yourself constrained on the serveror application itself if your data gets too unwieldy. Even if you don’t need to cacheany data, searching through data on other storage or database systems will likelyincrease as your customer base and/or product catalog increases in size. 尽管 x 轴分割随着交易量的增加而很好地扩展,但它们并没有解决因数据量增加而产生的问题。如果您的系统要求缓存大量数据来服务客户端请求,随着数据的增长,您服务任何给定请求的时间可能会增加,这显然不利于客户体验。此外,如果您的数据变得过于笨重,您可能会发现自己受到服务器或应用程序本身的限制。即使您不需要缓存任何数据,随着您的客户群和/或产品目录规模的增加,搜索其他存储或数据库系统上的数据也可能会增加。 X-axis splits also don’t address the complexity of the software implementing yoursystem, platform, or product. Everything in an x-axis split alone is assumed to bemonolithic in nature; as a result, applications will likely start to slow down as serverspage instruction/execution pages in and out of memory to perform different func-tions. As your product becomes more feature rich, monolithic applications slowdown and become more costly and less easily scaled either as a result of this instruc-tion complexity or the data complexity mentioned earlier. X 轴分割也无法解决实现系统、平台或产品的软件的复杂性。单独 x 轴分割中的所有内容都被假定为本质上是整体的;因此,当服务器页面指令/执行页面进出内存以执行不同的功能时,应用程序可能会开始变慢。随着您的产品功能变得更加丰富,由于指令复杂性或前面提到的数据复杂性,单体应用程序的速度会变慢,成本会更高,并且更难扩展。 #####Summarizing the Application X-Axis X 轴应用总结 The x-axis of the AKF Application Scale Cube represents the cloning of an application or ser-vice such that work can easily be distributed across instances with absolutely no bias. AKF Application Scale Cube 的 x 轴代表应用程序或服务的克隆,以便可以轻松地在实例之间分配工作,绝对没有偏见。 X-axis implementations tend to be easy to conceptualize and typically can be implementedat relatively low cost. They are the most cost-effective way of scaling transaction growth. Theycan be easily cloned within your production environment from existing systems or “jumpstarted”from “golden master” copies of systems. They do not tend to increase the complexity of youroperations or production environment. X 轴的实现往往很容易概念化,并且通常可以以相对较低的成本实现。它们是扩大交易增长的最具成本效益的方式。它们可以轻松地从现有系统克隆到您的生产环境中,或从系统的“黄金主”副本“快速启动”。它们不会增加操作或生产环境的复杂性。 X-axis implementations are limited by the growth of a monolithic application, which tends toslow down the processing of transactions. They do not scale well with increases in data orapplication size. X 轴的实现受到单一应用程序增长的限制,这往往会减慢事务处理速度。它们不能随着数据或应用程序大小的增加而很好地扩展。 ####The Y-Axis of the AKF Application Scale Cube AKF 应用比例立方体的 Y 轴 The y-axis of the cube of scale represents a separation of work responsibility withinyour application. When discussing application scale, we most frequently think of thisin terms of functions, methods, or services within an application. The y-axis splitaddresses the monolithic nature of an application by separating that application intoparallel or pipelined processing flows. A pure x-axis split would have 100 instancesof the exact same application performing exactly the same work on each of the Ntransactions that a site received over T time. Each of the 100 instances would receiveN/100 of the work. In a y-axis split, we might take a single monolithic applicationand split it up into 100 distinct services such as login, logout, read profile, updateprofile, search profiles, browse profiles, checkout, display similar items, and so on. 比例立方体的 y 轴代表应用程序中工作职责的分离。在讨论应用程序规模时,我们最常想到的是应用程序中的功能、方法或服务。 y 轴分割通过将应用程序分成并行或流水线处理流来解决应用程序的整体性质。纯 x 轴分割将有 100 个完全相同的应用程序实例,对站点在 T 时间内收到的 N 个事务中的每一个执行完全相同的工作。 100 个实例中的每个实例都会收到 N/100 的工作。在 y 轴拆分中,我们可能会将单个整体应用程序拆分为 100 个不同的服务,例如登录、注销、读取配置文件、更新配置文件、搜索配置文件、浏览配置文件、结账、显示类似项目等。 Y-axis splits are a bit more complicated to implement than x-axis splits. At a veryhigh level, it is possible to implement a y-axis split in production without actuallysplitting the code base itself. You can do this by cloning a monolithic application andsetting it on multiple physical or virtual servers. Let’s assume that you want to havefour unique y-axis split servers, each serving 1/4th of the total number of functionswithin your site. One server might serve login and logout functionality, another readand update profile, another server handles “contact individual” and “receive con-tacts,” and the last server handles all of the other functions of your platform. Youmay assign a unique URL or URI to each of these servers, such as login.allscale.comand contacts.allscale.com, and ensure that any of the functions within the appropri-ate grouping always get directed to the server in question. This is a good, firstapproach to performing a split and helps work out the operational kinks associatedwith splitting applications. Unfortunately, it doesn’t give you all of the benefits of afull y-axis split made within the codebase itself. Y 轴分割的实现比 x 轴分割要复杂一些。在非常高的水平上,可以在生产中实现 y 轴拆分,而无需实际拆分代码库本身。您可以通过克隆整体应用程序并将其设置在多个物理或虚拟服务器上来实现此目的。假设您希望拥有四个唯一的 y 轴分割服务器,每个服务器提供站点内功能总数的 1/4。一台服务器可能提供登录和注销功能,另一台服务器负责读取和更新配置文件,另一台服务器处理“联系人个人”和“接收联系人”,最后一个服务器处理平台的所有其他功能。您可以为每个服务器分配一个唯一的 URL 或 URI,例如 login.allscale.com 和 contacts.allscale.com,并确保适当分组中的任何功能始终定向到有问题的服务器。这是执行拆分的第一个很好的方法,有助于解决与拆分应用程序相关的操作问题。不幸的是,它并没有为您提供在代码库本身内进行完整 y 轴分割的所有好处。 Y-axis splits are most commonly implemented to address the issues associatedwith a code base and dataset that have grown significantly in complexity or size.They also help scale transaction volume, as in performing the splits you must add vir-tual or physical servers. To get most of the benefits of a y-axis split, the code baseitself needs to be split up from a monolithic structure to the services that comprise theentire platform. Y 轴拆分最常用于解决与复杂性或大小显着增长的代码库和数据集相关的问题。它们还有助于扩展事务量,因为在执行拆分时,您必须添加虚拟或物理服务器。为了获得 y 轴拆分的大部分好处,代码库本身需要从整体结构拆分为构成整个平台的服务。 Operationally, y-axis splits help reduce the time necessary to process any giventransaction as the data and instruction sets that are being executed or searched aresmaller. Architecturally, y-axis splits allow you to grow beyond the limitations thatsystems place on the absolute size of software or data. Y-axis splits also aid in faultisolation as identified within Chapter 21, Creating Fault Isolative Architectural Struc-tures; a failure of a given service does not bring down all of the functionality of yourplatform. 从操作上来说,y 轴分割有助于减少处理任何给定事务所需的时间,因为正在执行或搜索的数据和指令集较小。从架构上来说,y 轴分割可以让您超越系统对软件或数据绝对大小的限制。 Y 轴分割还有助于故障隔离,如第 21 章“创建故障隔离架构结构”中所述;给定服务的故障不会降低平台的所有功能。 From an engineering perspective, y-axis splits allow you to grow your team moreeasily by focusing teams on specific services or functions within your product. Youcan dedicate a person or a team to searching and browsing, a team toward the devel-opment of an advertising platform, a team to account functionality, and so on. Newengineers come up to speed faster as they are dedicated to a specific section of func-tionality within your system. More experienced engineers become experts at a givensystem and as a result can produce functionality within that system faster. The dataelements upon which any y-axis split works will likely be a subset of the total data onthe site; as such, engineers better understand the data with which they are workingand are more likely to make better choices in creating data models. 从工程角度来看,y 轴拆分让您可以将团队重点放在产品中的特定服务或功能上,从而更轻松地发展团队。您可以指定一个人或一个团队来进行搜索和浏览,指定一个团队来开发广告平台,指定一个团队来负责帐户功能,等等。新工程师的学习速度更快,因为他们专注于系统中的特定功能部分。经验丰富的工程师成为给定系统的专家,因此可以更快地在该系统中生成功能。任何 y 轴分割所依据的数据元素可能是站点上总数据的子集;因此,工程师可以更好地理解他们正在使用的数据,并且更有可能在创建数据模型时做出更好的选择。 Y-axis splits also have drawbacks. They tend to be more costly to implement inengineering time than x-axis splits because engineers either need to rewrite or at thevery least disaggregate services from the monolithic application. The operations andinfrastructure teams will now need to support more than one configuration of server.This in turn might mean that there is more than one class or size of server in the oper-ations environment to get the most cost-efficient systems for each type of transaction.When caching is involved, data might be cached differently in different systems, butwe highly recommend that a standard approach to caching be shared across all of thesplits. URL/URI structures will grow, and when referencing other services, engineerswill need to understand the current structure and layout of the site or platform toaddress each of the services. Y 轴分割也有缺点。它们在工程时间上的实施成本往往比 x 轴分割更高,因为工程师要么需要重写,要么至少需要从整体应用程序中分解服务。运营和基础设施团队现在需要支持不止一种服务器配置。这反过来可能意味着运营环境中存在不止一种类型或规模的服务器,以便为每种类型获得最具成本效益的系统。当涉及缓存时,数据在不同系统中的缓存方式可能不同,但我们强烈建议在所有分片之间共享标准的缓存方法。 URL/URI 结构将会增长,并且在引用其他服务时,工程师将需要了解站点或平台的当前结构和布局来处理每项服务。 #####Summarizing the Application Y-Axis Y 轴应用总结 The y-axis of the AKF Application Scale Cube represents separation of work by service or func-tion within the application. AKF 应用程序规模立方体的 y 轴表示应用程序中按服务或功能划分的工作。 Y-axis splits are meant to address the issues associated with growth and complexity in codebase and datasets. The intent is to create both fault isolation as well as reduction in responsetimes for y-axis split transactions. Y 轴拆分旨在解决与代码库和数据集的增长和复杂性相关的问题。目的是创建故障隔离并减少 y 轴拆分事务的响应时间。 Y-axis splits can scale transactions, data sizes, and code base sizes. They are most effec-tive in scaling the size and complexity of your code base. They tend to cost a bit more than x-axis splits as the engineering team either needs to rewrite services or at the very least disag-gregate them from the original monolithic application. Y 轴分割可以缩放事务、数据大小和代码库大小。它们在扩展代码库的大小和复杂性方面最有效。它们的成本往往比 x 轴拆分高一些,因为工程团队要么需要重写服务,要么至少需要将它们从原始的整体应用程序中分离出来。 ####The Z-Axis of the AKF Application Scale Cube AKF 应用比例立方体的 Z 轴 The z-axis of the Application Scale Cube is a split based on a value that is “lookedup” or determined at the time of the transaction; most often, this split is based on therequestor or customer of the transaction. The requestor and the customer may becompletely different people. The requestor, as the name implies, is the person submit-ting a request to the product or platform, whereas the customer is the person whowill receive the response or benefit of the request. Note that these are the most com-mon implementations of the z-axis, but not the only possible implementation. For Inorder for the z-axis split to be valuable, it must help partition not only transactions,but the data necessary to operate on those transactions. A y-axis split helps us reducedata and complexity by reducing instructions and data necessary to perform a service;a z-axis split attempts to do the same thing through nonservice oriented segmentation. 应用程序规模立方体的 z 轴是基于“查找”或在交易时确定的值进行分割的;大多数情况下,这种分割是基于交易的请求者或客户。请求者和客户可能是完全不同的人。顾名思义,请求者是向产品或平台提交请求的人,而客户则是将收到请求的响应或受益的人。请注意,这些是 z 轴最常见的实现,但不是唯一可能的实现。为了使 z 轴分割有价值,它不仅必须帮助分区事务,而且还必须帮助分区操作这些事务所需的数据。 y 轴拆分通过减少执行服务所需的指令和数据来帮助我们减少数据和复杂性;z 轴拆分尝试通过非面向服务的分段来完成相同的操作。 To perform a z-axis split, we look for similarities among groups of transactionsacross several services. If a z-axis split is performed in isolation of the x- and y-axis,each split will be a monolithic code base. If N unique splits are identified, it is possi-ble that each of the N instances will be the same exact code base, but this does notnecessarily need to be the case. We may, for example, decide that we will allow somenumber of our N servers to have greater functionality than the remainder of the serv-ers. This might be the case if we have a “free” section of our services and a “paid”section of our services. Our paying customers may get greater functionality and as aresult be sent to a separate server or set of servers. The paying code base may then bea super set of the free code base. 为了执行 z 轴分割,我们寻找跨多个服务的事务组之间的相似性。如果 z 轴拆分是独立于 x 轴和 y 轴执行的,则每个拆分将是一个整体代码库。如果识别出 N 个唯一的分割,则 N 个实例中的每一个实例都可能是完全相同的代码库,但这不一定是这种情况。例如,我们可能决定允许 N 个服务器中的某些服务器比其余服务器具有更强大的功能。如果我们的服务有“免费”部分和“付费”部分,情况可能就是这样。我们的付费客户可能会获得更强大的功能,并因此被发送到单独的服务器或一组服务器。那么付费代码库可以是免费代码库的超集。 How do we get benefits in a z-axis split if we have the same monolithic code baseacross all instances? The answer lay in the activities of the individuals interactingwith those servers and the data necessary to complete those transactions. So manyapplications and sites today require extensive caching that it becomes nearly impossi-ble to cache all the necessary data for all potential transactions. Just as the y-axis splithelped us cache some of this data for unique services, so does the z-axis split help uscache data for specific groups or classes of transactions biased by user characteristics.Let’s take AllScale’s customer resource manager (CRM) solution as an example. Itwould make a lot of sense that a set of sales personnel within a given company wouldhave a lot in common and as a result that we might get considerable benefit fromcaching data unique to that company within a z-axis split. In the event that a com-pany is so small that it doesn’t warrant having a single system dedicated to it, weimplement multitenancy and allow multiple small companies to exist on a singleserver. We gain the benefit of caching unique to the companies in question while alsoleveraging the cost benefits of a multitenant system. Furthermore, we don’t subjectthe larger companies to cache misses resulting from infrequent accesses from smallcompanies that force the larger company data out of the cache. 如果我们在所有实例中拥有相同的整体代码库,我们如何从 z 轴拆分中获得好处?答案在于与这些服务器交互的个人的活动以及完成这些交易所需的数据。如今,许多应用程序和站点都需要大量缓存,因此几乎不可能缓存所有潜在事务的所有必要数据。正如 y 轴拆分帮助我们缓存某些独特服务的数据一样,z 轴拆分也帮助我们缓存受用户特征影响的特定交易组或交易类别的数据。让我们将 AllScale 的客户资源管理器 (CRM) 解决方案视为一个例子。给定公司内的一组销售人员有很多共同点是很有意义的,因此我们可以通过在 z 轴分割内缓存该公司独有的数据来获得相当大的好处。如果公司规模太小,以至于不保证有一个专用的系统,我们会实施多租户并允许多个小公司存在于一台服务器上。我们获得了相关公司特有的缓存优势,同时还利用了多租户系统的成本优势。此外,我们不会让大公司因小公司不频繁访问而导致缓存未命中,从而迫使大公司数据脱离缓存。 We also gain the benefit of fault isolation first identified in Chapter 21.When oneof our servers fails, we only impact a portion of our customers. Moreover, we nowhave a benefit that allows us to roll out code to a portion of our customer base when-ever we are releasing new features. This, in turn, allows us to performance test thecode, validate that the code does not create any significant user incidents, and ensurethat the expected benefits of the release are achieved before we roll or push to theremainder of our clients. 我们还获得了第 21 章中首次提到的故障隔离的好处。当我们的一台服务器发生故障时,我们只会影响一部分客户。此外,我们现在还有一个好处,允许我们在发布新功能时向部分客户群推出代码。反过来,这使我们能够对代码进行性能测试,验证代码不会造成任何重大的用户事件,并确保在我们滚动或推送到其余客户之前实现发布的预期好处。 Because we are splitting transactions across multiple systems, in this particularcase identified by companies, we can achieve a transactional scale similar to thatwithin the x-axis. Unfortunately, as with the y-axis, we increase our operational com-plexity somewhat as we now have pools of services performing similar functions fordifferent clients, requesters, or destinations. And unlike the y-axis, we don’t likely getthe benefit of splitting up our architecture in a service oriented fashion; our engineersdo not necessarily become more proficient with areas of the code just as a result of az-axis split. Finally, there is some software cost associated with z-axis splits in thatthe code must be able to recognize that requests are not all equivalent for any givenservice. Very often, an algorithm to determine where the request should be sent is cre-ated, or a “lookup” service is created that can determine to what system or pod arequest should be sent. 因为我们将交易分散到多个系统中,在这种由公司确定的特殊情况下,我们可以实现类似于 x 轴内的交易规模。不幸的是,与 y 轴一样,我们在某种程度上增加了操作复杂性,因为我们现在拥有为不同客户、请求者或目的地执行类似功能的服务池。与 y 轴不同,我们不太可能获得以面向服务的方式拆分架构的好处;我们的工程师不一定会因为 z 轴分割而变得更加精通代码区域。最后,存在一些与 z 轴分割相关的软件成本,因为代码必须能够识别请求对于任何给定服务并不都是等效的。通常,会创建一个算法来确定应将请求发送到何处,或者创建一个“查找”服务来确定应将请求发送到哪个系统或 Pod。 The benefits of a z-axis split then are that we increase fault isolation, increasetransactional scalability, and increase the cache-ability of objects necessary to com-plete our transactions. You might also offer different levels of service to different cus-tomers, though to do so you might need to implement a y-axis split within a z-axissplit. The end results we would expect from these are higher availability, greater scal-ability, and faster transaction processing times. z 轴拆分的好处是我们可以增强故障隔离、增强事务可扩展性以及增强完成事务所需的对象的缓存能力。您还可以为不同的客户提供不同级别的服务,但为此您可能需要在 z 轴拆分中实现 y 轴拆分。我们期望的最终结果是更高的可用性、更大的可扩展性和更快的事务处理时间。 The z-axis, however, does not help us as much with code complexity, nor does ithelp with time to market. We also add some operational complexity to our produc-tion environment; we now need to monitor several different systems with similarcode bases performing similar functions for different clients. Configuration files maydiffer as a result and systems may not be easily moved once configured dependingupon your implementation. 然而,z 轴对我们降低代码复杂性没有多大帮助,也对缩短上市时间没有帮助。我们还为我们的生产环境增加了一些操作复杂性;我们现在需要监控几个不同的系统,这些系统具有相似的代码库,为不同的客户端执行相似的功能。因此,配置文件可能会有所不同,并且根据您的实施情况,配置后系统可能无法轻松移动。 Because we are leveraging characteristics unique to a group of transactions, wecan also improve our disaster recovery plans by geographically dispersing our ser-vices. We can, for instance, locate services closer to the clients using or requestingthose services. Thinking back to our sales lead system, we could put several smallcompanies in one geographic area on a server close to those companies; and for alarge company with several sales offices, we might split that company into severalsales office systems spread across the company and placed near the offices in ques-tion. 因为我们利用了一组事务的独特特征,所以我们还可以通过在地理上分散我们的服务来改进我们的灾难恢复计划。例如,我们可以将服务定位到距离使用或请求这些服务的客户更近的地方。回想一下我们的销售线索系统,我们可以将一个地理区域中的几家小公司放在靠近这些公司的服务器上;对于拥有多个销售办事处的大公司,我们可以将该公司拆分为多个分布在整个公司的销售办事处系统,并将其放置在相关办事处附近。 #####Summarizing the Application Z-Axis Z轴应用总结 The z-axis of the AKF Application Scale Cube represents separation of work based onattributes that are looked up or determined at the time of the transaction. Most often, these areimplemented as splits by requestor, customer, or client. AKF Application Scale Cube 的 z 轴表示基于事务时查找或确定的属性的工作分离。大多数情况下,这些是由请求者、客户或客户端以拆分的形式实现的。 Z-axis splits tend to be the most costly implementation of the three types of splits. Althoughsoftware does not necessarily need to be disaggregated into services, it does need to be writ-ten such that unique pods can be implemented. Very often, a lookup service or deterministicalgorithm will need to be written for these types of splits. Z 轴分割往往是三种分割类型中成本最高的实现方式。尽管软件不一定需要分解为服务,但它确实需要写入十个以便可以实现独特的 Pod。通常,需要为这些类型的拆分编写查找服务或确定性算法。 Z-axis splits aid in scaling transaction growth, may aid in scaling instruction sets, and aids indecreasing processing time by limiting the data necessary to perform any transaction. The z-axis is most effective at scaling growth in customers or clients. Z 轴分割有助于扩展事务增长,可能有助于扩展指令集,并通过限制执行任何事务所需的数据来帮助减少处理时间。 z 轴对于扩大客户或客户的增长最为有效。 ####Putting It All Together 把它们放在一起 We haven’t really modified our original AKF Scale Cube from the introduction withinthis chapter, but we have attempted to clarify it from an application perspective. Wedid not redefine the axes, but rather focused the previous meaning to the context ofsplitting applications for scale. 我们并没有真正修改本章介绍中的原始 AKF Scale Cube,但我们尝试从应用程序的角度对其进行澄清。我们没有重新定义轴,而是将先前的含义集中在规模拆分应用程序的上下文中。 The observant reader has probably also figured out by now that we are going toexplain why you need multiple axes of scale. To mix things up a bit, we will workbackward through the axes and first explain the problems with implementing them inisolation. 细心的读者现在可能也已经明白,我们将解释为什么需要多个尺度轴。为了把事情搞混一点,我们将通过轴向后工作,并首先解释隔离实现它们的问题。 A z-axis only implementation has several problems when implemented in isola-tion. Let’s assume the previous case where you make N splits of your customer basein a sales lead tracking system. Because we are only implementing the z-axis here,each instance is a single virtual or physical server. If it fails for hardware or softwarereasons, the services for that customer or set of customers have become completelyunavailable. That availability problem alone is reason enough for us to implement anx-axis split for each of our z-axis splits. If we split our customer base N ways alongthe z-axis, with each of the N splits having at least 1/Nth of our customers initially,we would put at least two “cloned” or x-axis servers in each of the N splits. Thisensures that should a server fail we still service the customers in that pod. ReferenceFigure 23.2 as we discuss this implementation further. 当单独实现时,仅 z 轴的实现存在几个问题。让我们假设之前的情况,您在销售线索跟踪系统中对客户群进行 N 次划分。因为我们在这里只实现 z 轴,所以每个实例都是一个虚拟或物理服务器。如果由于硬件或软件原因出现故障,则该客户或该组客户的服务将完全不可用。仅可用性问题就足以让我们为每个 z 轴分割实现 x 轴分割。如果我们沿 z 轴将客户群划分为 N 种方式,并且 N 个划分中的每个划分最初至少有 1/N 的客户,那么我们将在 N 个划分中的每个划分中至少放置两个“克隆”或 x 轴服务器。这确保了如果服务器发生故障,我们仍然可以为该 Pod 中的客户提供服务。当我们进一步讨论这个实现时,请参考图 23.2。 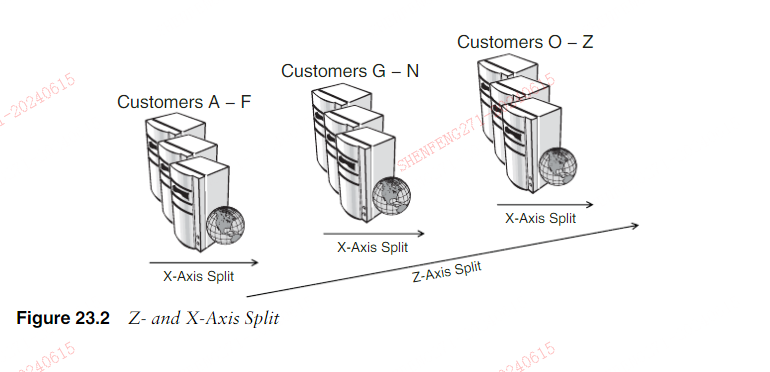 It is likely more costly for us to perform continued customer oriented splits toscale our transactions than it is to simply add servers within one of our customer ori-ented splits. Operationally, it should be pretty simple, assuming that we do not havea great deal of state enabled to simply add a cloned system to our service for anygiven customer. Therefore, in an effort to reduce overall cost of scale, we will proba-bly implement a z-axis split with an x-axis split within each z-axis split. We can alsonow perform x-axis scale within each of our N number of z-axis pods. If a customergrows significantly in transactions, we can perform a cost-effective x-axis split (theaddition of more cloned servers) within that customer’s pod. 对于我们来说,执行持续的面向客户的拆分来扩展我们的交易可能比简单地在面向客户的拆分之一中添加服务器的成本更高。从操作上来说,它应该非常简单,假设我们没有启用大量状态来简单地将克隆系统添加到我们为任何给定客户的服务中。因此,为了降低总体规模成本,我们可能会实现 z 轴分割,并在每个 z 轴分割内包含 x 轴分割。我们现在还可以在 N 个 z 轴 Pod 中的每个中执行 x 轴缩放。如果客户的交易量显着增长,我们可以在该客户的 Pod 内执行经济高效的 X 轴拆分(添加更多克隆服务器)。 Finally, as we have previously mentioned, the z-axis split really does not help uswith code complexity. As our functionality increases and the size of our applicationgrows, performing x-and z-axis splits alone will not allow us to focus and gain expe-rience on specific features or services. Our time to market will likely suffer. We mayalso find that the large monolithic z- and x-axis splits will not help us enough for allof the functions that need cached data. A single, very active customer, focused onmany of his own clients within our application, may find that a monolithic applica-tion is just too slow. This would force us to focus more on y-axis splits as well. 最后,正如我们之前提到的,z 轴分割确实对我们降低代码复杂性没有帮助。随着我们的功能增加和应用程序大小的增长,单独执行 x 轴和 z 轴分割将无法让我们专注于特定功能或服务并获得特定功能或服务的经验。我们的上市时间可能会受到影响。我们还可能发现,大的整体 z 轴和 x 轴分割对于所有需要缓存数据的函数来说并不能提供足够的帮助。一个非常活跃的客户,在我们的应用程序中专注于他自己的许多客户,可能会发现单一应用程序太慢了。这也将迫使我们更多地关注 y 轴分割。 The y-axis split has its own set of problems when implemented in isolation. Thefirst is similar to the problem of the x-axis split in that a single server focused on asubset of functionality results in the functionality being unavailable when the serverfails. As with the z-axis split, we are going to want to increase our availability byadding another cloned or x-axis server for each of our functions. We also save moneyby adding servers in an x-axis fashion for each of our y-axis splits versus continuingto split along the y-axis. Rather than modifying the code and further deconstructingit, we simply add servers into each of our y-axis splits and bypass the cost of furthercode modification. 单独实现时,y 轴分割有其自身的一系列问题。第一个类似于 x 轴分割的问题,因为单个服务器专注于功能子集,导致当服务器发生故障时该功能不可用。与 z 轴拆分一样,我们希望通过为每个功能添加另一个克隆或 x 轴服务器来提高可用性。我们还通过以 x 轴方式为每个 y 轴拆分添加服务器而不是继续沿 y 轴拆分来节省资金。我们不需要修改代码并进一步解构它,而是简单地将服务器添加到每个 y 轴分割中,并绕过进一步代码修改的成本。 The y-axis split also does not scale as well with customer growth as the z-axissplit. Y-axis splits focus more on the cache-ability of similar functions and work wellwhen we have an application growing in size and complexity. Imagine, however, thatyou have decided to perform a y-axis split of your login functionality and that manyof your client logins happen between 6 AM to 9 AM Pacific Time. Assuming that youneed to cache data to allow for efficient logins, you will likely find that you need toperform a z-axis split of the login process to gain a higher cache hit ratio. As statedbefore, y-axis splits help most with growth in the application and functionality, x-axis splits are most cost-effective for transaction growth, and z-axis splits aid most inthe growth of customers and users. y 轴分割也不像 z 轴分割那样随着客户增长而扩展。 Y 轴分割更多地关注类似函数的缓存能力,并且当我们的应用程序规模和复杂性不断增长时,它可以很好地工作。然而,想象一下,您决定对登录功能执行 y 轴分割,并且您的许多客户端登录发生在太平洋时间上午 6 点到上午 9 点之间。假设您需要缓存数据以实现高效登录,您可能会发现需要对登录过程执行 z 轴分割以获得更高的缓存命中率。如前所述,y 轴拆分对应用程序和功能的增长最有帮助,x 轴拆分对交易增长最具成本效益,而 z 轴拆分对客户和用户的增长最有帮助。 As we’ve stated previously, the x-axis approach is often the easiest to implementand as such is very often the very first type of split within systems or applications. Itscales well with transactions, assuming that the application does not grow in com-plexity and that the transactions come from a defined base of slowly growing cus-tomers. As your product becomes more feature rich, you are forced to start lookingat ways to make the system respond more quickly to user requests. You do not want,for instance, long searches to slow down the average response time of short durationactivities such as logins. To resolve average response time issues caused by competingfunctions, you need to implement a y-axis split. 正如我们之前所说,x 轴方法通常是最容易实现的,因此通常是系统或应用程序内的第一种分割类型。假设应用程序的复杂性不会增加,并且交易来自缓慢增长的客户群,那么它可以很好地扩展交易。随着您的产品功能变得更加丰富,您被迫开始寻找使系统更快地响应用户请求的方法。例如,您不希望长时间的搜索会减慢登录等短期活动的平均响应时间。要解决由竞争功能引起的平均响应时间问题,您需要实现 y 轴拆分。 The x-axis also does not handle a growth in customer base elegantly. As your cus-tomers increase and as the data elements necessary to support them within an appli-cation increases, you need to find ways to segment these data elements to allow formaximum cost effective scale such as with y- or z-axis splits. X 轴也不能很好地处理客户群的增长。随着客户的增加以及应用程序中支持客户所需的数据元素的增加,您需要找到对这些数据元素进行分段的方法,以实现最大的成本效益规模,例如使用 y 轴或 z 轴拆分。 #####AKF Application Scale Cube Summary AKF 应用规模立方体摘要 Here is a summary of the three axes of scale: 这是三个尺度轴的总结 * The x-axis represents the distribution of the same work or mirroring of an application across multiple entities. It is useful for scaling transaction volume cost effectively, but does not scale well with data volume growth. * x 轴表示同一工作或应用程序镜像在多个实体之间的分布。它对于有效地扩展交易量很有用,但不能随着数据量的增长而很好地扩展。 * The y-axis represents the distribution and separation of work responsibilities by verb or action across multiple entities. The y-axis can benefit development time as services are now implemented separately. It also helps with transaction growth and fault isolation. It helps to scale data specific to features and functions, but does not greatly benefit cus-tomer data growth. * y 轴表示多个实体之间按动词或操作划分的工作职责的分布和分离。由于服务现在是单独实施的,因此 y 轴可以缩短开发时间。它还有助于事务增长和故障隔离。它有助于扩展特定于特性和功能的数据,但不会对客户数据增长带来很大好处。 * The z-axis represents distribution and segmentation of work by customer, customer need, location, or value. It can create fault isolation and scale along customer bound-aries. It does not aid in the growth of data specific to features or functions nor does it aid in reducing time to market. * z 轴表示按客户、客户需求、位置或价值划分的工作分布和细分。它可以创建故障隔离并沿着客户边界进行扩展。它无助于特定于特性或功能的数据的增长,也无助于缩短上市时间。 Hence, x-axis splits are mirror images of functions, y-axis splits separate applications basedon the work performed, and z-axis splits separate work by customer, location, or some valuespecific identifier (like a hash or modulus). 因此,x 轴分割是函数的镜像,y 轴根据执行的工作分割单独的应用程序,z 轴根据客户、位置或某些值特定标识符(如哈希或模数)分割单独的工作。 ####Practical Use of the Application Cube 应用程序立方体的实际使用 Let’s examine the practical use of our application cube for three unique purposes.The first business we will discuss is an ecommerce auction site, the second isAllScale’s human resources management (HRM) solution, and the third is AllScale’sback office IT implementation. 让我们来看看我们的应用程序立方体在三个独特用途中的实际用途。我们将讨论的第一个业务是电子商务拍卖网站,第二个是 AllScale 的人力资源管理 (HRM) 解决方案,第三个是 AllScale 的后台 IT 实施。 #####Ecommerce Implementation 电子商务实施 The engineering team at AllScale has been hard at work developing ecommerce func-tionality in addition to its CRM and HRM functionality. The new platform providesfunctionality to sell goods, which range from argyle sweaters to ZZ Top CDs.AllScale intends to sell it all, and it also allows other folks to list their goods for saleon its site. AllScale’s platform has all the functionality you can imagine, includingsearching, browsing, shopping carts, checkout, account and order status functional-ity, and so on. The platform also offers multiple buying formats from auctions tofixed price sales. 除了 CRM 和 HRM 功能之外,AllScale 的工程团队一直在努力开发电子商务功能。新平台提供了销售商品的功能,范围从菱形毛衣到 ZZ Top CD。AllScale 打算出售所有商品,并且还允许其他人在其网站上列出待售商品。 AllScale 的平台拥有您能想象到的所有功能,包括搜索、浏览、购物车、结账、帐户和订单状态功能等等。该平台还提供从拍卖到固定价格销售的多种购买形式。 The AllScale architects ultimately decide that the system is going to be constrainedin three dimensions: transaction growth, functionality growth, and the third dimen-sion consisting of both catalog growth and customer growth. As such, they are goingto need to rely on all three axes of the AKF Application Scale Cube. AllScale 架构师最终决定系统将在三个维度上受到限制:交易增长、功能增长以及由目录增长和客户增长组成的第三个维度。因此,他们将需要依赖 AKF Application Scale Cube 的所有三个轴。 The architects decide that it makes most sense to split the application primarily bythe functions of the site. Most of the major functions that don’t directly rely on cus-tomer information will get a swim lane of functionality (see Chapter 21). Browsing,searching, catalog upload, inventory management, and so on and every other verbthat can be performed without needing to know specific information about a particu-lar customer becomes a branch of functionality within the site and its own code base.These splits allow these services to grow with transaction volume regardless of cus-tomer growth as the number of customers isn’t important when delivering the resultsof a search, or a catalog upload, and so on. 架构师认为,主要根据站点的功能来划分应用程序是最有意义的。大多数不直接依赖客户信息的主要功能将获得一条功能泳道(参见第 21 章)。浏览、搜索、目录上传、库存管理等等,以及无需了解特定客户的具体信息即可执行的所有其他动词都成为网站及其自己的代码库内的功能分支。这些拆分允许这些功能无论客户增长如何,服务都会随着交易量的增长而增长,因为在提供搜索结果或目录上传等时,客户数量并不重要。 All applications regarding customers will be split into N pods, where N is a config-urable number. Each of these pods will host roughly 1/Nth of our customers. This is az-axis split of our customer base. Within each of these z-axis splits, the architects aregoing to perform y-axis splits of the code base. Login/logout will be its own function,checkout will be its own function, account status and summary will be its own func-tion, and so on. Note that AllScale doesn’t have N u M (where M is the number of y-axis splits and N is the number of z-axis splits) separate code bases here; it is simplyreplicating the M code bases across N pods for a total of M new code splits for cus-tomer functionality. In deciding to split by both the y- and z-axis in this case, AllScalecan scale its number of customers and the amount of code functionality dedicated tothem independently. No single y-lane will need to know about more than 1/Nth thecustomers; as a result, caching for things like login information will be much morelightweight and much faster. The resulting splits are shown in Figure 23.3. 所有与客户相关的应用程序将被分为 N 个 Pod,其中 N 是一个可配置的数字。每个 Pod 将容纳大约 1/N 的客户。这是我们客户群的 z 轴划分。在每个 z 轴分割中,架构师将执行代码库的 y 轴分割。登录/注销将是它自己的功能,结帐将是它自己的功能,帐户状态和摘要将是它自己的功能,等等。请注意,AllScale 在这里没有 N u M(其中 M 是 y 轴分割数,N 是 z 轴分割数)单独的代码库;它只是在 N 个 Pod 之间复制 M 个代码库,以便为客户功能提供总共 M 个新代码分割。在这种情况下,在决定按 y 轴和 z 轴进行分割时,AllScale 可以独立扩展其客户数量以及专用于客户的代码功能量。没有任何一个 y 通道需要了解超过 1/N 的客户;因此,诸如登录信息之类的缓存将变得更加轻量且更快。分割结果如图 23.3 所示。 Finally, AllScale will apply x-axis splits everywhere to scale the number of transac-tions through any given segmentation. Search is an area about which we are con-cerned, as AllScale wants very fast searches and is concerned about the responsetimes. This, however, is more of a data scaling issue, so we will address this in Chap-ter 24, Splitting Databases for Scale. 最后,AllScale 将在任何地方应用 x 轴分割,以通过任何给定的分割来缩放交易数量。搜索是我们关心的一个领域,因为 AllScale 想要非常快的搜索并且关心响应时间。然而,这更多的是一个数据扩展问题,因此我们将在第 24 章“拆分数据库以实现扩展”中解决这个问题。 #####Human Resources ERP Implementation 人力资源ERP实施 Recall the AllScale HRM solution, which does absolutely everything for HR organi-zations including recruiting, training, career progression counseling, performancereviews, succession planning, compensation analysis, termination automation, and soon. If an HR professional needs it, AllScale does it, all in a SaaS environment. AllScale’slargest customer happens to be the largest company in the world, FullScale Oil, andits smallest client is a 20-person startup in New York City, FullScale Attitude. 回想一下 AllScale HRM 解决方案,它绝对可以为人力资源组织做所有事情,包括招聘、培训、职业发展咨询、绩效评估、继任计划、薪酬分析、终止自动化等等。如果人力资源专业人士需要,AllScale 就能满足,一切都在 SaaS 环境中进行。 AllScale 最大的客户恰好是世界上最大的公司 FullScale Oil,而最小的客户是纽约市一家只有 20 人的初创公司 FullScale Attitude。 The architects decide that what they want to build appears to be one large applica-tion to their customers but with each module capable of growing in complexity withoutaffecting other modules in the system. They also want to be able to work on one ormore modules without taking the system down; as a result, they decide to use they-axis of the AKF Application Scale Cube and separate their services by major func-tionality. Performance and Career Planning, Learning and Education, ComplianceTracking, Recruiting, Compensation Planning, and Succession Planning all becomemodules with other modules scheduled for the future. 架构师决定他们想要构建的似乎是一个对客户来说是一个大型应用程序,但每个模块都能够在不影响系统中其他模块的情况下增加复杂性。他们还希望能够在不关闭系统的情况下处理一个或多个模块;因此,他们决定使用 AKF Application Scale Cube 的“they-axis”并按主要功能分离他们的服务。绩效和职业规划、学习和教育、合规跟踪、招聘、薪酬规划和继任规划都将成为模块,并与未来计划的其他模块一起使用。 The team also recognizes the need to be able to scale its application within a com-pany and that transactions and personnel will all be impacted by company size. Assuch, they will scale using the x-axis to allow for transaction growth and the z-axis toallow for employee growth. The team employs a configurable number, N, as a modu-lus to employee number to determine which pod an employee will be sent within anygiven company or group of companies. 该团队还认识到需要能够在公司内部扩展其应用程序,并且交易和人员都会受到公司规模的影响。因此,他们将使用 x 轴进行扩展以允许交易增长,使用 z 轴进行扩展以允许员工增长。该团队使用可配置的数字 N 作为员工编号的模数,以确定员工将被发送到任何给定公司或公司集团内的哪个 Pod。 #####Back Office IT System 后台IT系统 The AllScale architects are asked to design a system to create personalized marketingemails for its current and future client bases. The team can expect that it will haveseveral different email campaigns under development or shipping at any given timeand that each of these campaigns will need to select from a diverse mailing list thatincludes attributes about many potential and current customers. These attributes areelements such as age, sex, geographic area, past purchases, and so on. AllScale 架构师被要求设计一个系统,为其当前和未来的客户群创建个性化营销电子邮件。团队可以预期在任何给定时间都会有几个不同的电子邮件活动正在开发或发货,并且每个活动都需要从包含许多潜在和当前客户属性的不同邮件列表中进行选择。这些属性包括年龄、性别、地理区域、过去的购买记录等元素。 The list is very large, and the team decides to split it up by classes of data relevantto each of the existing and potential customers. The team needs to ensure that mailcampaigns launch and finish within a few hours, so they are going to need a fairlyaggressive split of their mail system given the number of mails that we send. 该列表非常大,团队决定按与每个现有和潜在客户相关的数据类别对其进行拆分。团队需要确保邮件活动在几个小时内启动并完成,因此考虑到我们发送的邮件数量,他们将需要对邮件系统进行相当积极的拆分。 The architects select four elements including recency, frequency, monetization, andclass of purchase as criteria, and the product of these values result in 100 unique clas-sifications. Each of these classifications contains roughly 1/100th of the people, withthe exception of the customers for whom we have no sales data and therefore justrepresent a contact list. This set of customers actually represents the largest group bypopulation, and for them the team simply splits on contact_id, which is a unique keywithin the system. The AllScale architects select a configurable number N for thissplit and set N initially to 100. As such, it has 199 unique Z splits: 100 splits for cus-tomers who have yet purchased anything from AllScale and for whom we have no data,and 99 splits for all other customers split by a product of their recency, frequency,monetization (aggregate value), and classification of purchases. These splits corre-spond primarily to the mail and tracking farms (described in the following section)but also to the data repositories that we will describe in further detail in Chapter 24. 架构师选择了四个元素,包括新近度、频率、货币化和购买类别作为标准,这些值的乘积产生了 100 个独特的分类。每个类别大约包含 1/100 的人员,但我们没有销售数据因此仅代表联系人列表的客户除外。这组客户实际上代表了最大的群体,对于他们来说,团队只需根据 contact_id 进行划分,这是系统内的唯一键。 AllScale 架构师为此分割选择了一个可配置的数字 N,并将 N 初始设置为 100。因此,它有 199 个独特的 Z 分割:100 个分割用于尚未从 AllScale 购买任何产品且我们没有数据的客户,99 个分割适用于尚未从 AllScale 购买任何产品且我们没有数据的客户。所有其他客户的划分按其新近度、频率、货币化(总价值)和购买分类的乘积划分。这些分割主要对应于邮件和跟踪场(在下一节中描述),但也对应于我们将在第 24 章中进一步详细描述的数据存储库。 The y-axis splits then become the functions of the AllScale marketing system. Theteam will need a creative development system, a mail sending system, a mail viewingsystem, a mail reporting system, and a customer tracking system to view the efficacyof its campaigns and a data warehouse to handle all past campaign reporting. Theseare all y-axis splits to give the system additional scale in transactions and to allow theteam to modify components independent of each other. Y 轴分割随后成为 AllScale 营销系统的功能。该团队将需要一个创意开发系统、一个邮件发送系统、一个邮件查看系统、一个邮件报告系统和一个客户跟踪系统来查看其活动的效果,以及一个数据仓库来处理所有过去的活动报告。这些都是 y 轴分割,以便为系统提供额外的交易规模,并允许团队修改彼此独立的组件。 Most systems will have at least one extra system for availability, but some willhave multiple clones such as the mail sending system within each of the Z splits. 大多数系统将至少有一个额外的系统以确保可用性,但有些系统将有多个克隆,例如每个 Z 分区内的邮件发送系统。 #####Observations 观察结果 You may have noticed that while we use each of the axes in the preceding examples,the distribution of the axes appears to change by company or implementation. In oneexample, the z-axis may be more predominant and in others the Y appears to be themost predominant split. This is all part of the “Art of Scalability.” Referring back tothe introduction, the determination in the absence of data about where you start inyour scalability initiatives are as much about gut feel as anything else. As you growand collect data, you will ultimately, hopefully, determine in advance where youmade incorrect assumptions. 您可能已经注意到,虽然我们在前面的示例中使用了每个轴,但轴的分布似乎会根据公司或实施情况而变化。在一个示例中,z 轴可能更占主导地位,而在其他示例中,Y 轴似乎是最主要的分裂。这都是“可扩展性艺术”的一部分。回顾一下引言,在缺乏关于可扩展性计划从何处开始的数据的情况下,决定与其他任何事情一样取决于直觉。随着数据的增长和收集,您最终将有望提前确定自己在哪些地方做出了错误的假设。 Where to draw the line with y-axis splits is not always easy. If you have tens ofthousands of features or “verbs,” it doesn’t make sense to have tens of thousandssplits. You want to have manageable sizes of code bases in each of your splits but notso many splits that the absolute number itself becomes unmanageable. You also wantyour cache sizes in your production environment to be manageable. Both of thesebecome considerations for determining where you should perform splits and howmany you should have. 在哪里绘制 y 轴分割线并不总是那么容易。如果你有数以万计的特征或“动词”,那么数以万计的分割就没有意义。您希望每个拆分中的代码库大小都可以管理,但拆分数量不要过多,以免绝对数量本身变得难以管理。您还希望生产环境中的缓存大小易于管理。这两点都成为确定应该在哪里进行分割以及应该进行多少分割的考虑因素。 Z-axis splits are a little easier from a design perspective. Ideally, you will simplydesign a system that has flexibility built into it. We previously mentioned a config-urable number N in both the ecommerce and back office IT systems. This number iswhat allows us to start splitting application flows by customer within the system. Aswe grow, we simply increase N to allow for greater segmentation and to help smoothload across our production systems. Of course, there is potentially some work in datastorage (where those customers live) that we will discuss in Chapter 24, but weexpect that you can develop tools to help you manage that. The y-axis, unfortunately,is not so easy to design flexibility into the system. 从设计角度来看,Z 轴分割更容易一些。理想情况下,您只需设计一个内置灵活性的系统即可。我们之前提到过电子商务和后台 IT 系统中的可配置数字 N。这个数字使我们能够开始在系统内按客户拆分应用程序流。随着我们的发展,我们只需增加 N 即可实现更大的细分并帮助我们的生产系统平稳加载。当然,我们将在第 24 章中讨论数据存储(这些客户所在的位置)方面可能存在一些工作,但我们希望您可以开发工具来帮助您管理这些工作。不幸的是,y 轴并不是那么容易将灵活性设计到系统中。 As always, the x-axis is relatively easy to split and handle because it is always justa duplicate of its peers. In all of our previous cases, the x-axis is always subordinateto the y- and z-axis. This is almost always the case when you perform y- and z-axissplits. To the point, the x-axis becomes relevant within either a y- or z-axis split.Sometimes, the y- or z-axis, as was the case in more than one of the examples, is sub-ordinate to the other, but in nearly all cases, the x-axis is subordinate to either y or zwhenever the y or z or both are employed. 与往常一样,x 轴相对容易分割和处理,因为它始终只是其对等轴的重复。在我们之前的所有案例中,x 轴始终从属于 y 轴和 z 轴。当您执行 y 轴和 z 轴分割时,几乎总是出现这种情况。就这一点而言,x 轴在 y 轴或 z 轴分割中变得相关。有时,y 轴或 z 轴(如多个示例中的情况)从属于另一个轴,但在几乎所有情况下,只要使用 y 或 z 或两者,x 轴都从属于 y 或 z。 What do you do if and when your business contracts? If you’ve split to allow foraggressive hyper growth and the economy presents your business with a downwardcycle not largely under your control, what do you do? X-axis splits are easy tounwind as you simply remove the systems you do not need. If those systems are fullydepreciated, you can simply power them off for future use when your businessrebounds. Y-axis splits might be hosted on a smaller number of systems, potentiallyleveraging virtual machine software to carve a set of physical servers into multipleservers. Z-axis splits should also be capable of being collapsed onto similar systemseither through the use of virtual machine software or just by changing the boundariesthat indicate which customers reside on which systems. 如果您的业务合同签订,您会怎么做?如果你已经分拆以实现激进的高速增长,而经济给你的企业带来了一个很大程度上不受你控制的下行周期,你会怎么做? X 轴拆分很容易解开,因为您只需删除不需要的系统即可。如果这些系统已完全折旧,您只需将其关闭以供将来业务反弹时使用。 Y 轴拆分可能托管在较少数量的系统上,可能会利用虚拟机软件将一组物理服务器划分为多个服务器。 Z 轴分割还应该能够通过使用虚拟机软件或仅通过更改指示哪些客户驻留在哪些系统上的边界来折叠到类似的系统上。 ####Conclusion 结论 This chapter discussed the employment of the AKF Scale Cube to applications withina product, service, or platform. We modified the AKF Scale Cube slightly, narrowingthe scope and definition of each of the axes so that it became more meaningful toapplication and systems architecture and the production deployment of applications. 本章讨论了 AKF Scale Cube 在产品、服务或平台内的应用程序的使用。我们稍微修改了 AKF Scale Cube,缩小了每个轴的范围和定义,使其对应用程序和系统架构以及应用程序的生产部署变得更有意义。 Our x-axis still addresses the growth in transactions or work performed by anyplatform or system. Although the x-axis handles the growth in transaction volumewell, it suffers when application complexity increases significantly (as measuredthrough the growth in functions and features) or when the number of customers withcacheable data needs grows significantly. 我们的 x 轴仍然涉及任何平台或系统执行的交易或工作的增长。尽管 X 轴可以很好地处理交易量的增长,但当应用程序复杂性显着增加(通过功能和特性的增长来衡量)或具有可缓存数据需求的客户数量显着增加时,它就会受到影响。 The y-axis addresses application complexity and growth. As we grow our productto become more feature rich, it requires more resources. Furthermore, transactionsthat would otherwise complete quickly start to slow down as demand laden systemsmix both fast and slow transactions. Our ability to cache data for all features startsto drop as we run into system constraints. The y-axis helps address all of these whilesimultaneously benefiting our production teams. Engineering teams get to focus onsmaller portions of our complex code base. As a result, defect rates decrease, newengineers come up to speed faster, and expert engineers can develop software faster.Because all axes address transaction scale as well, the y-axis also benefits us as wegrow the transactions against our system, but it is not as easily scaled in this dimen-sion as the x-axis. y 轴表示应用程序的复杂性和增长。随着我们的产品功能变得更加丰富,它需要更多的资源。此外,由于需求负载系统混合了快速和慢速事务,原本可以快速完成的事务开始减慢。当遇到系统限制时,我们缓存所有功能数据的能力开始下降。 y 轴有助于解决所有这些问题,同时使我们的生产团队受益。工程团队可以专注于复杂代码库的较小部分。结果,缺陷率降低,新工程师的速度更快,专家工程师可以更快地开发软件。因为所有轴也都解决事务规模,所以当我们根据系统增加事务时,y 轴也使我们受益,但它是在这个维度上不像 x 轴那么容易缩放。 The z-axis addresses growth in customer base. As we will see in Chapter 24, it canalso help us address growth in other data elements such as product catalogs and soforth. As transactions and customers grow, and potentially as transactions per cus-tomer grow, we will find ourselves in a position that we might need to address thespecific needs of a class of customer. This might be solely because each customer hasan equal need for some small cache space, but it might be that the elements you cacheby customer are distinct by some predefined customer class. Either way, segmentingby requester, customer, or client helps us solve that problem. It also helps us scalealong the transaction growth path, though not as easily as with the x-axis. z 轴解决了客户群的增长问题。正如我们将在第 24 章中看到的,它还可以帮助我们解决其他数据元素(例如产品目录等)的增长问题。随着交易和客户的增长,甚至随着每个客户的交易量的增长,我们将发现自己可能需要满足一类客户的特定需求。这可能仅仅是因为每个客户对一些小型缓存空间都有相同的需求,但也可能是您按客户缓存的元素因某些预定义的客户类别而不同。无论哪种方式,按请求者、客户或客户进行细分都可以帮助我们解决该问题。它还帮助我们沿着交易增长路径进行扩展,尽管不像 x 轴那么容易。 As indicated in Chapter 22, not all companies need all three axes of scale to sur-vive. When more than one axis is employed, the x-axis is almost subordinate to theother axes. You might for instance have multiple x-axis splits, each occurring withina y- or z-axis split. When employing y-and z-axis splits together (typically with anx-axis split), either split can become the “primary” means of splitting. If you splitfirst by customer, you can still make y-axis functionality implementations within eachof your z-axis splits. These would be clones of each other such that login in z-axiscustomer split 1 looks exactly like login for z-axis customer split N. The same is truefor a y-axis primary split; the z-axis implementations within each functionality splitwould be similar or clones of each other. 正如第 22 章所述,并非所有公司都需要所有三个规模轴才能生存。当使用多个轴时,x轴几乎从属于其他轴。例如,您可能有多个 x 轴分割,每个分割都发生在 y 轴或 z 轴分割内。当同时使用 y 轴和 z 轴分割时(通常与 x 轴分割一起使用),任一分割都可以成为分割的“主要”方式。如果您首先按客户进行拆分,您仍然可以在每个 z 轴拆分中实现 y 轴功能。这些将是彼此的克隆,因此 z 轴客户拆分 1 中的登录看起来与 z 轴客户拆分 N 中的登录完全相同。对于 y 轴主要拆分也是如此;每个功能拆分中的 z 轴实现将是相似的或彼此克隆。 #####Key Points 关键点 * X-axis application splits scale linearly with transaction growth. They do nothelp with the growth in code complexity, customers, or data. X-axis splits are“clones” of each other. * X轴应用程序分割规模随交易增长呈线性增长。它们无助于代码复杂性、客户或数据的增长。 X 轴分割是彼此的“克隆”。 * The x-axis tends to be the least costly to implement, but suffers from constraintsin instruction size and dataset. * x 轴的实现成本往往最低,但受到指令大小和数据集的限制。 * Y-axis application splits help scale code complexity as well as transactiongrowth. They are mostly meant for code scale because as they are not as efficientas x-axis in transaction growth. * Y 轴应用程序拆分有助于扩展代码复杂性以及事务增长。它们主要用于代码规模,因为它们在事务增长方面不如 x 轴有效。 * Y-axis application splits also aid in reducing cache sizes where caches sizes scalewith function growth. * Y 轴应用程序分割还有助于减少缓存大小,其中缓存大小随着功能的增长而扩展。 * Y-axis splits tend to be more costly to implement than x-axis splits as a result ofengineering time necessary to separate monolithic code bases. * 由于分离整体代码库所需的工程时间,Y 轴拆分往往比 X 轴拆分的实施成本更高。 * Y-axis splits aid in fault isolation. * Y 轴分割有助于故障隔离。 * Y-axis splits can be performed without code modification, but you might not getthe benefit of cache size reduction and you will not get the benefit of decreasingcode complexity. * Y 轴分割可以在不修改代码的情况下执行,但您可能无法获得缓存大小减少的好处,也无法获得降低代码复杂性的好处。 * Z-axis application splits help scale customer growth, some elements of datagrowth (as we will see in Chapter 24), and transaction growth. * Z 轴应用程序拆分有助于扩展客户增长、数据增长的某些要素(我们将在第 24 章中看到)和交易增长。 * Z-axis application splits can help reduce cache sizes where caches scale in rela-tion to the growth in users or other data elements. * Z 轴应用程序拆分可以帮助减少缓存大小,其中缓存会根据用户或其他数据元素的增长进行扩展。 * As with y-axis splits, z-axis splits aid in fault isolation. They too can be imple-mented without code changes but may not gain the benefit of cache size reduc-tion without some code modification. * 与 y 轴分割一样,z 轴分割有助于故障隔离。它们也可以在不更改代码的情况下实现,但如果不修改一些代码,可能无法获得缓存大小减小的好处。 * The choice of when to use what method or axis of scale is both art and science.Intuition is typically the initial guiding force, whereas production data should beused over time to help inform the decision. * 选择何时使用何种方法或尺度轴既是艺术也是科学。直觉通常是最初的指导力量,而生产数据应该随着时间的推移来帮助做出决定。
没有评论