这篇文章上次修改于 217 天前,可能其部分内容已经发生变化,如有疑问可询问作者。 ### Chapter 22 Introduction to the AKF Scale Cube-AKF Scale Cube简介 > Ponder and deliberate before you make a move.—Sun Tzu > 行动前要深思熟虑。——孙子 Chapter 21, Creating Fault Isolative Architectural Structures, focused on makingthings more fault isolative so that when something failed, either as a result of incred-ible demand or technical glitches, our entire product or service didn’t go away. There,we referred several times to the AKF Scale Cube to highlight methods by which com-ponents of our architecture might be split into swim lanes or failure domains. In thischapter, we are going to reintroduce the AKF Scale Cube. We developed the scalecube to help our clients think about how to split services, data, and transactions, andto a lesser degree as outlined in the introduction, teams and processes. As with ourprinciples, we gave the AKF Scale Cube to our clients as a way to think about scale.Feel free to use it within your own company or for your own purposes. 第 21 章,创建故障隔离架构,重点是让事情变得更加故障隔离,这样当出现故障时,无论是由于令人难以置信的需求还是技术故障,我们的整个产品或服务都不会消失。在那里,我们多次提到 AKF Scale Cube,以重点介绍将架构组件划分为泳道或故障域的方法。在本章中,我们将重新介绍 AKF Scale Cube。我们开发了scalecube来帮助我们的客户思考如何分割服务、数据和交易,并在较小程度上如简介、团队和流程中概述的那样。与我们的原则一样,我们向客户提供 AKF Scale Cube,作为考虑规模的一种方式。您可以在自己的公司内或出于自己的目的随意使用它。 ####Concepts Versus Rules and Tools 概念与规则和工具 Before we reintroduce the cube, we thought it important to discuss why we devel-oped the AKF Scale Cube versus a set of steps, rules, or tools that one might employ.The reason for the development of the cube has its roots in our beliefs regarding thedifference between engineers and technicians. Engineers are taught why somethingworks and this understanding typically starts at a level much lower than the specificdiscipline of engineering in question. Most engineers spend nearly two years learningthe building blocks that they will later apply in the latter two years of a four-yeardegree. Often, the engineer really doesn’t understand why she is learning something,and unfortunately professors don’t create the causal roadmap to success betweenwhat is learned during freshman calculus and how it will ultimately apply to sayFaraday’s law and the calculation of electromagnetic force (EMF) in a sophomorephysics class or a junior core electrical engineering class. Nevertheless, concepts andbuilding blocks are stressed first, and to graduate to the application of these con-cepts, one must first master the concepts themselves. 在重新引入 Cube 之前,我们认为有必要讨论一下为什么我们开发 AKF Scale Cube 以及人们可能使用的一组步骤、规则或工具。开发 Cube 的原因源于我们的信念关于工程师和技术人员之间的区别。工程师被教导为什么某些东西有效,并且这种理解通常从远低于所讨论的工程特定学科的水平开始。大多数工程师花费近两年的时间来学习他们将在四年制学位的后两年中应用的构建模块。通常,工程师真的不明白她为什么要学习某些东西,不幸的是,教授们没有在新生微积分期间学到的知识和它最终如何应用于法拉第定律和电磁力(EMF)计算之间创建成功的因果路线图。 )在大二物理课或大三核心电气工程课上。尽管如此,首先强调的是概念和构建模块,为了逐步应用这些概念,必须首先掌握这些概念本身。 Technicians, on the other hand, are often handed a set of rules and equations andgiven a rote course focused on understanding the rough interrelationships and aretaught how something works. How is predicated on a set of rules that does notrequire understanding why those rules exist or the method by which one would provethe rules work. Why doesn’t start at the level of the rules, but rather deep belowthose rules with the physics and chemistry that ultimately become the building blocksfor those rules. 另一方面,技术人员通常会收到一组规则和方程式,并接受死记硬背的课程,重点是理解粗略的相互关系,并教授某些东西是如何工作的。 How 是基于一组规则,不需要理解这些规则存在的原因或证明规则有效的方法。为什么不从规则的层面开始,而是从这些规则的深处开始,用物理和化学来最终成为这些规则的基石。 Electricians are not in the business of deriving the equations they apply; theirexpertise is in knowing a set of rules that explains how something works. They areexperts in applying those rules and coming up with an action. Electricians are great atplanning electrical infrastructure for projects requiring the application of the same setof tools and the same set of products or components. It is rare, however, to find anelectrician or a technician who is going to create a paradigm shift based on the under-standing of the whys for any given system when they haven’t been taught the reasonsfor the whys. More likely, when looking for major changes to the way somethingoperates and to allow that something to achieve new and higher levels of perfor-mance, you are going to need an engineer. 电工的职责不是推导他们所应用的方程;而是负责推导他们所应用的方程。他们的专长是了解一组解释事物如何运作的规则。他们是应用这些规则并提出行动的专家。电工非常擅长为需要应用同一组工具和同一组产品或组件的项目规划电气基础设施。然而,很少有电工或技术人员在没有被告知原因的情况下,会基于对任何给定系统的原因的理解来创建范式转变。更有可能的是,当寻求对某些操作方式进行重大改变并让某些东西达到新的和更高水平的性能时,您将需要一名工程师。 As such, we developed a cube that consists of concepts rather than rules. The cubeon its own serves as a way to think about the whys of scale and helps create a bridgeto the hows. The cube also serves to facilitate a common language for discussing dif-ferent strategies, just as physics and math serve as the underlying languages for engi-neering discussions. 因此,我们开发了一个由概念而不是规则组成的立方体。立方体本身可以作为思考规模原因的一种方式,并有助于搭建通向如何实现的桥梁。立方体还有助于促进讨论不同策略的通用语言,就像物理和数学作为工程讨论的基础语言一样。 ####Introducing the AKF Scale Cube AKF Scale Cube 简介 Imagine first, if you will, a Rubik’s cube or classic colored children’s building block.Hold this imaginary block directly in from of you, or stare down directly at it so thatyou can only see a single face of the six faces. At this point, the cube is nothing morethan a two-dimensional square, similar to the square seen in Figure 22.1. 如果你愿意的话,首先想象一个魔方或经典的彩色儿童积木。将这个想象中的积木直接放在你的前方,或者直接向下凝视它,这样你只能看到六个面中的一个面。此时,立方体只不过是一个二维正方形,类似于图 22.1 中看到的正方形。  Now take the cube in your hand and rotate it one-eighth of a turn to the left, suchthat the face to the right of the cube is visible and roughly the same size as the origi-nal face you had viewed of the cube. Note that you should not yet see the top or bot-tom of the cube or block in your hand, but rather two roughly equal faces, each ofthem moving at a 45-degree angle away from you to the right and to the left. 现在,将立方体拿在手中,并向左旋转八分之一圈,这样立方体右侧的面就可见,并且与您看到的立方体的原始面的大小大致相同。请注意,您应该还看不到手中的立方体或块的顶部或底部,而是两个大致相等的面,每个面以 45 度角远离您向右和向左移动。 Now for one last turn. Turn the cube roughly one-eighth a turn down. To accom-plish this, you want to take the lower point of the edge created between the two sidesthat you can currently see and rotate it downward or to the 6 o’clock position. Theresult is that you should now see roughly three sides of the cube: the original face,which is now one-eighth of a turn to your left and pointing off at roughly a 45-degreeangle away from you, the right face, which was exposed in the first rotation to theleft, and the top of the cube, which was exposed in the last rotation. The resultshould look something like in the cube show in Figure 22.2. 现在进行最后一轮。将立方体向下转动大约八分之一圈。为了实现这一点,您需要获取当前可以看到的两侧之间创建的边缘的较低点,并将其向下旋转或旋转到 6 点钟位置。结果是,您现在应该看到立方体的大约三个侧面:原始面,现在位于您左侧八分之一圈处,并以大约 45 度角指向远离您的方向,右面,暴露在外在向左的第一次旋转中,以及在最后一次旋转中暴露的立方体的顶部。结果应该类似于图 22.2 中所示的立方体。 On its own, this cube doesn’t offer us much, so we need to add reference points tohelp us in our future discussion. To do this, we will add the traditional three-dimen-sional axes. Adding an x-axis moving from left to right, a y-axis moving up anddown the page, and a z-axis that points out directly behind the cube gives us some-thing that looks like Figure 22.3. 就其本身而言,这个立方体并不能为我们提供太多信息,因此我们需要添加参考点来帮助我们将来的讨论。为此,我们将添加传统的三维轴。添加一个从左向右移动的 x 轴、一个在页面上上下移动的 y 轴以及一个直接指向立方体后面的 z 轴,得到的结果如图 22.3 所示。 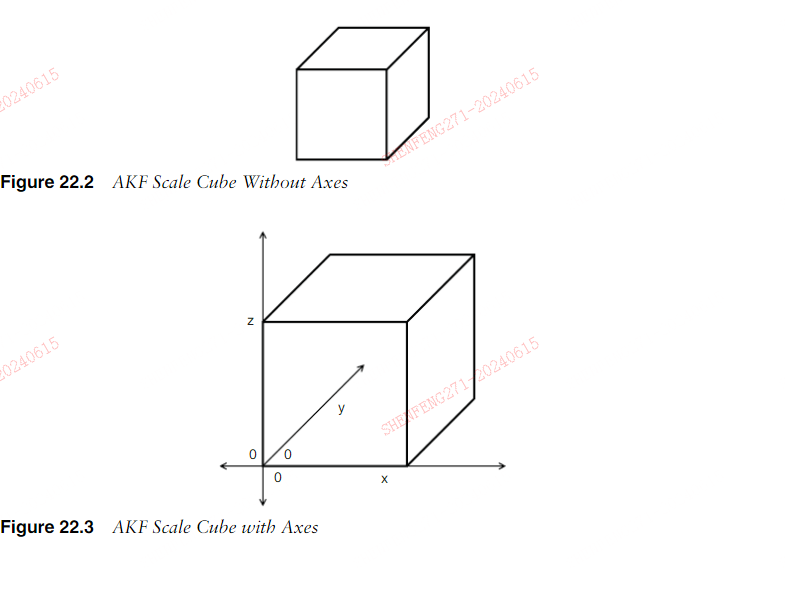 We will call the point of intersection of our three axes the initial point, as refer-enced by the values x = 0, y = 0, and z = 0. 我们将三个轴的交点称为初始点,由值 x = 0、y = 0 和 z = 0 引用。 ####Meaning of the Cube 立方体的意义 The initial point, with coordinates of (0,0,0), is the point of least scalability withinany system. It consists of a single monolithic application and storage retrieval systemlikely running on a single physical system. It might scale “up” (which would violateone of our principles of scale as defined in Chapter 12, Exploring Architectural Prin-ciples) with larger and faster hardware, but it won’t scale “out”; as a result, it willlimit your growth to the growth allowed by the hardware and software available inopen source or through third-party providers. 坐标为 (0,0,0) 的初始点是任何系统中可扩展性最低的点。它由单个整体应用程序和可能在单个物理系统上运行的存储检索系统组成。它可能会使用更大更快的硬件进行“向上”扩展(这将违反我们在第 12 章“探索架构原理”中定义的扩展原则),但它不会“向外”扩展;因此,它将限制您的增长,使其不超过开源或第三方提供商提供的硬件和软件所允许的增长。 As you move along any axis, making modifications, the scalability of your systemis increased. One axis might benefit certain scale characteristics more than others.For instance, a split along the x-axis might allow transaction growth to scale verywell but not materially impact your ability to store, retrieve, and search through cus-tomer, account, or catalog information. To address such a storage or memory con-straint, you might need to consider a y-axis implementation or split. Y-axis splits, onthe other hand, might allow you to split information for the purposes of searchingthrough it faster, but may hinder your efforts when the joining of information isrequired, and for this you might need to consider z-axis splits. 当您沿着任何轴移动并进行修改时,系统的可扩展性就会增加。一个轴可能比其他轴更有利于某些规模特征。例如,沿 x 轴的拆分可能会允许交易增长很好地扩展,但不会对您通过客户、帐户或目录进行存储、检索和搜索的能力产生重大影响信息。要解决此类存储或内存限制,您可能需要考虑 y 轴实现或拆分。另一方面,Y 轴分割可能允许您分割信息以便更快地搜索信息,但在需要连接信息时可能会阻碍您的工作,为此您可能需要考虑 z 轴分割。 The use of one axis does not preclude you from making use of other axes. In theideal case where financial considerations and the need to ensure profitability did notimpact our decisions, we would design for near infinite splits along all three axes.Doing so would give us theoretically infinite scale from a design perspective. Inimplementation, we could choose the lowest cost approach to meeting our real-timescalability needs by selecting the cheapest solution from a split in the x-, y-, or z-axis.Of course, designing for near infinite scale, although cheaper than implementing sucha design, still has costs in terms of engineering and architecture time spent and lostopportunity of revenue associated with the delay in time to market. Furthermore, onlythe fastest growing of hyper-growth platforms really need to consider such a move,which is why we suggested thinking of at least two axes for any given implementation. 使用一个轴并不妨碍您使用其他轴。在理想情况下,财务考虑和确保盈利能力的需要不会影响我们的决策,我们将设计沿所有三个轴的近乎无限的分割。从设计角度来看,这样做理论上会给我们带来无限的规模。在实现中,我们可以通过从 x、y 或 z 轴的拆分中选择最便宜的解决方案来选择成本最低的方法来满足我们的实时可扩展性需求。当然,设计接近无限规模,尽管比实现更便宜这种设计仍然存在工程和架构时间方面的成本,以及因上市时间延迟而失去的收入机会。此外,只有增长最快的超增长平台才真正需要考虑这样的举措,这就是为什么我们建议为任何给定的实现考虑至少两个轴。 In the following sections, we discuss the meaning of each of the axes at a very highlevel. In Chapters 23, Splitting Applications for Scale, and 24, Splitting Databases forScale, we will dig deeper into the most common applications of each of these axes:splitting services and splitting databases. 在以下各节中,我们将在非常高的层面上讨论每个轴的含义。在第 23 章“拆分应用程序以实现规模化”和第 24 章“拆分数据库以实现规模化”中,我们将深入探讨每个轴上最常见的应用程序:拆分服务和拆分数据库。 ####The X-Axis of the Cube 立方体的 X 轴 The x-axis of the AKF Scale Cube represents cloning of services and data with abso-lutely no bias. Perhaps the easiest way to represent such a split is to think first interms of people and organizations. Let’s first consider the days in which typing poolshandled the typing of meeting minutes, letters, internal memos, and so on. Note theuse of the term pool as far back as 50 or more years identifying a service distributedamong several entities (in this case people). Work would be sent to the typing poollargely without a bias as to what individual typist performed the work. Some typistsmight be faster than others and as a result would get more work sent their way andaccomplish more work within the course of a day, but ideally it would not matterwhere any individual piece of work went within the pool. Everyone could type andeveryone was capable of typing one of the set of internal memos, external letters, ormeeting minutes. In effect, other than the speed of the hardware (typewriter) usedand the speed of the person, everyone was a clone and capable of doing the work.This distribution of work among clones is a perfect example of x-axis scalability. AKF Scale Cube 的 x 轴代表绝对无偏见的服务和数据克隆。也许表达这种分裂的最简单方法是首先从人和组织的角度来思考。让我们首先考虑一下打字池处理会议纪要、信件、内部备忘录等打字的日子。请注意,术语“池”的使用可以追溯到 50 年或更久以前,用于标识分布在多个实体(在本例中为人)之间的服务。工作将被发送到打字池,很大程度上不会对执行这项工作的个人打字员产生偏见。有些打字员可能比其他人更快,因此会在一天内收到更多的工作并完成更多的工作,但理想情况下,任何单独的工作在池中的位置并不重要。每个人都可以打字,每个人都能够打字一组内部备忘录、外部信件或会议纪要。实际上,除了所使用的硬件(打字机)的速度和人的速度之外,每个人都是克隆并且有能力完成工作。克隆之间的这种工作分配是x轴可扩展性的完美例子。 Another people example to illustrate our point might be within the accountsreceivable or accounts payable portion of your company’s finance organization. Ini-tially, for small to medium companies, and assuming that the work is not outsourced,the groups might be comprised of a few people, each of whom can perform all of thetasks within his area. The accounts payable staff can all receive bills and generatechecks based on a set of processes and send those checks out or get them counter-signed depending upon the value of the check written. The accounts receivable staff iscapable of generating invoices from data within the system, receiving checks, makingappropriate journal entries, and depositing the checks. Each person can do all of thetasks, and it does not matter to whom the work goes. 另一个说明我们观点的例子可能是贵公司财务组织的应收账款或应付账款部分。最初,对于中小型公司,假设工作不外包,小组可能由几个人组成,每个人都可以执行他所在领域内的所有任务。应付账款员工都可以接收账单并根据一组流程生成支票,然后根据所写支票的价值发送这些支票或进行会签。应收账款工作人员能够根据系统内的数据生成发票、接收支票、制作适当的日记账分录以及存入支票。每个人都可以完成所有任务,并且工作交给谁并不重要。 All three of these examples illustrate the basic concept of the x-axis, which is theunbiased distribution of work across clones. Each clone can do the work of the otherclones and there is no bias with respect to where the work travels (other than individ-ual efficiency). Each clone has the tools and resources to get the work done and willperform the work given to it as quickly as possible. 所有这三个示例都说明了 x 轴的基本概念,即跨克隆的工作的无偏分配。每个克隆都可以完成其他克隆的工作,并且工作转移的地点没有偏见(除了个人效率)。每个克隆都拥有完成工作的工具和资源,并将尽快执行分配给它的工作。 The x-axis seems great! When we need to perform more work, we just add moreclones. Is the number of memorandums exceeding your current typing capacity? Sim-ply add more typists! Is your business booming and there are too many invoices tomake and payments coming in? Add more accounts receivable clerks! Why would weever need any more axes? Let’s return to our typing pool first to answer this question.Let’s assume that in order to write some of our memorandums, external letters,and notes a typist needs to have certain knowledge to complete them. Let’s say thatas the company grows, the services offered by the typing pool increases. The poolnow performs some 100 different types and formats of services and the work is notevenly distributed across these types of services. External client letters have severaldifferent formats that vary by the type of content included within the message, mem-orandums vary by content and intent, and meeting notes vary by the type of meeting,and so on. Now an individual typist may get some work done very fast (the workthat is most prevalent throughout the pool) but be required to spend time looking upthe less frequent formatting, which in turn slows down the entire pipeline of work.As the type of work increases for any given service, more time may be spent trying toget work of varying sizes done; and the instruction set to accomplish this work maynot be easily kept in any given typist’s head. These are all examples of problems asso-ciated with the x-axis of scale; it simply does not scale well with an increase in data,either as instruction sets or reference data. The same holds true if the work varies bythe sender or receiver. For instance, maybe vice presidents and above get special for-matting or are allowed to send different types of communication than directors of thecompany. Perhaps special letterhead or stock is used that varies by the sender. Maybethe receiver of the message causes a variation in tone of communication or paperstock. Account delinquent letters may require a special tone not referenced within thenotes to be typed, for instance. x 轴看起来很棒!当我们需要执行更多工作时,我们只需添加更多克隆即可。备忘录的数量是否超出了您当前的打字能力?只需添加更多打字员即可!您的业务是否正在蓬勃发展,但有太多发票需要开具和付款?增加更多应收账款业务员!为什么威弗还需要更多的斧头?让我们首先回到我们的打字池来回答这个问题。让我们假设为了写一些我们的备忘录、外部信件和笔记,打字员需要具备一定的知识来完成它们。假设随着公司的发展,打字池提供的服务也在增加。该池现在执行大约 100 种不同类型和格式的服务,并且工作在这些类型的服务之间分布并不均匀。外部客户信函有多种不同的格式,这些格式因消息中包含的内容类型而异,备忘录因内容和意图而异,会议记录因会议类型而异,等等。现在,单个打字员可能会非常快地完成一些工作(整个池中最普遍的工作),但需要花时间查找不太频繁的格式,这反过来又减慢了整个工作流程。随着工作类型的增加对于任何给定的服务,可能会花费更多的时间来尝试完成不同规模的工作;完成这项工作的指令集可能无法轻易地保存在任何特定打字员的头脑中。这些都是与 x 轴尺度相关的问题的示例;它根本无法随着数据(无论是指令集还是参考数据)的增加而很好地扩展。如果发送者或接收者的工作有所不同,同样如此。例如,副总裁及以上职位可能会获得特殊格式,或者被允许发送与公司董事不同类型的通信。也许使用特殊的信笺或库存,因发件人而异。也许消息的接收者会导致沟通语气或纸张的变化。例如,帐户拖欠信件可能需要使用笔记中未提及的特殊语气来输入。 As another example, consider again our accounts receivable group. This groupobviously performs a very wide range of tasks from the invoicing of clients to thereceipt of bills, the processing of delinquent accounts, and finally the deposit of fundsinto our bank account(s). The processes for each of these grows as the companygrows and our controller is going to want some specific process controls to exist sothat money doesn’t errantly find its way out of the accounts receivable group andinto one of our employees pockets before payday! This is another place where scalingfor transaction growth alone is not likely to allow us to scale cost effectively into amultibillion dollar company! We will likely need to perform splits based on the ser-vices this group performs and/or the clients or types of clients they serve. These splitsare addressed by the y- and z-axes of our cube, respectively. 作为另一个例子,再次考虑我们的应收账款组。显然,该小组执行的任务范围非常广泛,从为客户开具发票到接收账单、处理拖欠账户,最后将资金存入我们的银行账户。随着公司的发展,每一项的流程也在不断发展,我们的财务总监将希望存在一些特定的流程控制,以便资金不会在发薪日之前错误地从应收账款组中流出并进入我们员工的口袋!这是另一个地方,仅靠交易增长的扩展不太可能让我们以成本有效的方式扩展为数十亿美元的公司!我们可能需要根据该组执行的服务和/或他们服务的客户或客户类型来执行拆分。这些分割分别由立方体的 y 轴和 z 轴解决。 The x-axis split tends to be easy to understand and implement and fairly inexpen-sive in terms of capital and time. Little additional process or training is necessary, andmanagers find it easy to distribute the work. Our people analogy holds true for sys-tems as well, which we will see in Chapters 23 and 24.The x-axis works well whenthe distribution of a high volume of transactions or work is all that we need to do. x 轴分割往往易于理解和实施,并且在资金和时间方面相当便宜。几乎不需要额外的流程或培训,管理人员发现分配工作很容易。我们的人员类比也适用于系统,我们将在第 23 章和第 24 章中看到这一点。当我们只需分配大量交易或工作时,x 轴就很有效。 #####Summarizing the X-Axis 总结 X 轴 The x-axis of the AKF Scale Cube represents the cloning of services or data such that workcan easily be distributed across instances with absolutely no bias. AKF Scale Cube 的 x 轴代表服务或数据的克隆,以便可以轻松地在实例之间分配工作,绝对没有偏见。 X-axis implementations tend to be easy to conceptualize and typically can be implementedat relatively low cost. X 轴的实现往往很容易概念化,并且通常可以以相对较低的成本实现。 X-axis implementations are limited by growth in instructions to accomplish tasks and growthin data necessary to accomplish tasks. X 轴的实现受到完成任务的指令的增长和完成任务所需的数据的增长的限制。 ####The Y-Axis of the Cube 立方体的 Y 轴 The y-axis of the cube of scale represents a separation of work responsibility byeither the type of data, the type of work performed for a transaction, or a combina-tion of both; one way to view these splits is a split by responsibility for an action. Weoften refer to these as service or resource oriented splits. In a y-axis split, the work forany specific action or set of actions, as well as the information and data necessary toperform that action, is split away from other types of actions. This type of split is thefirst split that addresses the monolithic nature of work and the separation of the sameinto either pipelined work flows or parallel processing flows. Whereas the x-axis issimply the distribution of work among several clones, the y-axis represents more ofan industrial revolution for work; we move from a “job shop” mentality to a systemof greater specialization, just as Henry Ford did with his automobile manufacturing.Rather than having 100 people creating 100 unique automobiles, with each persondoing 100% of the tasks, we now have 100 unique individuals performing subtaskssuch as engine installation, painting, windshield installation, and so on. 比例立方体的 y 轴表示按数据类型、为事务执行的工作类型或两者的组合划分的工作责任;查看这些划分的一种方法是按操作的责任进行划分。我们通常将这些称为面向服务或资源的拆分。在 y 轴拆分中,任何特定操作或一组操作的工作以及执行该操作所需的信息和数据都与其他类型的操作分开。这种类型的拆分是第一个解决工作的整体性质并将其分离为管道工作流或并行处理流的拆分。 X 轴只是几个克隆之间的工作分配,而 y 轴则更多地代表了工作的工业革命;我们从“工作车间”心态转向更加专业化的系统,就像亨利?#31119;特在汽车制造方面所做的那样。我们现在拥有 100 个独特的个人,而不是让 100 个人制造 100 辆独特的汽车,每个人完成 100% 的任务执行子任务,例如发动机安装、喷漆、挡风玻璃安装等。 Let’s return to our previous example of a typing service pool. In our x-axis exam-ple, we identified that the total output of our pool might be hampered as the numberand diversity of tasks grew. Specialized information might be necessary based on thetype of typing work performed: an internal memorandum might take on a signifi-cantly different look than a memo meant for external readers, and meeting notesmight vary by the type of meeting, and so on. The vast majority of the work may beletters to clients of a certain format and typed on a specific type of letterhead andbond. When someone is presented with one of the 100 or so formats that only repre-sent about 10% to 20% of the total work, they may stop and have to look up theappropriate format, grab the appropriate letterhead and/or bond, and so on. Oneapproach to this might be to create much smaller pools specializing in some of themore common requests within this 10% to 20% of the total work and a third poolthat handles the small minority of the remainder of the common requests. Both ofthese new service pools could be sized appropriate to the work. 让我们回到之前的打字服务池示例。在我们的 x 轴示例中,我们发现随着任务数量和多样性的增长,池的总输出可能会受到阻碍。根据所执行的打字工作的类型,可能需要专门的信息:内部备忘录的外观可能与供外部读者使用的备忘录明显不同,会议记录可能因会议类型而异,等等。绝大多数工作可能是以某种格式写给客户的,并以特定类型的信头和债券打印。当有人看到 100 种左右的格式中的一种,而这些格式只占总工作的 10% 到 20% 左右时,他们可能会停下来,必须查找适当的格式,抓住适当的信头和/或债券,等等在。一种方法可能是创建更小的池,专门处理总工作的 10% 到 20% 内的一些更常见的请求,并创建第三个池,处理其余常见请求中的一小部分。这两个新服务池的规模都可以适合工作。 The expected benefit of such an approach would be a significant increase in thethroughput of the large pool representing a vast majority of the requests. This poolwould no longer “stall” on a per typist basis based on a unique request. Furthermore,for the next largest pool of typists, some specialization would happen for the nextmost common set of requests, and the output expectations would be the same; forthose sets of requests typists would be familiar with them and capable of handlingthem much more quickly than before. The remaining set of requests that represent amajority of formats but a minority of request volume would be handled by the thirdpool and although throughput would suffer comparatively, it would be isolated to asmaller set of people who might also at least have some degree of specialization andknowledge. The overall benefit should be that throughput should go up significantly.Notice that in creating these pools, we have also created a measure of fault isolationas identified within Chapter 21.Should one pool stall due to paper issues and such,the entire “typing factory” does not come to a halt. 这种方法的预期好处是显着增加代表绝大多数请求的大型池的吞吐量。该池将不再根据每个打字员的独特请求“停滞”。此外,对于下一个最大的打字员池,对于下一个最常见的请求集将会发生一些专业化,并且输出期望将是相同的;对于这些请求,打字员会熟悉它们,并且能够比以前更快地处理它们。代表大多数格式但少数请求量的其余请求集将由第三个池处理,尽管吞吐量会相对受到影响,但它将被隔离到可能至少也具有一定程度的专业知识和知识的一小部分人员。总体好处应该是吞吐量应该显着上升。请注意,在创建这些池时,我们还创建了一种故障隔离措施,如第 21 章中所述。如果一个池由于纸张问题等而停止运行,整个“打字工厂”并没有停止。 It is easy to see how the separation of responsibilities would be performed withinour running example of the accounts receivable department. Each unique actioncould become its own service. Invoicing might be split off into its own team or pool,as might payment receiving/journaling and deposits. We might further split late pay-ments into its own special group that handles collections and bad debt. Each of thesefunctions has a unique set of tasks that require unique data, experience, and instruc-tions or processes. By splitting them, we reduce the amount of information any spe-cific person needs to perform his job, and the resulting specialization should allow usto perform processing faster. The y-axis industrial revolution has saved us! 在我们的应收账款部门运行示例中,很容易看出如何进行职责分离。每个独特的操作都可以成为自己的服务。发票可能会被分成自己的团队或池,付款接收/日记账和存款也可能如此。我们可能会进一步将逾期付款划分为自己的特殊组,负责处理催收和坏账。这些职能中的每一个都有一组独特的任务,需要独特的数据、经验和指令或流程。通过拆分它们,我们减少了任何特定人员执行其工作所需的信息量,由此产生的专业化应该使我们能够更快地执行处理。 Y轴工业革命拯救了我们! Although the benefits of the y-axis are compelling, y-axis splits tend to cost morethan the simpler x-axis splits. The reason for the increase in cost is that very often toperform the y-axis split there needs to be some rework or redesign of process, rules,software, and the supporting data models or information delivery system. Most of usdon’t think about splitting up the responsibilities of our teams or software when weare a three-person company or a Web site running on a single server. Additionally, thesplits themselves create some resource underutilization initially that manifests itself asan initial increase in operational cost. 尽管 y 轴的优点非常引人注目,但 y 轴分割的成本往往比更简单的 x 轴分割的成本更高。成本增加的原因是,为了执行 y 轴分割,通常需要对流程、规则、软件以及支持数据模型或信息交付系统进行一些返工或重新设计。当我们是一个三人公司或一个在单个服务器上运行的网站时,我们大多数人都不会考虑划分团队或软件的职责。此外,拆分本身最初会造成一些资源利用不足,这表现为运营成本的最初增加。 The benefits are numerous, however. Although y-axis splits help with the growthin transactions, they also help to scale what something needs to know to performthose transactions. The data that is being operated upon as well as the instruction setto operate that data decreases, which means that people and systems can be morespecialized, resulting in higher throughput on a per person or per system basis. 然而,好处有很多。虽然 y 轴分割有助于交易的增长,但它们也有助于扩展执行这些交易所需了解的内容。正在操作的数据以及操作该数据的指令集减少,这意味着人和系统可以更加专业化,从而导致每个人或每个系统的吞吐量更高。 #####Summarizing the Y-Axis 总结 Y 轴 The y-axis of the AKF Scale Cube represents separation of work by responsibility, action, ordata. AKF Scale Cube 的 y 轴代表按职责、操作或数据划分的工作。 Y-axis splits are easy to conceptualize but typically come at a slightly higher cost than the x-axis splits. Y 轴分割很容易概念化,但通常比 x 轴分割的成本稍高。 Y-axis splits aid in scaling not only transactions, but instruction size and data necessary toperform any given transaction. Y 轴分割不仅有助于扩展事务,还有助于扩展执行任何给定事务所需的指令大小和数据。 ####The Z-Axis of the Cube 立方体的 Z 轴 The z-axis of the cube is a split biased most often by the requestor or customer. Thebias here is focused on data and actions that are unique to the person or system per-forming the request, or alternatively the person or system for which the request isbeing performed. Z-axis splits may or may not address the monolithic nature ofinstructions, processes, or code, but they very often do address the monolithic natureof the data necessary to perform these instructions, processes, or code. 立方体的 z 轴是请求者或客户最常偏向的分割。这里的偏差集中于执行请求的人或系统、或者正在执行请求的人或系统所特有的数据和操作。 Z 轴分割可能会或可能不会解决指令、过程或代码的整体性质,但它们通常确实解决执行这些指令、过程或代码所需的数据的整体性质。 To perform a z-axis split of our typing service pool, we may look at both the peo-ple who request work and the people to whom the work is being distributed. In ana-lyzing the request work, we can look at segments or classes of groups that mightrequire unique work or represent exceptional work volume. It’s likely the case thatexecutives represent a small portion of our total employee base but also represent amajority or supermajority of the work for internal distribution. Furthermore, thework for these types of individuals might be somewhat unique in that executives areallowed to request more types of work to be performed. Maybe we limit internalmemorandums to executive requests, or personal customer notes might only berequested from an executive. This unique volume of work and type of work might bebest served by a specialist pool of typists. We may also dedicate one or more typiststo the CEO of the company who likely has the greatest number and variety ofrequests. All of these are examples of z-axis splits. 为了对我们的打字服务池进行 z 轴分割,我们可以同时查看请求工作的人员和工作分配给的人员。在分析请求工作时,我们可以查看可能需要独特工作或代表特殊工作量的细分或群体类别。情况很可能是,高管只占我们员工总数的一小部分,但也代表了内部分配工作的大部分或绝大多数。此外,这些类型的个人的工作可能有些独特,因为高管可以要求执行更多类型的工作。也许我们将内部备忘录限制为高管要求,或者个人客户笔记可能只要求高管提供。这种独特的工作量和工作类型可能最好由专业打字员团队来完成。我们还可能为公司的首席执行官指定一名或多名打字员,因为他们的请求可能最多且种类最多。所有这些都是 z 轴分割的示例。 In our accounts receivable department, we might decide that some customersrequire specialized billing, payment terms, and interaction unique to the volume ofbusiness they do with us. We might dedicate a group of our best financial accountrepresentatives and even a special manager to one or more of these customers to han-dle their unique demands. In so doing, we would reduce the amount of knowledgenecessary to perform a vast majority of our billing functions for a majority of ourcustomers while creating account specialists for our most valuable customers. Wewould expect these actions to increase the throughput of our standard accountsgroup as they need not worry about special terms, and the relative throughput forspecial accounts should also go up as these individuals specialize in that area and arefamiliar with the special processes and payment terms. 在我们的应收账款部门,我们可能会认为某些客户需要专门的计费、付款条件以及与我们进行的业务量所特有的交互。我们可能会为其中一个或多个客户指定一组最好的财务客户代表,甚至一名特别经理,以处理他们的独特需求。通过这样做,我们将减少为大多数客户执行绝大多数计费功能所需的知识量,同时为我们最有价值的客户创建帐户专家。我们希望这些行动能够提高标准账户组的吞吐量,因为他们不必担心特殊条款,而且特殊账户的相对吞吐量也应该上升,因为这些人专注于该领域并熟悉特殊流程和付款条件。 Z-axis splits are very often the most costly for companies to implement, but thereturns (especially from a scalability perspective) can be phenomenal. Specializedtraining in the previous examples represent a new cost to the company, and this train-ing is an analog to the specialized set of services one might need to create within asystems platform. Data separation can become costly for some companies, but whenperformed can be amortized over the life of the platform or the system. 对于公司来说,Z 轴拆分通常是成本最高的,但回报(尤其是从可扩展性的角度来看)可能是惊人的。前面示例中的专业培训代表了公司的新成本,这种培训类似于人们可能需要在系统平台内创建的专业服务集。对于某些公司来说,数据分离的成本可能会很高,但如果执行的话,可以在平台或系统的生命周期内摊销。 An additional benefit that z-axis splits create is the ability to separate services bygeography. Want to have your accounts receivable group closer to the accounts theysupport to decrease mail delays? Easy to do! Want your typing pool close to the exec-utives and people they support to limit interoffice mail delivery (remember these arethe days before email)? Also simple to do! z 轴分割带来的另一个好处是能够按地理位置分离服务。想让您的应收帐款组更接近他们支持的帐户以减少邮件延迟吗?容易做!希望您的打字池靠近高管及其支持的人员,以限制办公室间的邮件传递(记住这些是电子邮件出现之前的日子)?做起来也简单! #####Summarizing the Z-Axis Z 轴总结 The z-axis of the AKF Scale Cube represents separation of work by customer or requestor. AKF Scale Cube 的 z 轴代表客户或请求者的工作分离。 As with x- and y-axis splits, the z-axis is easy to conceptualize, but very often is the mostdifficult and costly to implement for companies. 与 x 轴和 y 轴分割一样,z 轴很容易概念化,但对于公司来说实施起来往往是最困难且成本最高的。 Z-axis splits aid in scaling transactions and data and may aid in scaling instruction sets andprocesses if implemented properly. Z 轴分割有助于扩展事务和数据,如果实施得当,还可能有助于扩展指令集和流程。 ####Putting It All Together 把它们放在一起 Why would we ever need more than one, or maybe two, axes of scale within our plat-form or organizations? The answer is that your needs will vary by your current sizeand expected annual growth. If you expect to stay small and grow slowly, you maynever need more than one axis of scale. If you grow quickly, however, or growth isunexpected and violent, you are better off having planned for that growth inadvance. Figure 22.4 depicts our cube, the axes of the cube, and the appropriatelabels for each of the axes. 为什么我们的平台或组织内需要不止一个或两个规模轴?答案是,您的需求将根据您当前的规模和预期的年度增长而有所不同。如果您希望保持规模较小并缓慢增长,那么您可能永远不需要多个尺度轴。然而,如果你成长得很快,或者成长是出乎意料的、猛烈的,那么你最好提前计划好成长。图 22.4 描述了我们的立方体、立方体的轴以及每个轴的适当标签。 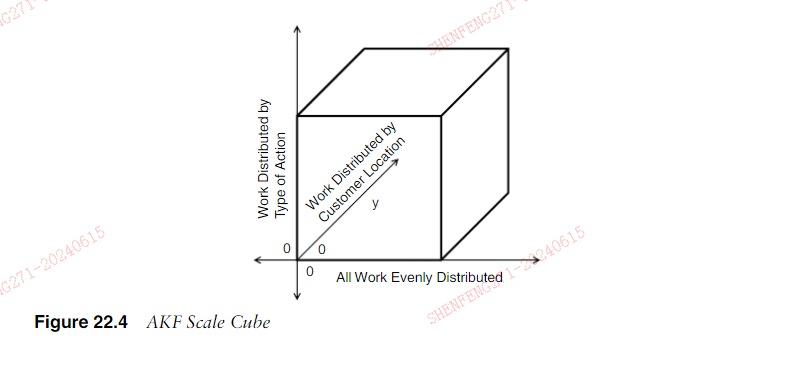 The x-axis of scale is very useful and easy to implement, especially if you havestayed away from creating state within your system or team. You simply clone theactivity among several participants. But scaling along the x-axis starts to fail whenyou have a lot of different tasks requiring significantly different information frommany potential sources. Fast transactions start to run at the speed of slow transac-tions and everything starts to work suboptimally. X 轴尺度非常有用且易于实现,尤其是当您远离在系统或团队内创建状态时。您只需在多个参与者之间克隆活动即可。但是,当您有许多不同的任务需要来自许多潜在来源的显着不同的信息时,沿 x 轴缩放就会开始失败。快速交易开始以慢速交易的速度运行,一切都开始不理想。 #####State Within Applications and the X-Axis 应用程序内的状态和 X 轴 You may recall from Chapter 12 that we briefly defined stateful systems as “those in whichoperations are performed within the context of previous and subsequent operations.” We indi-cated that state very often drives up the cost of the operations of systems as most often thestate (previous and subsequent calls) is maintained within the application or a database asso-ciated with the application. The associated data often drives up memory utilization, storage uti-lization, and potentially database usage and licenses. 您可能还记得第 12 章,我们简要地将有状态系统定义为“在先前和后续操作的上下文中执行操作的系统”。我们指出,状态经常会增加系统操作的成本,因为状态(先前和后续调用)通常是在应用程序或与应用程序关联的数据库中维护的。相关数据通常会提高内存利用率、存储利用率以及潜在的数据库使用和许可证。 Stateless systems often allow us to break affinity between a single user and a single server.Because subsequent requests can go to any server clone, the x-axis becomes even easier toimplement. No affinity between customer and server means that we need not design systemsspecific to any type of customer and so forth. Systems are now free to be more uniform in compo-sition. This topic will be covered in more detail in Chapter 26, Asynchronous Design for Scale. 无状态系统通常允许我们打破单个用户和单个服务器之间的关联性。因为后续请求可以发送到任何服务器克隆,所以 x 轴变得更容易实现。客户和服务器之间没有亲和力意味着我们不需要设计特定于任何类型的客户等的系统。现在系统的组成可以更加统一。第 26 章“规模异步设计”将更详细地介绍该主题。 The y-axis helps to solve that by isolating transaction type and speed to systemsand people specializing in that area of data or service. Slower transactions are nowbunched together, but because the data set has been reduced relative to the X onlyexample, they run faster than they had previously. Fast transactions are also sped upas they are no longer competing with resources for the slower transactions and theirdata set has also been reduced. Monolithic systems are reduced to components thatoperate more efficiently and can scale for data and transaction needs. Y 轴通过将交易类型和速度与专门从事该数据或服务领域的系统和人员隔离来帮助解决这个问题。较慢的事务现在聚集在一起,但由于数据集相对于仅 X 示例已减少,因此它们的运行速度比以前更快。快速事务也得到了加速,因为它们不再与较慢事务的资源竞争,并且它们的数据集也减少了。单体系统被简化为更高效运行的组件,并且可以根据数据和事务需求进行扩展。 The z-axis helps us scale not only transactions and data, but may also help withmonolithic system deconstruction. Furthermore, we can now move teams and sys-tems around geographically and start to gain benefits from this geographic disper-sion, such as disaster recovery. z 轴不仅可以帮助我们扩展交易和数据,还可以帮助我们解构整体系统。此外,我们现在可以在地理位置上移动团队和系统,并开始从这种地理分散中获益,例如灾难恢复。 Looking at our pool of typists, we can separate the types of work that they per-form by the actions. We might create a customer focused team responsible for generalcustomer communication letters, an internal memos team, and team focused onmeeting minutes—all of these are examples of the y-axis. Each team is likely to haveduplication to allow for growth in transactions within that team, which is an exam-ple of x-axis scale. Finally, we might specialize some members of the team relevant tospecific customers or requestors such as an executive group. Although this is a z-axissplit, these teams may also have specialization by task (y-axis) and duplication ofteam members (x-axis). Aha! We’ve put all three axes together. 看看我们的打字员池,我们可以通过操作来区分他们所执行的工作类型。我们可以创建一个以客户为中心的团队,负责一般客户沟通信函、一个内部备忘录团队和专注于会议纪要的团队——所有这些都是 y 轴的示例。每个团队都可能有重复,以允许该团队内交易的增长,这是 x 轴规模的一个例子。最后,我们可能会专门处理与特定客户或请求者相关的团队成员,例如执行小组。尽管这是 z 轴分割,但这些团队也可能按任务(y 轴)进行专业化,并且团队成员重复(x 轴)。啊哈!我们已将所有三个轴放在一起。 For our accounts receivable department we have split them by invoicing, receiving,and deposits, all of which are y-axis splits. Each group has multiple members per-forming the same task, which is an x-axis split. We have created special separation ofthese teams focused on major accounts and recurring delinquent accounts and eachof these specialized teams (a z-axis split) has further splits by function (y-axis) andduplication of individuals (x-axis). 对于我们的应收账款部门,我们按发票、收款和存款进行拆分,所有这些都是 y 轴拆分。每个组都有多个成员执行相同的任务,这是一个 x 轴分割。我们对这些团队进行了专门的划分,重点关注主要客户和经常性拖欠客户,并且每个专业团队(z 轴拆分)都按职能(y 轴)和个人重复(x 轴)进行了进一步拆分。 #####AKF Scale Cube Summary AKF Scale Cube 摘要 Here is a summary of the three axes of scale: 这是三个尺度轴的总结 * The x-axis represents the distribution of the same work or mirroring of data across multi-ple entities. * x 轴表示相同工作或数据镜像在多个实体之间的分布。 * The y-axis represents the distribution and separation of work responsibilities or data meaning among multiple entities. * y轴表示多个实体之间工作职责或数据含义的分配和分离。 * The z-axis represents distribution and segmentation of work by customer, customer need, location, or value. * z 轴表示按客户、客户需求、位置或价值划分的工作分布和细分。 Hence, x-axis splits are mirror images of functions or data, y-axis splits separate data basedon data type or type of work, and z-axis splits separate work by customer, location, or somevalue specific identifier (like a hash or modulus). 因此,x 轴分割是函数或数据的镜像,y 轴根据数据类型或工作类型分割单独的数据,z 轴根据客户、位置或某些值特定标识符(如哈希或模数)分割单独的工作)。 ####When and Where to Use the Cube 何时何地使用立方体 We will discuss the topic of where and when to use the AKF Scale Cube in Chapters23, Splitting Applications for Scale, and 24, Splitting Databases for Scale. That said,the cube is a tool and reference point for nearly any discussion around scalability.You might make a representation of it within your scalability, 10x, or headroommeetings—a process that was discussed in Chapter 11, Determining Headroom forApplications. The AKF Scale Cube should also be presented during ArchitectureReview Board (ARB) meetings, as discussed in Chapter 14, Architecture ReviewBoard, especially if you adopt a principle requiring the design of more than one axisof scale for any major architectural effort. It can serve as a basis for nearly any con-versation around scale as it helps to create a common language among the engineersof an organization. Rather than talking about specific approaches, teams can focuson concepts that might evolve into any number of approaches. 我们将在第 23 章“拆分应用程序以实现规模”和第 24 章“拆分数据库以实现规模”中讨论何时何地使用 AKF Scale Cube 的主题。也就是说,立方体是几乎所有有关可扩展性讨论的工具和参考点。您可以在可扩展性、10 倍或动态余量会议中对其进行表示 - 第 11 章“确定应用程序的动态余量”中讨论了该过程。 AKF Scale Cube 还应在架构审查委员会 (ARB) 会议期间呈现,如第 14 章架构审查委员会中所述,特别是如果您采用一项原则,要求为任何主要架构工作设计多个比例轴。它可以作为几乎任何有关规模的对话的基础,因为它有助于在组织的工程师之间创建通用语言。团队可以专注于可能演变成任意数量的方法的概念,而不是谈论具体的方法。 You may consider requiring footnotes or light documentation indicating the typeof scale for any major design within Joint Architecture Design (JAD) introduced inChapter 13, Joint Architecture Design. The AKF Scale Cube can also come into playduring problem resolution and postmortems in identifying how intended approachesto scale did or did not work as expected and how to fix them in future endeavors. 您可以考虑要求脚注或简单文档来指示第 13 章联合架构设计中介绍的联合架构设计 (JAD) 中任何主要设计的规模类型。 AKF Scale Cube 还可以在问题解决和事后分析过程中发挥作用,以确定预期的扩展方法如何按预期工作或未按预期工作,以及如何在未来的工作中解决这些问题。 The AKF Scale Cube is a tool best worn on your tool belt rather than placed inyour tool box. It should be carried at all times as it is lightweight and can add signif-icant value to you and your team. If referenced repeatedly, it can help to change yourculture from one that focuses on specific fixes and instead discusses approaches andconcepts to help identify the best potential fix. It can switch an organization fromthinking like technicians to acting like engineers. AKF Scale Cube 是一款最好佩戴在工具带上的工具,而不是放在工具箱中。它应该随身携带,因为它重量轻,可以为您和您的团队增加重要价值。如果反复引用,它可以帮助改变您的文化,从专注于特定修复的文化,转而讨论方法和概念,以帮助确定最佳的潜在修复。它可以将组织从像技术人员一样思考转变为像工程师一样行动。 ####Conclusion 结论 This chapter reintroduced the concept of the AKF Scale Cube. Our cube has threeaxes, each of which focused on a different approach toward scalability. Organiza-tional construction was used as an analogy for systems to help better reinforce theapproach of each of the three axes of scale. The cube is constructed such that the ini-tial point (x = 0, y = 0, z = 0) is a monolithic system or organization (single person)performing all tasks with no bias based on the task, customer, or requestor. 本章重新介绍了 AKF Scale Cube 的概念。我们的立方体具有三个轴,每个轴都专注于实现可扩展性的不同方法。组织建设被用作系统的类比,以帮助更好地加强三个尺度轴的方法。立方体的构造使得初始点 (x = 0, y = 0, z = 0) 是一个整体系统或组织(单人),执行所有任务,不存在基于任务、客户或请求者的偏见。 Growth in people or systems performing the same tasks represents an increase inthe x-axis. This axis of scale is easy to implement and typically comes at the lowestcost but suffers when the number of types of tasks or data necessary to perform thosetasks increases. 执行相同任务的人员或系统的增长代表 x 轴的增长。该规模轴很容易实现,并且通常成本最低,但当执行这些任务所需的任务类型或数据数量增加时,就会受到影响。 A separation of responsibilities based on data or the activity being performed isgrowth along the y-axis of our cube. This approach tends to come at a slightly highercost than x-axis growth but also benefits from a reduction in the data necessary toperform a task. Other benefits of such an approach include some fault isolation andan increase in throughput for each of the new pools based on the reduction of data orinstruction set. 基于数据或正在执行的活动的职责分离是沿着立方体的 y 轴增长。这种方法的成本往往比 x 轴增长略高,但也受益于执行任务所需数据的减少。这种方法的其他好处包括一些故障隔离以及基于数据或指令集的减少而增加每个新池的吞吐量。 A separation of responsibility biased on customer or requestor is growth along thez-axis of scale. Such separation may allow for reduction in the instruction set forsome pools and almost always reduces the amount of data necessary to perform atask. The result is that throughput is often increased, as is fault isolation. Cost of z-axis splits tends to be the highest of the three approaches in most organizations,though the return is also huge. The z-axis split also allows for geographic dispersionof responsibility. 偏向客户或请求者的责任分离是沿 z 轴规模的增长。这种分离可以允许减少某些池的指令集,并且几乎总是减少执行任务所需的数据量。结果是吞吐量通常会增加,故障隔离也是如此。在大多数组织中,z 轴拆分的成本往往是三种方法中最高的,尽管回报也很大。 z 轴分割还允许责任的地理分散。 Not all companies need all three axes of scale to survive. Some companies may dojust fine with implementing the x-axis. Extremely high growth companies shouldplan for at least two axes of scale and potentially all three. Remember that planning(or designing) and implementing are two separate functions. 并非所有公司都需要规模的所有三个轴才能生存。有些公司可能在实施 x 轴方面做得很好。极高增长的公司应该至少针对两个规模轴进行规划,甚至可能同时对三个轴进行规划。请记住,规划(或设计)和实施是两个独立的职能。 Ideally the AKF Scale Cube, or a construct of your own design, will become partof your daily toolset. Using such a model helps reduce conflict by focusing on con-cepts and approaches rather than specific implementations. If added to JAD, ARB,and headroom meetings, it helps focus the conversation and discussion on the impor-tant aspects and approaches to growing your technology platform. 理想情况下,AKF Scale Cube 或您自己设计的结构将成为您日常工具集的一部分。使用这样的模型有助于通过关注概念和方法而不是具体实现来减少冲突。如果添加到 JAD、ARB 和净空会议中,它有助于将对话和讨论集中在发展技术平台的重要方面和方法上。 #####Key Points 关键点 * The AKF Scale Cube offers a structured approach and concept to discussing andsolving scale. The results are often superior to a set of rules or implementationbased tools. * AKF Scale Cube 提供了一种结构化的方法和概念来讨论和解决规模问题。结果通常优于一组规则或基于实施的工具。 * The x-axis of the AKF Scale Cube represents the cloning of entities or data andan equal unbiased distribution of work across them. * AKF Scale Cube 的 x 轴代表实体或数据的克隆以及它们之间平等无偏的工作分配。 * The x-axis tends to be the least costly to implement, but suffers from constraintsin instruction size and dataset. * x 轴的实现成本往往最低,但受到指令大小和数据集的限制。 * The y-axis of the AKF Scale Cube represents separation of work biased by activ-ity or data. * AKF Scale Cube 的 y 轴表示受活动或数据影响的工作分离。 * The y-axis tends to be more costly than the x-axis but solves issues related toinstruction size and data set in addition to creating some fault isolation. * y 轴往往比 x 轴成本更高,但除了创建一些故障隔离之外,还解决了与指令大小和数据集相关的问题。 * The z-axis of the AKF Scale Cube represents separation of work biased by therequestor or person for whom the work is being performed. * AKF Scale Cube 的 z 轴代表请求者或工作执行对象所偏向的工作分离。 * The z-axis of the AKF Scale Cube tends to be the most costly to implement butvery often offers the greatest scale. It resolves issues associated with dataset andmay or may not solve instruction set issues. It also allows for global distributionof services. * AKF Scale Cube 的 z 轴往往实施成本最高,但通常提供最大的比例。它解决与数据集相关的问题,并且可能会也可能不会解决指令集问题。它还允许在全球范围内分发服务。 * The AKF Scale Cube can be an everyday tool used to focus scalability relateddiscussions and processes on concepts. These discussions result in approachesand implementations. * AKF Scale Cube 可以作为日常工具,用于将可扩展性相关的讨论和流程集中在概念上。这些讨论产生了方法和实施。 * ARB, JAD, and headroom are all process examples where the AKF Scale Cubemight be useful. * ARB、JAD 和余量都是 AKF Scale Cube 可能有用的过程示例。
没有评论