这篇文章上次修改于 274 天前,可能其部分内容已经发生变化,如有疑问可询问作者。 ### Chapter 12 Exploring Architectural Principles 第12章探索架构原理 > He wins his battles by making no mistakes. Making no mistakes is what establishes the certainty of victory, for itmeans conquering an enemy that is already defeated.—Sun Tzu > 他通过不犯错误来赢得战斗。不犯错误才是胜利的必然,因为这意味着征服已经被击败的敌人。——《孙子》 If your company has been around for awhile, there is a good chance that you havesigns posted about the company and Web pages devoted to things like “core values”or “beliefs.” These are intended to remind people of the desired culture and oftentimes when they resonate with the employees you will see them printed off from thecorporate intranet site and pinned up in cubicles or framed in offices. Sometimes,they are even printed on the back of employee badges as reminders of how the company hopes to operate or as an embodiment of what the corporation holds dear. Wecan’t attest to the effectiveness of such materials, but it certainly “feels” like one ofthose things that you should do and that can only help create and support the culturethe company desires. 如果您的公司已经存在了一段时间,那么您很可能已经张贴了有关该公司的标志和专门介绍“核心价值观”或“信念”等内容的网页。这些旨在提醒人们所期望的文化,并且通常当他们与员工产生共鸣时,您会看到它们从公司内部网站上打印出来并钉在小隔间或装在办公室里。有时,它们甚至被印在员工徽章的背面,以提醒公司希望如何运营或作为公司所珍视的东西的体现。我们无法证明此类材料的有效性,但它确实“感觉”是您应该做的事情之一,并且只能帮助创建和支持公司所需的文化。 In this chapter, we present an analog to these corporate values or beliefs; one thatis inherently more testable and not only can be embodied within framed materialsand Web pages but that can actually help drive and be the heart of your scalabilityinitiatives. We call this analog architectural principles, and they are to your scalability initiatives what core beliefs are to a company’s culture. The primary difference isthat they are also a critical portion of several processes we will discuss later in Chapter 13, Joint Architecture Design, and Chapter 14, Architecture Review Board. Moreover, if implemented properly, they truly become part of your everyday engineeringlife and over the long term can support the culture of scale necessary to be successfulin any hyper-growth company. 在本章中,我们将介绍这些企业价值观或信念的类比;它本质上更具可测试性,不仅可以体现在框架材料和网页中,而且实际上可以帮助推动并成为可扩展性计划的核心。我们称之为模拟架构原则,它们对于您的可扩展性计划来说就像核心信念对于公司文化一样。主要区别在于,它们也是我们稍后将在第 13 章“联合架构设计”和第 14 章“架构审查委员会”中讨论的几个流程的关键部分。此外,如果实施得当,它们将真正成为您日常工程生活的一部分,并且从长远来看,可以支持任何高速增长的公司取得成功所必需的规模文化。 #### Principles and Goals 原则和目标 Let’s review the high-level goal tree we defined in Chapter 5, Management 101, presented in Figure 12.1. 让我们回顾一下我们在第 5 章管理 101 中定义的高级目标树,如图 12.1 所示。 You might recall that the tree indicates two general themes: the creation of moremonetization opportunities and greater revenue at a reduced cost base. These generalthemes were further broken out into thematic leafs such as quality, availability, cost,time to market, and efficiency. Johnny Fixer, the CTO of AllScale, wants to develop aset of principles by which his team will design and implement systems to supportthese overall themes. Recognizing the goals might change, he wants to take his timeand develop principles that will be supportive of increasingly aggressive and potentially ever broadening goals and initiatives. 您可能还记得,该树表明了两个一般主题:创造更多的货币化机会和以降低的成本基础增加收入。这些一般主题进一步细分为质量、可用性、成本、上市时间和效率等主题叶。 AllScale 的首席技术官 Johnny Fixer 希望制定一套原则,他的团队将根据这些原则设计和实施系统来支持这些总体主题。认识到目标可能会发生变化,他希望花时间制定原则,以支持日益激进且可能不断扩大的目标和举措。 In so doing, Johnny decides that he will group the principles thematically to support the goals identified in his goal tree. Further, given the current issues facingAllScale, although he has goals surrounding both time to market and efficiency, hereally wants his teams focusing their architectural efforts on reducing cost, increasingavailability, and increasing scalability. Johnny believes that many of those efforts arelikely to decrease time to market as well, but he believes that the time to market issueis a project management and management issue more than it is an architectural issue. 为此,约翰尼决定按主题对原则进行分组,以支持目标树中确定的目标。此外,考虑到 AllScale 当前面临的问题,尽管他的目标围绕上市时间和效率,但他确实希望他的团队将架构工作重点放在降低成本、提高可用性和可扩展性上。约翰尼认为,其中许多努力也可能会缩短上市时间,但他认为上市时间问题更多的是一个项目管理和管理问题,而不是一个架构问题。 Having developed themes for our architectural principles, Johnny schedules a twoday offsite with his architects, senior engineers, and managers from each of the engineering teams. On day one of the offsite, they begin to brainstorm the set of princi ples that will best enable their teams’ future efforts from a scalability, availability,and cost perspective. As a framework, Johnny starts with the goal tree and explainshis reasoning for selecting cost, scalability, and availability as the goals. Johnny tellsthe team that because he believes some of the principles are likely to affect two ormore of the themes (e.g., cost and scalability or availability and scalability), hedecided to represent the principles in a Venn diagram as depicted in Figure 12.2. 为我们的架构原则制定主题后,约翰尼安排了与他的建筑师、高级工程师和每个工程团队的经理一起进行为期两天的异地活动。在异地的第一天,他们开始集思广益,从可扩展性、可用性和成本的角度思考一套最有利于团队未来工作的原则。作为一个框架,Johnny 从目标树开始,解释了选择成本、可扩展性和可用性作为目标的推理。 Johnny 告诉团队,因为他认为某些原则可能会影响两个或多个主题(例如,成本和可扩展性或可用性和可扩展性),所以他决定用维恩图来表示这些原则,如图 12.2 所示。  Johnny places large depictions of the Venn diagram around the room and breaksthe assembled group of people into teams of three or four individuals. Each team hasrepresentation from software engineering, quality assurance, and at least one of theinfrastructure disciplines. Architects are spread among the teams, but some teams donot have architects. Johnny gives each team several sticky notes on which they are towrite the team’s choices for architectural principles to guide future development. Theteams are then to affix the sticky notes on their own copy of the Venn diagramsplaced around the room. At the end of several hours, each of the teams presents theirVenn diagram for several minutes, each including the reasons for choosing each ofthe principles and for choosing what “theme” they support within the Venn diagram. 约翰尼在房间周围放置了维恩图的大幅描绘,并将聚集的人群分成三到四个人的小组。每个团队都有来自软件工程、质量保证和至少一个基础设施学科的代表。架构师分散在各个团队中,但有些团队没有架构师。 Johnny 给每个团队几张便签,他们要在上面写下团队对架构原则的选择,以指导未来的开发。然后,团队将便签贴在房间周围放置的自己的维恩图副本上。几个小时结束后,每个团队都会用几分钟的时间展示他们的维恩图,每个团队都包括选择每个原则的原因以及选择他们在维恩图中支持的“主题”的原因。 Because Johnny wants the resulting architectural principles to be easily remembered for the maximum opportunity to truly guide behavior, he decides that eachteam can choose no more than twelve principles. Johnny also doesn’t want to spendtime discussing reasons why other themes should be present so he asks that any othercomments be written in a “parking lot,” or whiteboard outside of the team’s areas.Johnny tells the teams that the entire group can discuss other themes for principles atthe end of the meeting and that he is open to adding themes but that he is also absolutely certain that scalability, cost, and availability are the most important themes todiscuss today. 因为 Johnny 希望生成的架构原则易于记住,以便有最大机会真正指导行为,所以他决定每个团队可以选择不超过 12 条原则。约翰尼也不想花时间讨论为什么应该出现其他主题,因此他要求将任何其他评论写在团队区域之外的“停车场”或白板上。约翰尼告诉团队,整个小组可以讨论其他主题在会议结束时讨论原则主题,他愿意添加主题,但他也绝对确定可扩展性、成本和可用性是今天讨论的最重要主题。 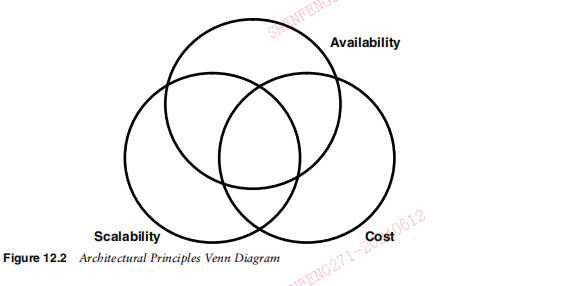 Finally, Johnny reminds the teams that he wants the principles to embody as manyof the SMART characteristics discussed in Chapter 4, Leadership 101, as possible.Although he realizes a principle can’t really be “time bounded” or timely, you dobelieve that principles can be specific, measurable, attainable, and realistic. Most importantly, Johnny really wants them to be “testable” and usable in discussions aroundfuture and current implementations. Johnny does not wish to have any principles thatare so lofty and nebulous that you cannot test a design against the principle. 最后,约翰尼提醒团队,他希望原则尽可能体现第 4 章领导力 101 中讨论的 SMART 特征。尽管他意识到原则不可能真正是“有时间限制的”或及时的,但你确实相信原则可以是具体的、可衡量的、可实现的和现实的。最重要的是,约翰尼真的希望它们是“可测试的”并且可以在围绕未来和当前实现的讨论中使用。约翰尼不希望有任何过于崇高和模糊的原则,以至于你无法根据该原则来测试设计。 something to the effect of “infinitely scalable.” Infinitely scalable is a goal of a groupof principles but on its own isn’t truly measurable, isn’t specific, and can’t be used totest any given design effectively. The principles should be meaningful and easilyapplied in everyday use both to test whether something meets the intended criteriaand to help guide decision making. Instead, Johnny tells them that he hopes for thegoals to be similar to “scale out not up.” In this case, Johnny explains, the principleis easy to test. Something is either designed to run and work on multiple systems atonce or it requires larger and faster hardware as demands grow on the system.Johnny’s team spends the better part of the day broken into smaller teams and thenjoins together at the end of the day for the team presentations. 达到“无限扩展”的效果。无限可扩展是一组原则的目标,但其本身并不是真正可衡量的,不具体,并且不能用于有效测试任何给定的设计。这些原则应该是有意义的并且易于在日常使用中应用,以测试某些东西是否满足预期标准并帮助指导决策。相反,约翰尼告诉他们,他希望目标类似于“横向扩展而不是纵向扩展”。约翰尼解释说,在这种情况下,原理很容易测试。有些东西要么被设计为同时在多个系统上运行和工作,要么随着系统需求的增长而需要更大、更快的硬件。约翰尼的团队将一天中的大部分时间分成较小的团队,然后在一天结束时聚集在一起,以完成任务。团队演示。 ##### Good Principles Are . . . 好的原则是。 。 。 Principles should help influence the behavior and the culture of the team. They should helpguide designs and be capable of being used to determine if designs meet the goals and needsof the company. Ideally, principles are tightly aligned with goals, vision, and mission to be effective. A good principle is 原则应该有助于影响团队的行为和文化。它们应该有助于指导设计并能够用于确定设计是否满足公司的目标和需求。理想情况下,原则与目标、愿景和使命紧密结合,才能发挥作用。一个好的原则是 * Specific. A principle should not be confusing in its wording. * Measurable. Words like “infinitely” (which is not really a measurement) should not beincluded in a principle. * Achievable. Although principles should be inspirational, they should be capable of beingachieved in both design and implementation. * Realistic. The team should have the capabilities of meeting the objective. Some principles are achievable but not without more time or talent than you have. * Testable. A principle should be capable of being used to “test” a design and validate thatit meets the intent of the principle. * 具体的。原则的措辞不应令人困惑。 * 可测量。像“无限”这样的词(这并不是真正的测量)不应包含在原则中。 * 可以实现的。尽管原则应该是鼓舞人心的,但它们应该能够在设计和实施中实现。 * 实际的。团队应该具备实现目标的能力。有些原则是可以实现的,但需要比你更多的时间或才能。 * 可测试。原则应该能够用于“测试”设计并验证其是否满足原则的意图。 Make sure your principles follow the SMART guidelines 确保您的原则遵循 SMART 准则 #### Principle Selection 选型原则 On day two of Johnny’s team offsite, Johnny gives each team an opportunity to refineits principles. Each team then does a short presentation summarizing yesterday’sprinciples presentation and any changes that were made during the morning session.Amazingly, many of the principles start to converge and many of the team’s Venn diagrams start to look alike. 在约翰尼团队异地的第二天,约翰尼给每个团队一个完善其原则的机会。然后,每个团队都会做一个简短的演示,总结昨天的原则演示以及上午会议期间所做的任何更改。令人惊讶的是,许多原则开始趋同,并且团队的许多维恩图开始看起来相似。 In the afternoon session, Johnny mediates a session that starts with identifying andranking the principles based on the number of times they occur in each of the team’spresentations. After the morning session, there are now six common principles that arepresent in each of the team’s presentations, and everyone agrees that these should beadopted outright. There are approximately twenty other principles represented among allof the teams and at least eight of these are present in more than one team’s presentations. 在下午的会议中,约翰尼主持了一场会议,会议首先根据原则在每个团队的演示中出现的次数来识别和排序。上午的会议结束后,团队的每次演讲中都提出了六项共同原则,每个人都同意应该彻底采用这些原则。所有团队都介绍了大约二十项其他原则,其中至少有八项出现在多个团队的演示中。 Johnny writes each of the remaining twenty principles on the whiteboard and askseveryone to come up and vote for exactly six principles, giving the team a total oftwelve. After the votes, Johnny ranks the principles and draws a line after the sixthprinciple on the list. Of the twenty remaining principles, six did not get votes, leavingfourteen with one or more votes. Now Johnny decides to allow debates between thetop ten principles receiving votes and asks representatives for each of the eight principles receiving votes below the six receiving the most votes to come and explain whyone of those should displace the top six. After a few hours of debate, the team votesto accept twelve principles consisting of the six identified within each of the originalpresentations and then another six developed through voting, ranking debating, anda final ranking. Amazingly, the twelve principles look much like the twelve principleswe most often recommend to our clients that we will share with you next. 约翰尼将剩下的 20 条原则逐一写在白板上,并要求每个人都上来投票选出 6 条原则,这样团队的总数就达到了 12 条。投票结束后,约翰尼对原则进行了排名,并在列表中的第六条原则后面划了一条线。在剩下的 20 项原则中,有 6 项没有获得投票,剩下 14 项获得一票或多票。现在,约翰尼决定允许在得票数最高的十项原则之间进行辩论,并要求得票数低于六项原则的代表分别来解释为什么其中一项原则应该取代前六项原则。经过几个小时的辩论,团队投票接受了十二项原则,其中包括每个原始演示文稿中确定的六项原则,然后通过投票、排名辩论和最终排名制定了另外六项原则。令人惊讶的是,这十二项原则看起来很像我们最常向客户推荐的十二项原则,我们接下来将与您分享。 ##### Engendering Ownership of Principles 培养原则主人翁意识 You want the team to “own” the architectural principles that guide your scalability initiatives. Thebest way to do this is to have them intimately involved with the development of the principlesand to mediate the process. A good process to follow in principle development is to 您希望团队“拥有”指导您的可扩展性计划的架构原则。做到这一点的最佳方法是让他们密切参与原则的制定并协调这一过程。原则上遵循的一个好的开发流程是 * Ensure representation from all parties that would apply the principles. * Provide context for the principles by tying them into the vision, mission, and goals of theorganization and the company. Create that causal map to success. * Develop themes or buckets for the principles. Venn diagrams are useful to show overlapof principles within different themes. * Break the larger team into smaller teams to propose principles. Although principles willlikely be worded differently, you will be surprised at how much overlap occurs. * Bring the team together for small presentations and then break them back up into smallerteams to modify their principles. * Perform another round of presentations and then select the overlap of principles. * Place the remaining principles on the wall and allow individuals to vote on them. * Rank order the principles and make the cut line at some easily remembered number ofprinciples (six to twelve) consisting of the overlap from earlier and the next N highestranking principles equaling your preferred number. * Allow debate on the remaining principles and then perform a final rank ordering and askthe team to “ratify” the principles. * 确保适用这些原则的所有各方都有代表。 * 通过将原则与组织和公司的愿景、使命和目标联系起来,为这些原则提供背景。创建成功的因果图。 * 制定原则的主题或范围。维恩图对于显示不同主题内的原则重叠很有用。 * 将较大的团队分成较小的团队来提出原则。尽管原则的措辞可能有所不同,但您会对发生的重叠程度感到惊讶。 * 将团队聚集在一起进行小型演示,然后将他们分成更小的团队来修改他们的原则。 * 进行另一轮演示,然后选择原则的重叠部分。 * 将剩余的原则挂在墙上并允许个人对其进行投票。 * 对原则进行排序,并在一些容易记住的原则数量(6 到 12 个)上划线,其中包括先前的重叠原则和等于您首选数量的下 N 个最高排名原则。 * 允许对其余原则进行辩论,然后执行最终排名排序并要求团队“批准”这些原则。 Be sure to apply RASCI to the process of development as you don’t want the team thinkingthat there isn’t a final decision maker in the process. Failing to include key team members andhaving only architects develop principles may create the perception an “ivory tower” architecture culture wherein engineers do not believe that architects are appropriately connected to theneeds of the clients and architects feel that engineers are not owning and abiding by architectural standards. 请务必将 RASCI 应用到开发过程中,因为您不希望团队认为该过程中没有最终决策者。未能包括关键团队成员并且只有架构师制定原则可能会产生一种“象牙塔”架构文化的感觉,其中工程师不相信架构师与客户的需求有适当的联系,并且架构师认为工程师没有拥有和遵守架构标准。 #### AKF’s Twelve Architectural Principles AKF 的十二个架构原则 In this section, we introduce twelve architectural principles. Many times after engagements, we will “seed” the architectural principle gardens of our clients with ourtwelve principles and then ask them to run their own process, taking as many of oursas they would like, discarding any that do not work for them, and adding as many asthey would like. We only ask that they let us know what they are considering so thatwe can modify our principles over time if they come up with an especially ingeniousor useful principle. The Venn diagram shown in Figure 12.3 depicts our principles asthey relate to scalability, availability, and cost. We will discuss each of the principlesat a high level and then dig more deeply into those that are identified as having animpact on scalability 在本节中,我们介绍十二个架构原则。很多时候,在合作之后,我们会用我们的十二条原则“播种”客户的建筑原则花园,然后要求他们运行自己的流程,采用他们想要的尽可能多的原则,丢弃任何不适合他们的原则,并添加他们想要多少就多少。我们只要求他们让我们知道他们正在考虑什么,以便当他们提出一个特别巧妙或有用的原则时,我们可以随着时间的推移修改我们的原则。图 12.3 所示的维恩图描述了我们与可扩展性、可用性和成本相关的原则。我们将在高层次上讨论每个原则,然后更深入地研究那些被认为对可扩展性有影响的原则 ##### N+1 Design N + 1设计 Simply stated, this principle is the need to ensure that anything you develop has atleast one additional instance of that system in the event of failure. Apply the rule ofthree that we will discuss in Chapter 32, Planning Data Centers, or what we sometimes call ensuring that you build one for you, one for the customer, and one to fail.This principle holds true for everything from large data center design to Web Servicesimplementations. 简而言之,这一原则是需要确保您开发的任何内容在发生故障时至少有一个该系统的附加实例。应用我们将在第 32 章“规划数据中心”中讨论的“三原则”,或者我们有时所说的确保为您构建一个、为客户构建一个、以及一个不会失败的规则。这一原则适用于大型数据中心设计的所有内容到 Web 服务实现。 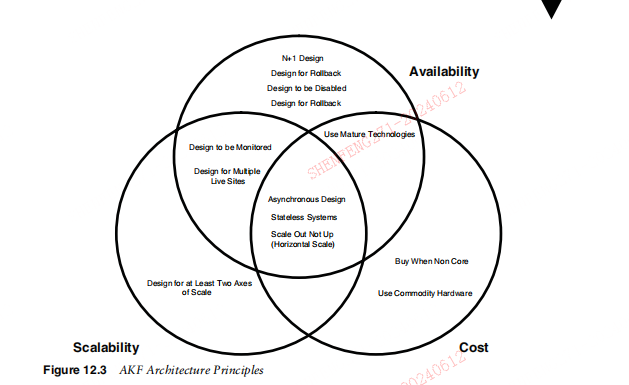 ##### Design for Rollback 回滚设计 This is a critical principle for Web services, Web 2.0, or Software as a Service (SaaS)companies. Whatever you build, ensure that it is backward compatible. Make surethat you can roll it back if you find yourself in a position of spending too much time“fixing forward.” Some companies will indicate that they can roll back within a specific window of time, say the first couple of hours. Unfortunately, some of the worstand most disastrous failures don’t show up for a few days, especially when those failures have to do with customer data corruption. In the ideal case, you will also designto allow something to be rolled, pushed, or deployed while your product or platformis still “live.” The rollback process will be covered in more detail in Chapter 18, Barrier Conditions and Rollback. 对于 Web 服务、Web 2.0 或软件即服务 (SaaS) 公司来说,这是一条重要原则。无论您构建什么,请确保它向后兼容。如果您发现自己花费太多时间“前进”,请确保可以将其回滚。一些公司会表示他们可以在特定的时间范围内回滚,比如前几个小时。不幸的是,一些最严重和最具灾难性的故障几天后才会出现,特别是当这些故障与客户数据损坏有关时。在理想的情况下,您还需要设计允许在您的产品或平台仍然“运行”时滚动、推送或部署某些内容。回滚过程将在第 18 章“障碍条件和回滚”中更详细地介绍。 ##### Design to Be Disabled 设计为禁用 When designing systems, especially very risky systems that communicate to other systems or services, design them to be capable of being “marked down” or disabled.This may give you additional time to “fix forward” or ensure that you don’t go downas a result of a bug that introduces strange out of bounds demand characteristics onyour system. 在设计系统时,尤其是与其他系统或服务通信的风险很大的系统时,请将它们设计为能够“标记”或禁用。这可能会给您额外的时间来“修复”或确保您不会出现故障这是一个错误的结果,该错误在您的系统上引入了奇怪的越界需求特征。 ##### Design to Be Monitored 需要监控的设计 As we’ve discussed earlier in this book, systems should be designed from the groundup to be monitored. This goes beyond just applying agents to a system to monitor theutilization of CPU, memory, or disk I/O. It also goes beyond simply logging errors.You want your system to identify when it is performing differently than it normallyoperates in addition to telling you when it is not functioning properly. 正如我们在本书前面讨论的那样,系统应该从头开始设计以进行监控。这不仅仅是将代理应用到系统来监视 CPU、内存或磁盘 I/O 的使用情况。它也不仅仅是简单地记录错误。除了告诉您系统何时无法正常运行之外,您还希望系统能够识别其运行情况何时与正常运行情况不同。 ##### Design for Multiple Live Sites 多个实时站点的设计 Many companies have disaster recovery centers with systems sitting mostly idle orused for QA until such time as they are needed. The primary issue with such solutions is that it takes a significant amount of time to fail over and validate the disasterrecovery center in the event of a disaster. A better solution is to be serving traffic outof both sites live, such that the team is comfortable with the operation of both sites.Our rule of three applies here as well and in most cases you can operate three siteslive at equal to or lower cost than the operation of a hot site and a cold disasterrecovery site. We’ll discuss this topic in greater detail later in the chapter. 许多公司都有灾难恢复中心,其中的系统大部分闲置或用于质量检查,直到需要它们为止。此类解决方案的主要问题是,在发生灾难时需要大量时间来进行故障转移和验证灾难恢复中心。更好的解决方案是实时提供两个站点的流量,以便团队对这两个站点的运营感到满意。我们的三规则也适用于此,在大多数情况下,您可以以等于或低于以下的成本实时运营三个站点热站点和冷灾难恢复站点的运行。我们将在本章后面更详细地讨论这个主题。 ##### Use Mature Technologies 使用成熟技术 When you are buying technology, use technology that is proven and that has alreadyhad the bugs worked out of it. There are many cases where you might be willing orinterested in the vendor promised competitive edge that some new technology offers.Be careful here, because if you become an early adopter of software or systems, youwill also be on the leading edge of finding all the bugs with that software or system. Ifavailability and reliability are important to you and your customers, try to be anearly majority or late majority adopter of those systems that are critical to the operations of your service, product, or platform. 当您购买技术时,请使用经过验证并且已经解决了错误的技术。在很多情况下,您可能愿意或对供应商承诺的某些新技术提供的竞争优势感兴趣。这里要小心,因为如果您成为软件或系统的早期采用者,您也将处于发现所有错误的领先地位与该软件或系统。如果可用性和可靠性对您和您的客户很重要,请尝试成为那些对您的服务、产品或平台的运营至关重要的系统的早期多数或晚期多数采用者。 ##### Asynchronous Design 异步设计 Whenever possible, systems should communicate in an asynchronous fashion. Asynchronous systems tend to be more fault tolerant to extreme load and do not easily fallprey to the multiplicative effects of failure that characterize synchronous systems. Wewill discuss the reasons for this in greater detail in the next section of this chapter. 只要有可能,系统就应该以异步方式进行通信。异步系统往往对极端负载具有更强的容错能力,并且不容易受到同步系统所特有的故障倍增效应的影响。我们将在本章的下一节中更详细地讨论其原因。 ##### Stateless Systems 无状态系统 Although some systems need state, state has a cost in terms of availability, scalability,and overall cost of your system. When you store state, you do so at a cost of memoryor disk space and maybe the cost of databases. This results in additional calls that areoften made in synchronous fashion, which in turn reduces availability. As state isoften costly compared to stateless systems, it increases the per unit cost of scalingyour site. Try to avoid state whenever possible. 尽管某些系统需要状态,但状态会在系统的可用性、可扩展性和总体成本方面产生成本。当您存储状态时,您会付出内存或磁盘空间的成本,甚至可能还会付出数据库的成本。这会导致通常以同步方式进行额外的调用,从而降低可用性。由于与无状态系统相比,状态通常成本较高,因此它会增加扩展站点的单位成本。尽可能避免状态。 ##### Scale Out Not Up 横向扩展而非向上扩展 This is the principle that addresses the need to scale horizontally rather than vertically. Whenever you base the viability of your business on faster, bigger, and moreexpensive hardware, you define a limit on the growth of your business. That limitmay change with time as larger scalable multiprocessor systems or vendor supporteddistributed systems become available, but you are still implicitly stating that you willgrow governed by third-party technologies. When it comes to ensuring that you canmeet your shareholder needs, design your systems to be able to be horizontally splitin terms of data, transactions, and customers. 这是解决水平而不是垂直缩放需求的原则。每当您将业务的生存能力建立在更快、更大、更昂贵的硬件上时,您就定义了业务增长的限制。随着更大的可扩展多处理器系统或供应商支持的分布式系统的出现,该限制可能会随着时间的推移而改变,但您仍然隐含地声明您将在第三方技术的控制下成长。在确保满足股东需求时,请将系统设计为能够在数据、交易和客户方面进行水平分割。 ##### Design for at Least Two Axes of Scale 至少两个尺度轴的设计 Whenever you design a major system, you should ensure that it is capable of beingsplit on at least two axes of the cube that we introduce in Chapter 22, Introduction tothe AKF Scale Cube, to ensure that you have plenty of room for “surprise” demand.This does not mean that you need to implement those splits on day one, but ratherthat they are thought through and at least architected so that the long lead time ofrearchitecting a system is avoided. 每当您设计一个主要系统时,您应该确保它能够在我们在第 22 章 AKF Scale Cube 简介中介绍的立方体的至少两个轴上进行分割,以确保您有足够的空间来满足“惊喜”需求这并不意味着您需要在第一天就实施这些拆分,而是需要对它们进行深思熟虑并至少对其进行架构设计,以便避免重新架构系统所需的较长准备时间。 ##### Buy When Non Core 非核心时购买 We will discuss this a bit more in Chapter 15, Focus on Core Competencies: BuildVersus Buy. Although we have this identified as a cost initiative, we can make arguments that it affects scalability and availability as well as productivity even thoughproductivity isn’t a theme within our principles. The basic premise is that regardlessof how smart you and your team are, you simply aren’t the best at everything. Furthermore, your shareholders really expect you to focus on the things that really createcompetitive differentiation and therefore shareholder value. So only build thingswhen you are really good at it and it makes a significant difference in your product,platform, or system. 我们将在第 15 章“聚焦核心能力:构建与购买”中对此进行更多讨论。尽管我们将其确定为一项成本计划,但我们可以认为它会影响可扩展性、可用性以及生产力,尽管生产力不是我们原则中的主题。基本前提是,无论你和你的团队多么聪明,你并不是在所有事情上都是最好的。此外,您的股东确实希望您专注于真正创造竞争优势并从而创造股东价值的事情。因此,只有当你真正擅长并且它会对你的产品、平台或系统产生重大影响时才构建东西。 ##### We will discuss this a bit more in Chapter 15, Focus on Core Competencies: BuildVersus Buy. Although we have this identified as a cost initiative, we can make arguments that it affects scalability and availability as well as productivity even thoughproductivity isn’t a theme within our principles. The basic premise is that regardlessof how smart you and your team are, you simply aren’t the best at everything. Furthermore, your shareholders really expect you to focus on the things that really createcompetitive differentiation and therefore shareholder value. So only build thingswhen you are really good at it and it makes a significant difference in your product,platform, or system. 我们将在第 15 章“聚焦核心能力:构建与购买”中对此进行更多讨论。尽管我们将其确定为一项成本计划,但我们可以认为它会影响可扩展性、可用性以及生产力,尽管生产力不是我们原则中的主题。基本前提是,无论你和你的团队多么聪明,你并不是在所有事情上都是最好的。此外,您的股东确实希望您专注于真正创造竞争优势并从而创造股东价值的事情。因此,只有当你真正擅长并且它会对你的产品、平台或系统产生重大影响时才构建东西。 ##### Use Commodity Hardware 使用商品硬件 We often get a lot of pushback on this one, but it fits in well with the rest of the principles we’ve outlined. It is similar to our principle of using mature technologies.Hardware, especially servers, moves at a rapid pace toward commoditization characterized by the market buying predominately based on cost. If you can develop yourarchitecture such that you can scale horizontally easily, you should be buying thecheapest hardware you can get your hands on, assuming that the cost of ownershipof that hardware (including the cost of handling higher failure rates) is lower thanhigher end hardware. 我们经常在这一点上遇到很多阻力,但它与我们概述的其他原则非常吻合。这与我们使用成熟技术的原则类似。硬件,特别是服务器,正在快速走向商品化,市场购买主要基于成本。如果您可以开发能够轻松水平扩展的架构,那么您应该购买您能得到的最便宜的硬件,假设该硬件的拥有成本(包括处理更高故障率的成本)低于高端硬件。 #### Scalability Principles In Depth 深入的可扩展性原则 Now that we’ve had an overview of our suggested principles, let’s dig deeper into theones that we believe support scalability the most. 现在我们已经概述了建议的原则,让我们更深入地研究我们认为最支持可扩展性的原则。 ##### Design to Be Monitored 需要监控的设计 Monitoring, when done well, goes beyond the typical actions of identifying servicesthat are alive or dead, examining or polling log files, collecting system related dataover time, and evaluating end-user response times. When done well, applications andsystems are designed from the ground up to be if not self-healing then at least selfdiagnosing. If a system is designed to be monitored and logs the correct information,you can more easily determine the headroom remaining for the system and take theappropriate action to correct scalability problems earlier. 如果做得好,监控将超越识别服务存活或死亡、检查或轮询日志文件、随着时间的推移收集系统相关数据以及评估最终用户响应时间等典型操作。如果做得好,应用程序和系统从头开始设计,即使不能自我修复,至少也能自我诊断。如果系统设计为受监控并记录正确的信息,您可以更轻松地确定系统剩余的空间,并尽早采取适当的措施纠正可扩展性问题。 For instance, you know at the time of design of any system what services and systems it will need to interact with. Maybe the service in question repeatedly makes useof a database or some other data store. Potentially, the service makes a call, preferably asynchronously, to another service. You also know that from time to time youwill be writing diagnostic information and potentially errors to some sort of volatileor stable storage system. All of this knowledge can be used to design a system that cangive you more information about future scale needs and increase your availability. 例如,您在设计任何系统时就知道它需要与哪些服务和系统进行交互。也许相关服务会反复使用数据库或其他一些数据存储。该服务可能会调用另一个服务(最好是异步调用)。您还知道,您有时会将诊断信息和潜在错误写入某种易失性或稳定的存储系统。所有这些知识都可以用来设计一个系统,为您提供有关未来规模需求的更多信息并提高可用性。 People by their very nature are self diagnosing. In examples where we clearly haveproblems such as running a fever or breaking a leg, we are likely to seek immediatehelp. In the systems world, this would be similar to throwing “hard errors” and crying for help immediately. But how about when we just appear to be working slowerthan before over a period of time? Maybe we feel that we are consistently forgettingmore names, losing our appetite, or taking longer to digest our food. It would be difficult and costly to develop after the fact monitoring agents for such illnesses if wedidn’t subconsciously keep track of such things in our minds. 人们本质上都会进行自我诊断。在我们明显有发烧或摔断腿等问题的例子中,我们可能会立即寻求帮助。在系统世界中,这类似于抛出“硬错误”并立即寻求帮助。但是,当我们在一段时间内似乎工作速度比以前慢时该怎么办?也许我们感觉自己总是忘记更多的名字、失去胃口或者需要更长的时间来消化食物。如果我们不下意识地在脑海中记录这些事情,那么事后开发针对此类疾病的监测剂将是困难且昂贵的。 We argue that you should build systems that help you identify potential or futureissues. Going back to our system and its calls to a database, we should log theresponse time of that database over time, the amount of data, and maybe the rate oferrors. Rather than just reporting on that data, our system could be designed to show“out of bounds” conditions plotted from a mean of the last thirty Tuesdays (assuming today is Tuesday) for our five-minute time of day. Significant standard deviationsfrom the mean could be “alerted” for future or immediate action depending upon thevalue. This approach leverages a control chart from statistical process control. 我们认为您应该构建可以帮助您识别潜在或未来问题的系统。回到我们的系统及其对数据库的调用,我们应该记录该数据库随时间变化的响应时间、数据量,也许还有错误率。我们的系统不仅可以报告这些数据,还可以设计为显示根据过去 30 个星期二(假设今天是星期二)一天中 5 分钟时间的平均值绘制的“越界”条件。与平均值的显着标准偏差可以根据该值“发出警报”,以便将来或立即采取行动。这种方法利用统计过程控制的控制图。 We could do the same with our rates of errors, the response time from other services,and so on. The information could then feed into our capacity planning process tohelp us determine where we might start to have demand versus supply problems suchthat we can know which systems we should focus on for future architectural changes. 我们可以对错误率、其他服务的响应时间等进行同样的处理。然后,这些信息可以输入到我们的容量规划流程中,以帮助我们确定哪里可能开始出现需求与供应问题,以便我们可以知道在未来的架构变更中应该关注哪些系统。 ##### Design for Multiple Live Sites 多个实时站点的设计 As previously indicated, having multiple sites is a must to assure your shareholdersthat you can weather any geographically isolated disaster or crisis. The time to startthinking about how to run data center strategies isn’t when you are attempting todeploy your services, but rather when you are designing them. There are all sorts ofdesign tradeoffs that will impact whether you can easily serve data out of more thanone geographically dispersed data center while you are live. Does your applicationneed or expect that all data will exist in a monolithic database? Does your application expect that all reads and writes will occur within the same database structures?Must all customers reside in the same data structures? Are other services called insynchronous fashion and are they intolerant to latency? 如前所述,必须拥有多个站点,才能向股东保证您能够抵御任何地理上孤立的灾难或危机。开始考虑如何运行数据中心策略的时间不是在尝试部署服务时,而是在设计服务时。各种设计权衡都会影响您是否可以在运行时轻松地从多个地理位置分散的数据中心提供数据。您的应用程序是否需要或期望所有数据都存在于一个整体数据库中?您的应用程序是否期望所有读取和写入都发生在相同的数据库结构中?所有客户都必须驻留在相同的数据结构中吗?其他服务是否被称为异步方式并且它们不能容忍延迟? Ensuring that your system’s designs can be hosted nearly anywhere and operateindependently from other sites if need be is critical to being able to deploy new systems rapidly without the constraints of space or power in a single facility. You mayhave an incredibly scalable application and platform, but if your physical environment and your operating contracts keep you from scaling quickly as demand grows,you are just as handicapped as the company with nearly infinite space and a platformthat needs to be rearchitected for scale. Scalability is about much more than justensuring that the system is designed to allow for scale; it is about ensuring that theenvironment in which you operate, including your contracts, partners, and facilitieswill allow you to scale. Therefore, your architecture must allow you to make use ofseveral facilities (both existing and potentially new facilities) on an on-demand basis. 确保您的系统设计几乎可以在任何地方托管,并在需要时独立于其他站点运行,这对于能够快速部署新系统而不受单个设施空间或电力的限制至关重要。您可能拥有令人难以置信的可扩展应用程序和平台,但如果您的物理环境和运营合同阻止您随着需求的增长而快速扩展,那么您就像拥有近乎无限空间和需要重新架构以实现扩展的平台的公司一样受到限制。可扩展性不仅仅是确保系统的设计考虑到可扩展性;这是为了确保您的运营环境(包括您的合同、合作伙伴和设施)允许您进行扩展。因此,您的架构必须允许您按需使用多个设施(现有的和潜在的新设施)。 ##### Asynchronous Design 异步设计 Systems designed to interact synchronously have a higher failure rate than thosedesigned to act asynchronously. In addition, their ability to scale is tied directly to theslowest system in the chain of communications. If one system or service slows, theentire chain prior to that system slows, and as a result output occurs less frequentlyand throughput is lowered. Thus, synchronous systems are more difficult to scale inreal time. 设计为同步交互的系统比设计为异步操作的系统具有更高的故障率。此外,它们的扩展能力直接与通信链中最慢的系统相关。如果一个系统或服务变慢,则该系统之前的整个链都会变慢,因此输出发生的频率会降低,吞吐量也会降低。因此,同步系统更难以实时扩展。 Asynchronous systems are more tolerant of such slowdowns. Let’s take the casethat a system can serve 40 simultaneous requests synchronously. When all 40requests are in flight, no more can be handled until at least one completes. Asynchronous systems handle the request and do not block for the response. Rather, they havea service that waits for the response while handling the next request. Althoughthroughput is roughly the same, they are more tolerant to slowness as requests cancontinue to be processed. Responses are slowed, but the entire system does not grindto a halt. Thus, if you only have a periodic slowness, it allows you to work throughthat slowness without stopping the entire system. This approach may buy you severaldays in order to “fix” a scale bottleneck as compared to a synchronous system. 异步系统更能容忍这种减速。让我们以一个系统可以同时处理 40 个并发请求的情况为例。当所有 40 个请求都在处理时,只有至少一个请求完成后才能处理更多请求。异步系统处理请求并且不会阻塞响应。相反,他们有一个服务在处理下一个请求时等待响应。尽管吞吐量大致相同,但它们更能容忍缓慢,因为可以继续处理请求。响应速度变慢,但整个系统并没有陷入停滞。因此,如果您只有周期性的缓慢,它可以让您在不停止整个系统的情况下解决该缓慢问题。与同步系统相比,这种方法可能会花费您几天的时间来“修复”规模瓶颈。 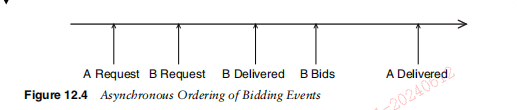 There are many places where you are seemingly “forced” to use a synchronoussystem. For instance, many database calls would be hampered and the results potentially flawed if subjected to an asynchronous passing of messages. Imagine two servers requesting similar data from a database, both of them asking for the current bidprice on a car, as in Figure 12.4. 在很多地方,您似乎“被迫”使用同步系统。例如,如果进行异步消息传递,许多数据库调用将受到阻碍,并且结果可能存在缺陷。想象一下,两台服务器从数据库请求类似的数据,它们都请求汽车的当前出价,如图 12.4 所示。 System A makes a request followed by system B making a request. B receives thedata first and then makes a bid on the car thereby changing the car’s price. A thenreceives data that is out of date. Although this seems undesirable, we can make aminor change to our logic that allows this to happen without significant impact tothe entire process. 系统 A 发出请求,然后系统 B 发出请求。 B 首先收到数据,然后对汽车进行出价,从而改变汽车的价格。然后 A 收到过时的数据。尽管这似乎是不可取的,但我们可以对我们的逻辑进行微小的改变,以允许这种情况发生而不会对整个过程产生重大影响。 We only need to change the case where A subsequently makes a bid. If the bidvalue by A is less than the bid made by B, we simply indicate that the value of the carhas changed and display the now current value. A can then make up her mind as towhether she wants to continue bidding. We have taken something most people wouldargue needs to be synchronous and made it asynchronous. 我们只需改变A随后出价的情况即可。如果 A 的出价小于 B 的出价,我们只需表明该汽车的价值已更改并显示当前价值。然后A可以决定是否继续投标。我们把大多数人认为需要同步的东西变成了异步的。 ##### Stateless Systems 无状态系统 Stateful systems are those in which operations are performed within the context ofprevious and subsequent operations. As such, information on the past operations ofany given thread of execution or series of requests must be maintained somewhere. Inmaintaining state for a series of transactions, engineering teams typically start togather and keep a great deal of information about the requests. State costs money,processing power, availability, and scalability. Although there are many cases wherestate is valuable, it should always be closely evaluated for return on investment. Stateoften implies the need for additional systems and sometimes synchronous calls thatwould not exist in a stateless system. It also makes designing for multiple live datacenters more difficult—how can you possibly handle a transaction with state storedin data center X in data center Y without replicating that state between data centers?The replication of that data would not only need to occur in near real time, implyingthat the data centers need to be relatively close, but it represents a doubling of spacenecessary to store relatively transient data. 有状态系统是在先前和后续操作的上下文中执行操作的系统。因此,有关任何给定执行线程或一系列请求的过去操作的信息必须保存在某处。在维护一系列事务的状态时,工程团队通常会一起开始收集并保留有关请求的大量信息。状态需要金钱、处理能力、可用性和可扩展性。尽管在很多情况下国家是有价值的,但应该始终仔细评估其投资回报。状态通常意味着需要额外的系统,有时还需要同步调用,而这在无状态系统中是不存在的。它还使得针对多个实时数据中心的设计变得更加困难——如何处理状态存储在数据中心 X 和数据中心 Y 中的事务,而不在数据中心之间复制该状态?该数据的复制不仅需要近乎真实地进行时间,这意味着数据中心需要相对靠近,但它意味着存储相对瞬态数据所需的空间加倍。 Whenever possible, stateful applications should be avoided in engineering applications for extreme scale. Where it is necessary, consider attempting to store state withthe end user rather than within your system. If that is not possible, consider a centralized state caching mechanism that keeps state off of the application servers andallows for distribution across multiple servers. Where state needs to be multitenantfor any reason, attempt to segment the state by customer or transaction class to allowdistribution across multiple data centers and try to maintain persistency for that customer or class of transaction within a single data center with only the data that isnecessary for failover being replicated. 只要有可能,在极端规模的工程应用中应避免有状态应用程序。如果有必要,请考虑尝试将状态存储到最终用户而不是系统内。如果这是不可能的,请考虑使用集中式状态缓存机制,该机制使状态远离应用程序服务器并允许跨多个服务器分发。如果出于任何原因需要多租户状态,请尝试按客户或事务类对状态进行分段,以允许跨多个数据中心进行分发,并尝试仅使用故障转移所需的数据在单个数据中心内维护该客户或事务类的持久性被复制。 ##### Scale Out Not Up 横向扩展而非向上扩展 A good portion of this book is about the need to be able to scale horizontally. If youwant to achieve near infinite scale, you must disaggregate your systems, organization,and processes to allow for that scale. Forcing transactions through a single person,computer, or process is a recipe for disaster. Many companies rely upon Moore’s lawfor their scale and as a result continue to force requests into single system (or sometimes two systems to eliminate single points of failures), relying upon faster andfaster systems to scale. Moore’s law isn’t so much a law as it is a prediction that thenumber of transistors that can be placed on an integrated circuit will double roughlyevery two years. The expected result is that the speed and capacity of these transistors(in our case, a CPU and memory) will double within the same time period. But what ifyour company grows faster than this, as did eBay, Yahoo, Google, Facebook, MySpace,and so on? Do you really want to become the company that is limited in growthwhen Moore’s Law no longer holds true?Could Google, Amazon, Yahoo, or eBay run on a single system? Could any ofthem possibly run on a single database? Many of them started out that way, but thetechnology of the day simply could not keep up with the demands that their usersplaced on them. Some of them faced crises of scale associated with attempting to relyupon bigger, faster systems. All of them would have faced those crises had they notstarted to scale out rather than up. 本书的很大一部分内容是关于能够水平扩展的需求。如果您想实现接近无限的规模,您必须分解您的系统、组织和流程以实现这种规模。强制通过单个人、计算机或进程进行交易会导致灾难。许多公司依靠摩尔定律来实现规模化,因此继续将请求强制放入单个系统(有时是两个系统以消除单点故障),依靠越来越快的系统来扩展。摩尔定律与其说是一条定律,不如说它是一个预测,即集成电路上可以放置的晶体管数量大约每两年就会增加一倍。预期结果是这些晶体管(在我们的例子中是 CPU 和内存)的速度和容量将在同一时间段内翻倍。但是,如果您的公司的增长速度比这更快,例如 eBay、雅虎、谷歌、Facebook、MySpace 等,该怎么办?当摩尔定律不再适用时,你真的想成为一家增长有限的公司吗?谷歌、亚马逊、雅虎或易趣可以在单一系统上运行吗?它们中的任何一个都可以在单个数据库上运行吗?他们中的许多人都是这样开始的,但当时的技术根本无法满足用户对他们提出的要求。其中一些公司面临着与试图依赖更大、更快的系统相关的规模危机。如果他们没有开始横向扩展而不是向上扩展,那么所有这些公司都将面临这些危机。 ##### Design for at Least Two Axes of Scale 至少两个尺度轴的设计 Leaders, managers, and architects are paid to think into the future. You are designingnot just for today, but attempting to piece together a system that can be used, withsome modification, for some time to come. As such, we believe that you shouldalways consider how you will perform your next set of horizontal splits even beforethe need arrives. 领导者、管理者和架构师的职责是思考未来。您不仅要为今天而设计,还要尝试拼凑出一个经过一些修改后可以在未来一段时间内使用的系统。因此,我们认为,即使在需求到来之前,您也应该始终考虑如何执行下一组水平分割。 “Scaling out not up” speaks to the implementation of the first set of splits. Perhapsyou are splitting transaction volume across cloned systems. You may have five application servers with five duplicate read only caches consisting of startup informationand nonvolatile customer information. With this configuration, you might be able toscale to 1 million transactions an hour across 1,000 customers and service 100% ofall your transactions from login to logout and everything in between. But what will you do when you have 75 million customers? Will startup times of the applicationsuffer? Will memory access times begin to degrade or can you even keep all of thecustomer information within memory? 横向扩展而不是纵向扩展”谈到了第一组拆分的实施。也许您正在跨克隆系统分配交易量。您可能有五个应用程序服务器,其中有五个重复的只读缓存,其中包含启动信息和非易失性客户信息。通过此配置,您可以将 1,000 个客户的事务扩展到每小时 100 万个事务,并为从登录到注销以及其间所有事务的所有事务提供 100% 的服务。但当您拥有 7500 万客户时您会做什么?应用程序的启动时间会受到影响吗?内存访问时间是否会开始缩短,或者您是否可以将所有客户信息保留在内存中? For any service, you should consider how you will perform your next type of split.In this case, you might divide your customers into N separate groups and service customers out of N separate pools of systems with each pool handling 1/Nth of yourcustomers. Or maybe you move some of the transactions (like login and logout orupdating account information) to separate pools if that will lower the number ofstartup records necessary within the cache. Whatever you do, for major systemsimplementations, you should think about it during the initial design even if you onlyimplement one axis of scale. 对于任何服务,您应该考虑如何执行下一种类型的拆分。在这种情况下,您可以将客户分为 N 个单独的组,并从 N 个单独的系统池中为客户提供服务,每个池处理 1/N 的客户。或者,您可以将某些事务(例如登录和注销或更新帐户信息)移动到单独的池中(如果这会减少缓存中所需的启动记录的数量)。无论你做什么,对于主要的系统实现,即使你只实现一个比例轴,你也应该在初始设计期间考虑它。 ##### Twelve Architectural Principles 十二个架构原则 The twelve principles we most often recommend are 我们最常推荐的十二条原则是 1. N+ 1 Design. Never less than two of anything, and remember the rule of three. 2. Design for Rollback. Ensure you can roll back any release of functionality. 3. Design to Be Disabled. Be able to turn off anything you release. 4. Design to Be Monitored. Think about monitoring during design, not after. 5. Design for Multiple Live Sites. Don’t box yourself into one-site solutions. 6. Use Mature Technologies. Use things you know work well. 7. Asynchronous Design. Communicate synchronously only when absolutely necessary. 8. Stateless Systems. Use state only when the business return justifies it. 9. Scale Out Not Up. Never rely on bigger, faster systems.10. Design for at Least Two Axes. Think one step ahead of your scale needs. 11. Buy When Non Core. If you aren’t the best at building it and it doesn’t offer competitivedifferentiation, buy it. 12. Commodity Hardware. Cheaper is better most of the time. 1. N+ 1设计。任何东西都不能少于两个,并记住“三”的规则。 2。回滚设计。确保您可以回滚任何版本的功能。 3. 设计为禁用。能够关闭你释放的任何东西。 4。需要监控的设计。在设计期间考虑监控,而不是之后。 5。多个实时站点的设计。不要将自己限制在单一站点解决方案中。 6. 使用成熟的技术。使用你知道效果好的东西。 7. 异步设计。仅在绝对必要时才进行同步通信。 8.无状态系统。仅当业务回报证明合理时才使用状态。 9.横向扩展而不是纵向扩展。永远不要依赖更大、更快的系统。 10.至少两个轴的设计。提前考虑您的规模需求。 11. 非核心时购买。如果你不是最擅长构建它并且它不能提供竞争差异化,那就买它。 12。商品硬件。大多数时候越便宜越好。 #### Conclusion 结论 In this chapter, we discussed architectural principles and how they impact the cultureof your organization. Principles should be aligned with the vision, mission, and goalsof your organization. They should be developed with your team to ensure that the team feels ownership over the principles and they should be the foundation for yourscalability focused processes such as the Joint Architecture Design process and theArchitecture Review Board. 在本章中,我们讨论了架构原则以及它们如何影响组织文化。原则应与组织的愿景、使命和目标保持一致。它们应该与您的团队一起开发,以确保团队对原则有所有权,并且它们应该成为以可扩展性为中心的流程的基础,例如联合架构设计流程和架构审查委员会。 ##### Key Points 关键点 * Principles should be developed from your goals and be aligned to your visionand mission. * Principles should be broad enough that they are not continually revised butshould also be SMART and thematically bundled or grouped. * To ensure ownership and acceptance of your principles, consider having yourteam help you develop them. * Ensure that your team understands the RASCI of principle development andmodification. * Keep your principles to a number that is easily memorized by the team to increaseutilization of the principles. We suggest having no more than twelve principles. * 原则应根据您的目标制定,并与您的愿景和使命保持一致。 * 原则应该足够广泛,不会不断修订,但也应该是 SMART 的,并且按主题捆绑或分组。 * 为了确保您的原则的所有权和接受度,请考虑让您的团队帮助您制定这些原则。 * 确保您的团队了解原则开发和修改的 RASCI。 * 将原则保留为团队容易记住的数字,以提高原则的利用率。我们建议原则不超过十二项。
没有评论